PostgreSQL page结构
1.Page简介
PG中的page和Oracle中的数据块一样,指的是数据库的块,操作系统块的整数倍个,默认是8K也就是两个操作系统块(4k的文件系统块)。这个大小在PG编译安装configure的时候通过–with-blocksize参数指定,单位是Kb。此后都不可更改,因为许多PG内存结构设计都是以此为基础的。
page是磁盘存储和内存中的最小管理单位都是。
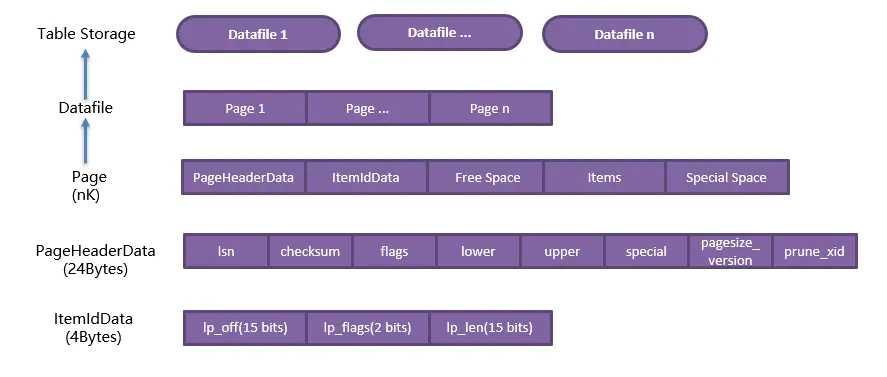
1.1.PG数据表存储
如下图所示,数据表中的数据存储在N个数据文件中,每个数据文件有N个Page(大小默认为8K,可在编译安装时指定)组成。Page为PG的最小存取单元。
2.Page的内部结构
2.1.Page结构图
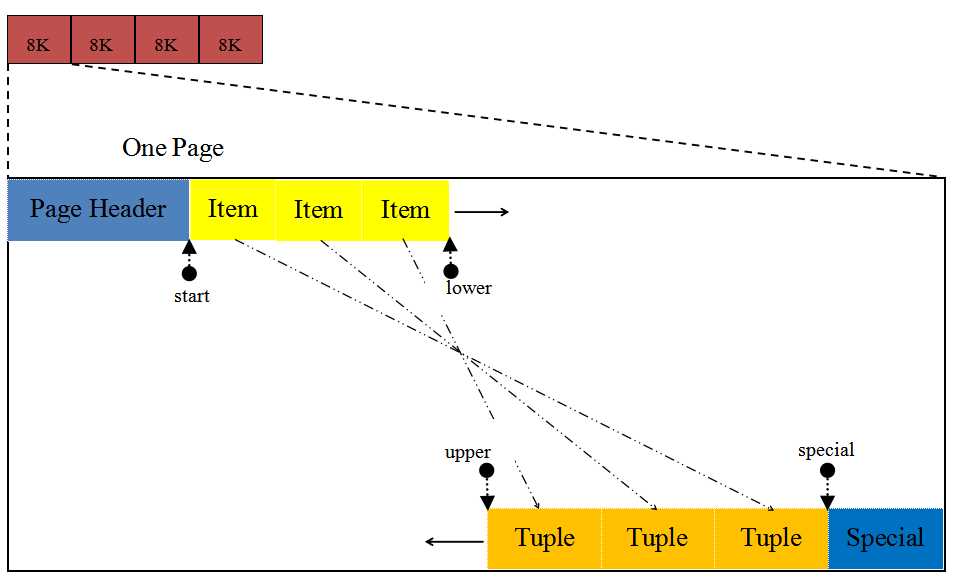
在一个page中,表的记录是从page的底部开始存储,然后慢慢向上涨。Page结构图如下:
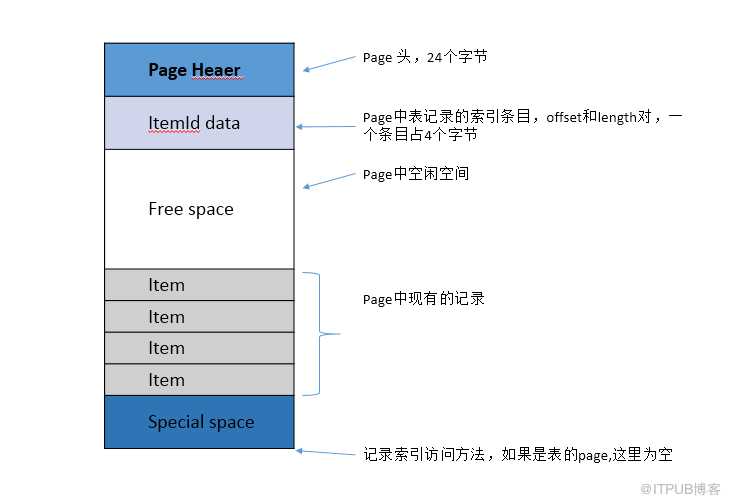
- Page Header:页头,存储LSN,page中空闲空间的开始offset和结束offset等,占用24Bytes。
- ItemIdData:数据指针数组存储指向实际数据的指针,一个Item为4个字节,由三部分组成:前15位为Page内偏移,中间2位为标志,后面15位为长度。数组中的元素ItemId可理解为相应数据行在Page中的实际开始偏移。
- Free space:空闲空间为未使用可分配的空间,不算标记为delete后的空间;是指完全没有被使用的空间,也相当于page中没有被分配的空间。
- Item:表实际存储的记录。
- Special space: 存储索引访问方法(AM: Access Method)信息,不同的索引访问方法,内容不一样。但如果是表的page,那么这里是空的,没有任何信息。
页面布局示意图
2.2.PageHeader源码
PageHeader 定义,源码如下:
头文件:src/include/storage/bufpage.h
/*
* For historical reasons, the 64-bit LSN value is stored as two 32-bit
* values.
*/
typedef struct
{
uint32 xlogid; /* high bits */
uint32 xrecoff; /* low bits */
} PageXLogRecPtr;
#define PageXLogRecPtrGet(val) \
((uint64) (val).xlogid << 32 | (val).xrecoff)
#define PageXLogRecPtrSet(ptr, lsn) \
((ptr).xlogid = (uint32) ((lsn) >> 32), (ptr).xrecoff = (uint32) (lsn))
/*
* disk page organization
*
* space management information generic to any page
*
* pd_lsn - identifies xlog record for last change to this page.
* pd_checksum - page checksum, if set.
* pd_flags - flag bits.
* pd_lower - offset to start of free space.
* pd_upper - offset to end of free space.
* pd_special - offset to start of special space.
* pd_pagesize_version - size in bytes and page layout version number.
* pd_prune_xid - oldest XID among potentially prunable tuples on page.
