1.Spark优势特点1.Spark优势特点
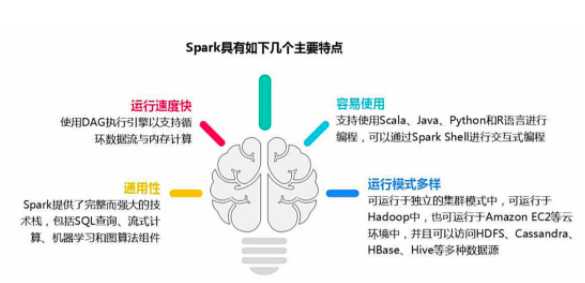
1.1.高效性
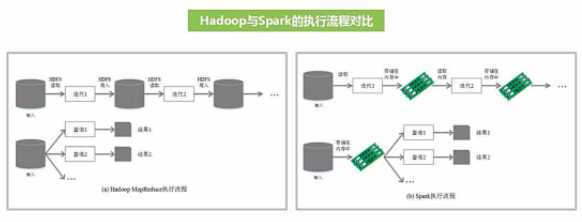
不同于MapReduce将中间计算结果放入磁盘中,Spark采用内存存储中间计算结果,减少了迭代运算的磁盘IO,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间。内存计算下,Spark 比 MapReduce 快100倍。
1.2.易用性
不同于MapReduce仅支持Map和Reduce两种编程算子,Spark提供了超过80种不同的Transformation和Action算子,如map,reduce,filter,groupByKey,sortByKey,foreach等,并且采用函数式编程风格,实现相同的功能需要的代码量极大缩小。

1.3.通用性
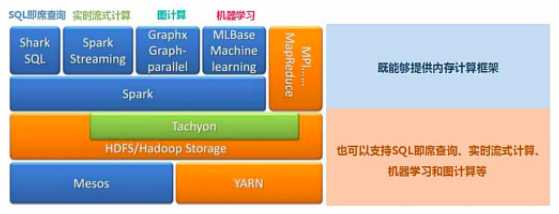
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
这些不同类型的处理都可以在同一个应用中无缝使用。这对于企业应用来说,就可使用一个平台来进行不同的工程实现,减少了人力开发和平台部署成本。
1.4.兼容性
Spark能够跟很多开源工程兼容使用。如Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且Spark可以读取多种数据源,如HDFS、HBase、MySQL等。
2.Spark基本概念
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
-
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系。
-
Driver Program:控制程序,负责为Application构建DAG图。
-
Cluster Manager:集群资源管理中心,负责分配计算资源。
-
Worker Node:工作节点,负责完成具体计算。
-
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task,并为应用程序存储数据。
-
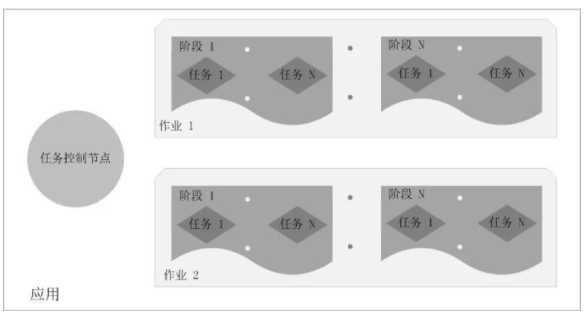
Application:用户编写的Spark应用程序,一个Application包含多个Job。
-
Job:作业,一个Job包含多个RDD及作用于相应RDD上的各种操作。
-
Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
-
Task:任务,运行在Executor上的工作单元,是Executor中的一个线程。
-
总结:Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成。Stage是作业调度的基本单位。
3.Spark架构设计
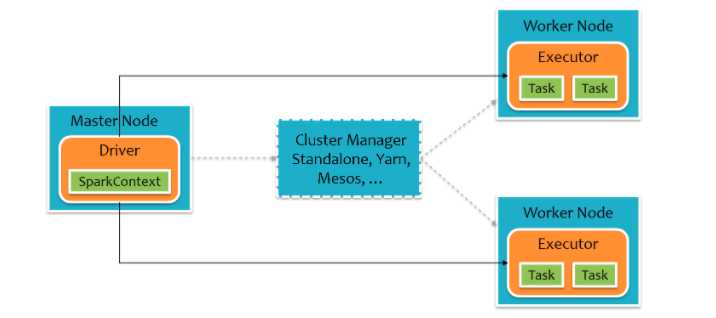
Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node组成。对于每个Spark应用程序,Worker Node上存在一个Executor进程,Executor进程中包括多个Task线程。
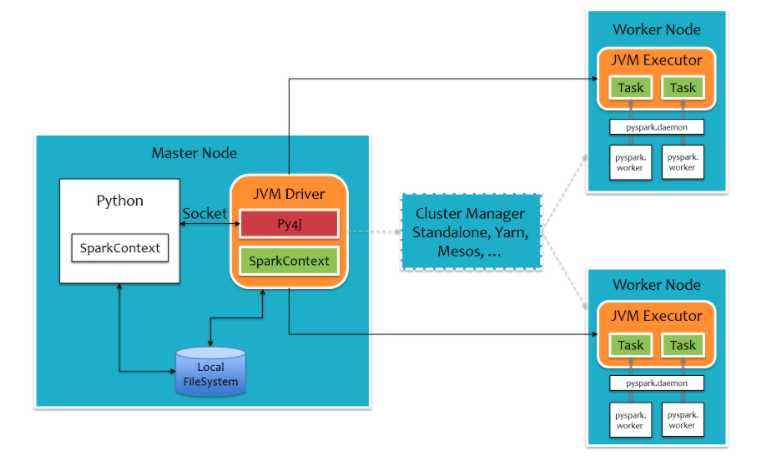
对于pyspark,为了不破坏Spark已有的运行时架构,Spark在外围包装一层Python API。在Driver端,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序。在Executor端,则不需要借助Py4j,因为Executor端运行的Task逻辑是由Driver发过来的,那是序列化后的字节码。
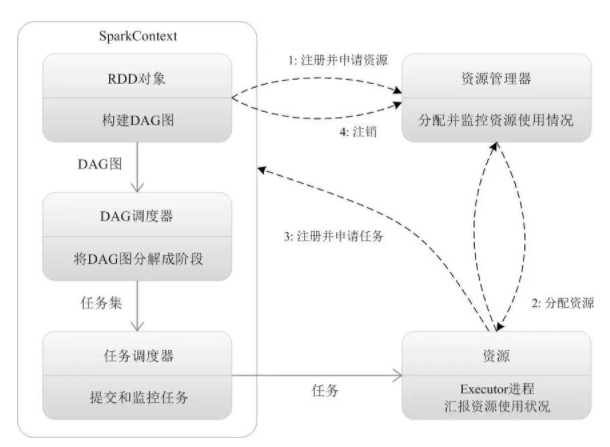
4.Spark运行流程
- Application首先被Driver构建DAG图并分解成Stage。
- 然后Driver向Cluster Manager申请资源。
- Cluster Manager向某些Work Node发送征召信号。
- 被征召的Work Node启动Executor进程响应征召,并向Driver申请任务。
- Driver分配Task给Work Node。
- Executor以Stage为单位执行Task,期间Driver进行监控。
- Driver收到Executor任务完成的信号后向Cluster Manager发送注销信号。
- Cluster Manager向Work Node发送释放资源信号。
- Work Node对应Executor停止运行。

5.Spark部署模式
- Local:本地运行模式,非分布式。
-
Standalone:使用Spark自带集群管理器,部署后只能运行Spark任务。
-
Yarn:Haoop集群管理器,部署后可以同时运行MapReduce,Spark,Storm,Hbase等各种任务。
-
Mesos:与Yarn最大的不同是Mesos 的资源分配是二次的,Mesos负责分配一次,计算框架可以选择接受或者拒绝。
6.RDD数据结构
RDD全称Resilient Distributed Dataset,弹性分布式数据集,它是记录的只读分区集合,是Spark的基本数据结构。
RDD代表一个不可变、可分区、里面的元素可并行计算的集合。
一般有两种方式创建RDD,第一种是读取文件中的数据生成RDD,第二种则是通过将内存中的对象并行化得到RDD。
#通过读取文件生成RDD
rdd = sc.textFile("hdfs://hans/data_warehouse/test/data")
#通过将内存中的对象并行化得到RDD
arr = [1,2,3,4,5]
rdd = sc.parallelize(arr)
创建RDD之后,可以使用各种操作对RDD进行编程。
RDD的操作有两种类型,即Transformation操作和Action操作。转换操作是从已经存在的RDD创建一个新的RDD,而行动操作是在RDD上进行计算后返回结果到 Driver。
Transformation操作都具有 Lazy 特性,即 Spark 不会立刻进行实际的计算,只会记录执行的轨迹,只有触发Action操作的时候,它才会根据 DAG 图真正执行。
操作确定了RDD之间的依赖关系。
RDD之间的依赖关系有两种类型,即窄依赖和宽依赖。窄依赖时,父RDD的分区和子RDD的分区的关系是一对一或者多对一的关系。而宽依赖时,父RDD的分区和自RDD的分区是一对多或者多对多的关系。
宽依赖关系相关的操作一般具有shuffle过程,即通过一个Patitioner函数将父RDD中每个分区上key不同的记录分发到不同的子RDD分区。
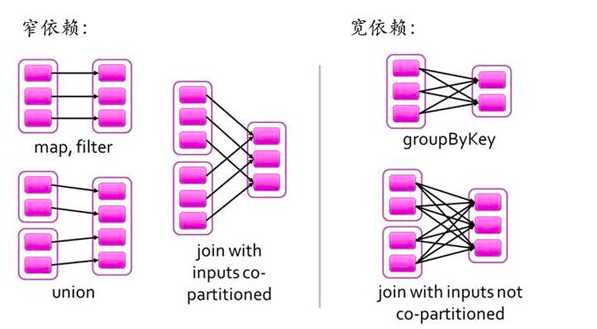
依赖关系确定了DAG切分成Stage的方式。
切割规则:从后往前,遇到宽依赖就切割Stage。
RDD之间的依赖关系形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分成相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
7.WordCount范例
import findspark
#指定spark_home为刚才的解压路径,指定python路径
spark_home = "/opt/spark/spark-3.4.4-bin-hadoop3"
python_path = "/usr/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
只需要5行代码就可以完成WordCount词频统计。
rdd_line = sc.textFile("./data/hello.txt")