*
* The LSN is used by the buffer manager to enforce the basic rule of WAL:
* "thou shalt write xlog before data". A dirty buffer cannot be dumped
* to disk until xlog has been flushed at least as far as the page's LSN.
*
* pd_checksum stores the page checksum, if it has been set for this page;
* zero is a valid value for a checksum. If a checksum is not in use then
* we leave the field unset. This will typically mean the field is zero
* though non-zero values may also be present if databases have been
* pg_upgraded from releases prior to 9.3, when the same byte offset was
* used to store the current timelineid when the page was last updated.
* Note that there is no indication on a page as to whether the checksum
* is valid or not, a deliberate design choice which avoids the problem
* of relying on the page contents to decide whether to verify it. Hence
* there are no flag bits relating to checksums.
*
* pd_prune_xid is a hint field that helps determine whether pruning will be
* useful. It is currently unused in index pages.
*
* The page version number and page size are packed together into a single
* uint16 field. This is for historical reasons: before PostgreSQL 7.3,
* there was no concept of a page version number, and doing it this way
* lets us pretend that pre-7.3 databases have page version number zero.
* We constrain page sizes to be multiples of 256, leaving the low eight
* bits available for a version number.
*
* Minimum possible page size is perhaps 64B to fit page header, opaque space
* and a minimal tuple; of course, in reality you want it much bigger, so
* the constraint on pagesize mod 256 is not an important restriction.
* On the high end, we can only support pages up to 32KB because lp_off/lp_len
* are 15 bits.