rdd_word = rdd_line.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda t:(t,1))
rdd_count = rdd_one.reduceByKey(lambda x,y:x+y)
rdd_count.collect()
[('world', 1),
('love', 3),
('jupyter', 1),
('pandas', 1),
('hello', 2),
('spark', 4),
('sql', 1)]
8.学习笔记
让 Python 找到 Spark → 初始化 PySpark 运行环境 → 创建一个本地 SparkContext(4 个线程)
这是不通过 spark-submit,直接在 Python / Jupyter 里用 Spark 的典型写法。
8.1.import findspark
findspark 是做什么的?
- PySpark 本质上依赖 Java Spark
-
Python 默认 不知道 Spark 安装在哪里
-
findspark 的作用是:
把 SPARK_HOME
把 PySpark 相关路径
动态加到 sys.path
📌 适合在:
- Jupyter Notebook
-
普通 Python 脚本
-
非 spark-submit 场景
8.2.指定 Spark 和 Python 路径
spark_home = "/opt/spark/spark-3.4.4-bin-hadoop3"
python_path = "/usr/bin/python"
spark_home
- 指向 Spark 的解压目录
-
里面应包含:
bin/
jars/
python/
例如:
spark-3.4.4-bin-hadoop3/
├── bin
├── jars
├── python
python_path
- 明确指定 PySpark 使用哪个 Python
-
这点很重要:
避免 Spark 用系统 Python
和你当前 Conda / venv 一致
8.3.初始化 findspark
findspark.init(spark_home, python_path)
它内部做了几件事:
设置环境变量:
SPARK_HOME = spark_home
PYSPARK_PYTHON = python_path
把以下路径加入 Python 搜索路径:
$SPARK_HOME/python
$SPARK_HOME/python/lib/py4j-*.zip
8.4.导入 PySpark 模块
import pyspark
from pyspark import SparkContext, SparkConf
- pyspark:PySpark 总模块
-
SparkConf:Spark 配置对象
-
SparkContext:Spark 程序的入口
8.5.创建 Spark 配置
conf = SparkConf().setAppName("test").setMaster("local[4]")
setAppName(“test”)
- Spark 应用名
-
会显示在:
Spark UI
日志
setMaster(“local[4]”)
表示:
| 配置 | 含义 |
|---|---|
local |
本机运行 |
[4] |
使用 4 个 CPU 线程 |
📌 等价解释:
用你电脑上的 4 个核心模拟一个 Spark 集群
常见写法:
- local[*] → 用所有核心
-
local[2] → 用 2 个线程
8.6.创建 SparkContext(真正启动 Spark)
sc = SparkContext(conf=conf)
启动 JVM
✅ 启动 Spark Driver
✅ 建立 Python ↔ Java 通信(Py4J)
✅ Spark 正式可用
此时:
Spark UI 默认在:
http://localhost:4040
整个 Spark 程序只能有一个 SparkContext
8.7.现在还推荐用 SparkContext 吗?
不推荐(Spark 2.x 以后)
更推荐用:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("test") \
.master("local[4]") \
.getOrCreate()
spark.sparkContext 就是 sc
Spark 2.0 之后的设计变化
以前(Spark 1.x):
SparkContext → RDD
SQLContext → DataFrame
HiveContext → Hive
现在(Spark 2.x+):
SparkSession(统一入口)
├── sparkContext
├── read / write
├── sql()
└── catalog
SparkSession = Spark 程序的唯一入口
8.8.什么时候需要 findspark?
| 场景 | 是否需要 |
|---|---|
| Jupyter / 普通 Python | ✅ 需要 |
| spark-submit | ❌ 不需要 |
| 已配置 SPARK_HOME | ❌ 可不需要 |
8.9.SparkSession 现代写法
import findspark
# 1. 指定 Spark 和 Python 路径
spark_home = "/opt/spark/spark-3.4.4-bin-hadoop3"
python_path = "/usr/bin/python"
# 2. 初始化 Spark 环境
findspark.init(spark_home, python_path)
# 3. 使用 SparkSession(现代写法)
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("test") \
.master("local[4]") \
.getOrCreate()
# 4. 如需 SparkContext(可选)
sc = spark.sparkContext
| 配置 | 说明 |
|---|---|
appName("test") |
应用名 |
master("local[4]") |
本地 4 线程 |
getOrCreate() |
已存在则复用,否则新建 |
getOrCreate() 很重要:
- 防止重复创建 SparkContext
-
在 Jupyter 里尤其必要
spark.sparkContext
- 如果你还要用 RDD API
-
否则可以 完全不写这行
对比:旧写法 vs 新写法
| 项目 | 旧写法 | 新写法 |
|---|---|---|
| 入口 | SparkContext | SparkSession |
| SQL | SQLContext | spark.sql |
| DataFrame | SQLContext | spark.read |
| 推荐程度 | ❌ 不推荐 | ✅ 推荐 |
8.10.WordCount(词频统计)示例解释
从文本文件中读取内容 → 按空格切词 → 每个词记为 1 → 按词聚合求和 → 得到每个词出现的次数
rdd_line = sc.textFile("./data/hello.txt")
- 读取文本文件
- 一行 = RDD 中的一个元素
假设 hello.txt 内容是:
hello spark hello
hello world
那么:
rdd_line = [
"hello spark hello",
"hello world"
]
- textFile 是 懒执行
-
此时 没有真正读取文件
按空格拆分成单词
rdd_word = rdd_line.flatMap(lambda x: x.split(" "))
为什么用 flatMap?