*/
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
/*
日志文件信息,保存了该页面最后一次被修改的操作对应到确切的日志文件
位置,包括了日志文件ID和日志文件偏移量
*/
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page 8 bytes*/
uint16 pd_checksum; /* checksum 2 bytes*/
uint16 pd_flags; /* flag bits, see below 用来表示页面状态 2 bytes*/
LocationIndex pd_lower; /* offset to start of free space 空闲空间起始位置 2 bytes*/
LocationIndex pd_upper; /* offset to end of free space 空闲空间结束位置 2 bytes*/
LocationIndex pd_special; /* offset to start of special space
* 特殊用途空间的起始位置,结束位置是page尾部,直到页面结束*/
uint16 pd_pagesize_version; /* 2 bytes */
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none 4 bytes */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array 数据开始位置*/
} PageHeaderData;
typedef PageHeaderData *PageHeader;
Page Header 24个字节说明:

header用来保存该page相关的数据:
- pd_lsn pd_tli 记录日志相关的信息
pd_lsn是指最后修改过这个page的lsn(log sequence number),这个和wal(write ahead log,同oracle redo)中记录的lsn一致。数据落盘时redo必须先刷到wal,这个pd_lsn就记录了最后data落盘时的相关redo的lsn。 - pd_checksum
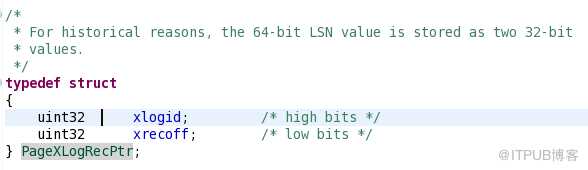
校验和,在initdb初始化实例的时候通过-k参数指定开启,默认是关闭的,initdb之后不能修改,它基于FNV-1a hash算法,做了相应的更改。这个校验和与Oracle的checksum一样用于数据块在读入和写出内存时的校验。比如我们在内存中修改了一个数据块,写入到磁盘的时候,在内存里面先计算好checksum,数据块写完后再计算一遍cheksum是否和之前在内存中的一致,确保整个写出过程没有出错,保护数据结构不被破坏。 - PageXLogRecPtr为一个结构体,64位。记录xlog信息的原因:
- 保证buffer manger WAL原则, 即写日志先于写数据
- 脏块checkpoint时,日志先刷出到disk
- pd_flags 表示页面状态
PD_ALL_VISIBLE(0x0001) – 表示所有元组可以访问。
PD_VALID_FLAG_BITS(0x0003) – 加密存储相关。
PG_PAGE_ENCRYPTED(0x0002) – 支持统一存储加密引擎。 - pd_lower
空闲空间起始位置,随着插入和删除操作位置发生变化。初始化时就是pd_linp的偏移位置。 - pd_upper
空闲空间结束位置,随着插入和删除操作位置发生变化。初始化时与pd_special相同。 - pd_special
pd_special在索引page才有效。相当于画了一条线,从pd_special这个位置到page的结尾,都是special的地盘,普通插入Tuple,都不许进入这个私有地盘。而且这个pd_special一旦初始化之后,这个值就不会动了。
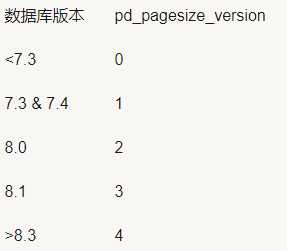
主要用于加密存储是保存加密相关的数据。 - pd_pagesize_version
高位字节表示page大小。
低位字节表示版本号(PG_PAGE_LAYOUT_VERSION),代码写死。
宏PageSetPageSizeAndVersion用于设置大小和版本。
宏PageGetPageSize()获取Page大小。
宏PageGetPageLayoutVersion()获取版本号。
对应的实现:


#define PageSetPageSizeAndVersion(page, size, version) \
( \
AssertMacro(((size) & 0xFF00) == (size)), \
AssertMacro(((version) & 0x00FF) == (version)), \
((PageHeader) (page))->pd_pagesize_version = (size) | (version) \
)
#define PageGetPageSize(page) \
((Size) (((PageHeader) (page))->pd_pagesize_version & (uint16) 0xFF00))
#define PageGetPageLayoutVersion(page) \
(((PageHeader) (page))->pd_pagesize_version & 0x00FF)
- prune_xid
prune_xid表示这个page上最早删除或者修改tuple的事务id,在vacuum操作的时候会用到。(pg没有undo,旧的数据也在page中,用vacuum来清理)
2.3.Page的初始化函数
源码在src/backend/storage/page/bufpage.c中:
/*
* PageInit
* Initializes the contents of a page.
* Note that we don't calculate an initial checksum here; that's not done
* until it's time to write.