map 会生成「列表的列表」
flatMap 会 拍平(flatten)结果
对第一行:
"hello spark hello" → ["hello", "spark", "hello"]
结果变成:
“`rdd_word = [
"hello", "spark", "hello",
"hello", "world"
]
<pre><code class="line-numbers">flatMap 是 一对多转换
每个单词映射成 (word, 1)
</code></pre>
rdd_one = rdd_word.map(lambda t: (t, 1))
<pre><code class="line-numbers">变成键值对(Key-Value):
</code></pre>
rdd_one = [
("hello", 1),
("spark", 1),
("hello", 1),
("hello", 1),
("world", 1)
]
<pre><code class="line-numbers">这是 reduceByKey 的前置条件
按单词分组并累加
</code></pre>
rdd_count = rdd_one.reduceByKey(lambda x, y: x + y)
<pre><code class="line-numbers">Spark 内部做了:
– 按 key 分组
– 对同一个 key 的 value 执行 x + y
等价逻辑:
</code></pre>
"hello": 1 + 1 + 1 = 3
"spark": 1
"world": 1
<pre><code class="line-numbers">结果:
</code></pre>
rdd_count = [
("hello", 3),
("spark", 1),
("world", 1)
]
<pre><code class="line-numbers">reduceByKey 是:
1. 宽依赖
3. 会触发 Shuffle(网络传输)
触发执行并返回结果
</code></pre>
rdd_count.collect()
<pre><code class="line-numbers">collect() 做了什么?
– 把 所有结果拉回 Driver
– 真正触发整个计算 DAG
⚠️ 注意:
– 数据大时 不能用 collect
– 仅适合教学 / 小数据
完整的数据流图
</code></pre>
textFile
↓
["hello spark hello", "hello world"]
↓ flatMap
["hello", "spark", "hello", "hello", "world"]
↓ map
[("hello",1),("spark",1),("hello",1),("hello",1),("world",1)]
↓ reduceByKey
[("hello",3),("spark",1),("world",1)]
↓ collect
Driver
<pre><code class="line-numbers">Spark 背后发生了什么?
1. 懒执行(Lazy Evaluation)
textFile / map / flatMap / reduceByKey
都不执行
直到 collect() 才真正运行
2. DAG & Stage
textFile → flatMap → map
→ Stage 1(窄依赖)
reduceByKey
→ Stage 2(Shuffle)
3. 并行执行
假设:
</code></pre>
master = local[4]
<pre><code class="line-numbers">- 最多 4 个 Task 并行
– 每个分区一个 Task
为什么不用 groupByKey?
</code></pre>
rdd_one.groupByKey().mapValues(sum)
<pre><code class="line-numbers">原因:
– groupByKey 会把所有 value 拉到内存
– 性能差、容易 OOM
如果想排序?
</code></pre>
rdd_count.sortBy(lambda x: x[1], ascending=False).collect()
<pre><code class="line-numbers">DataFrame 写法
</code></pre>
spark.read.text("./data/hello.txt") \
.selectExpr("explode(split(value,' ')) as word") \
.groupBy("word") \
.count()
<pre><code class="line-numbers">“x 和 y 到底是谁?为什么能一直加?”
</code></pre>
rdd_count = rdd_one.reduceByKey(lambda x, y: x + y)
<pre><code class="line-numbers">对“同一个 key”的所有 value,两两相加,直到只剩一个结果
先看 rdd_one 到底长什么样
假设文件内容是:
</code></pre>
hello spark hello
hello world
<pre><code class="line-numbers">那么:
</code></pre>
rdd_one = [
("hello", 1),
("spark", 1),
("hello", 1),
("hello", 1),
("world", 1)
]
<pre><code class="line-numbers">现在 Spark 会先按 key 分组(逻辑上):
</code></pre>
hello → [1, 1, 1]
spark → [1]
world → [1]
<pre><code class="line-numbers">这一步是概念上的理解,Spark 并不会真的生成这个列表(那样太慢)。
lambda x, y: x + y 到底怎么用?
以 "hello" 为例
</code></pre>
hello → [1, 1, 1]
<pre><code class="line-numbers">Spark 内部会这样做(顺序不保证,但逻辑一致):
第一次
</code></pre>
x = 1
y = 1
x + y = 2
<pre><code class="line-numbers">第二次
</code></pre>
x = 2
y = 1
x + y = 3
<pre><code class="line-numbers">最终结果:
</code></pre>
("hello", 3)
<pre><code class="line-numbers">👉 x 永远是“之前算出来的结果”
👉 y 是“新拿到的一个 value”
为什么是 x 和 y,不是 t 或别的?
因为 reduce 的定义就是:
每次拿两个同类型的值,合并成一个同类型的值
– 输入:(value, value)
– 输出:value
这里的 value 是 int
所以:
</code></pre>
(int, int) → int
<pre><code class="line-numbers">为什么叫 reduceByKey?
拆开看就明白了:
| 部分 | 含义 |
| —— | ———– |
| reduce | 把多个值“缩减”为一个 |
| by key | 按 key 分开来做 |
等价伪代码(你脑子里可以这样想):
</code></pre>
for key in keys:
result = values[0]
for v in values[1:]:
result = result + v
<pre><code class="line-numbers">再看几个常见例子
求最大值
</code></pre>
reduceByKey(lambda x, y: max(x, y))
<pre><code class="line-numbers">拼字符串
</code></pre>
("a", "b", "c") → "abc"
reduceByKey(lambda x, y: x + y)
<pre><code class="line-numbers">和 groupByKey 的关键区别
groupByKey(慢、占内存)
</code></pre>
("hello", [1,1,1]) → sum
<pre><code class="line-numbers">reduceByKey(边算边合)
</code></pre>
1 + 1 → 2
2 + 1 → 3
<pre><code class="line-numbers">👉 reduceByKey 在 Shuffle 前就做了局部合并(Combiner)
##### 8.11.什么时候 Spark UI 会启动?
只要 Spark 应用在运行,Spark UI 就会自动启动
你不需要额外“启动命令”。
👉 前提:SparkContext / SparkSession 已经创建
例如你已经有:
</code></pre>
spark = SparkSession.builder \
.appName("test") \
.master("local[4]") \
.getOrCreate()
<pre><code class="line-numbers">这行代码一执行,Spark UI 就已经起来了。
##### 8.12.如何查看 Spark UI(本地模式)
✅ 1️⃣ 默认访问地址
在浏览器里打开:
</code></pre>
http://localhost:4040
<pre><code class="line-numbers">如果 4040 打不开怎么办?
Spark 会自动换端口:
| 应用序号 | 端口 |
| —- | —- |
| 第一个 | 4040 |
| 第二个 | 4041 |
| 第三个 | 4042 |
一个最小可复现示例
</code></pre>
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("UI-test") \
.master("local[4]") \
.getOrCreate()
sc = spark.sparkContext
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
print(rdd.map(lambda x: x * 2).collect())
print("Spark UI 已启动,浏览器打开 http://localhost:404? ?请查看提示信息")
input("按回车键结束程序…")
<h1>⚠️ 如果程序直接结束,Spark UI 也会立刻消失</h1>
<h1>所以要 让程序“停住”一会儿</h1>
spark.stop()
<pre><code class="line-numbers">防火墙:
</code></pre>
<h1>Add port 4040 (and a small range for when Spark uses 4041, 4042, etc.)</h1>
sudo firewall-cmd –permanent –zone=public –add-port=4040-4050/tcp
<h1>Reload to apply immediately</h1>
sudo firewall-cmd –reload
<pre><code class="line-numbers">启动命令:
</code></pre>
spark-submit –master local[4] app.py
“`
8.13.Spark UI 里有什么?
打开 UI 后,你会看到几个 Tab
1️⃣ Jobs(最重要)
- 每一个 Action(collect / count / save) = 一个 Job
-
你可以看到:
Job 状态
执行时间
成功 / 失败
👉 点进去可以看到 Stage 级别细节
2️⃣ Stages(理解 Shuffle 的关键)
- 每个 Stage = 一组 Task
-
是否有 Shuffle 一目了然
-
WordCount 中:
map / flatMap → Stage 0
reduceByKey → Stage 1(Shuffle)
3️⃣ Tasks(性能分析)
- 每个 Task 的运行时间
-
哪个 Task 慢
-
是否数据倾斜
4️⃣ Storage(缓存相关)
- 哪些 RDD / DataFrame 被缓存
-
内存使用情况
5️⃣ Environment(环境)
-
Spark 配置
-
Java / Python 版本
-
Executor 信息