*/
void
PageInit(Page page, Size pageSize, Size specialSize)
{
PageHeader p = (PageHeader) page;
specialSize = MAXALIGN(specialSize);
Assert(pageSize == BLCKSZ);
Assert(pageSize > specialSize + SizeOfPageHeaderData);
/* Make sure all fields of page are zero, as well as unused space */
MemSet(p, 0, pageSize);
p->pd_flags = 0;
p->pd_lower = SizeOfPageHeaderData;
p->pd_upper = pageSize - specialSize;
p->pd_special = pageSize - specialSize;
PageSetPageSizeAndVersion(page, pageSize, PG_PAGE_LAYOUT_VERSION);
/* p->pd_prune_xid = InvalidTransactionId; done by above MemSet */
}
2.4.Page有效性检查
bool
PageHeaderIsValid(PageHeader page)
{
char *pagebytes;
int i;
/* Check normal case */
/* Support the uniform store encryption engine. */
if (PageGetPageSize(page) == BLCKSZ &&
PageGetPageLayoutVersion(page) == PG_PAGE_LAYOUT_VERSION &&
(page->pd_flags & ~PD_VALID_FLAG_BITS) == 0 &&
page->pd_lower >= SizeOfPageHeaderData &&
page->pd_lower <= page->pd_upper &&
page->pd_upper <= page->pd_special &&
(PageIsEncrypted(page) ?
page->pd_special <= BLCKSZ - G_EncryptData->block_key_num * (G_EncryptData->key_len + G_EncryptData->verify_len) :
page->pd_special <= BLCKSZ) &&
page->pd_special == MAXALIGN_DISK(page->pd_special))
return true;
/* Check all-zeroes case */
pagebytes = (char *) page;
for (i = 0; i < BLCKSZ; i++)
{
/* Support the uniform store encryption engine. */
if (pagebytes[i] != 0 && pagebytes[i] != 2)
return false;
}
return true;
}
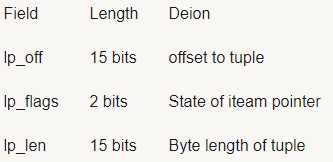
2.5.linp结构(行指针)
头文件:src/include/storage/itemid.h
/*
* An item pointer (also called line pointer) on a buffer page
*
* In some cases an item pointer is "in use" but does not have any associated
* storage on the page. By convention, lp_len == 0 in every item pointer
* that does not have storage, independently of its lp_flags state.
*/
typedefstruct ItemIdData
{
unsigned lp_off:15,/* offset to tuple (from start of page) */
lp_flags:2, /* state of item pointer, see below */
lp_len:15; /* byte length of tuple */
}ItemIdData;
typedef ItemIdData *ItemId;
/*
* lp_flags has these possible states. An UNUSED line pointer is available
* for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0) */
#define LP_DEAD 3 /* dead, may or may not have storage */
/*
* Item offsets and lengths are represented by these types when
* they're not actually stored in an ItemIdData.
*/
typedef uint16 ItemOffset;
typedef uint16 ItemLength;
lp_off是tuple的开始的偏移量;lp_flags是标志位;lp_len记录了tuple的长度。
2.6.tuple header结构(行头)
源代码在src/include/access/htup_details.h
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union{CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
int32 datum_len_; /* varlena header (do not touch directly!) */
int32 datum_typmod; /* -1, or identifier of a record type */
Oid datum_typeid; /* composite type OID, or RECORDOID */
/** Note: field ordering is chosen with thought that Oid might someday
* widen to 64 bits.*/
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
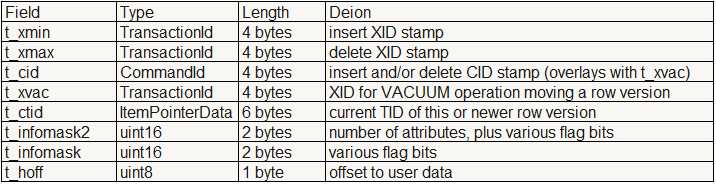
- union是共享结构体,起作用的变量是最后一次赋值的成员。来看看tuple header的结构。
- 在HeapTupleFields中,t_xmin是插入这行tuple的事务id;t_xmax是删除或者锁住tuple的事务id;union结构中的t_cid是删除或者插入这个tuple的命令id,也就是命令序号;t_xvac是以前格式的vacuum full用到的事务id。
- 在DatumTupleFields中,datum_len_ 指tuple的长度;datum_typmod是记录的type;datum_typeid是记录的id。
- 页头HeapTupleHeaderData包含了union结构体中的两个变量HeapTupleFields和DatumTupleFields。t_ctid是tuple id,类似oracle的rowid,形式为(块号,行号)。
- t_infomask2 表示属性和标志位
- t_infomask 是flag标志位,具体值如下:
/** information stored in t_infomask:*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0* VACUUM FULL; kept for binary* upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0* VACUUM FULL; kept for binary* upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
- t_hoff表示tuple header的长度
- t_bits记录了tuple中null值的列
2.7.总结
PG中页的结构大体上Oracle的Block结构是比较类似的,都是采用向上涨的方式来存储记录。但是在小细节上还是分别比较大的。Oracle的Block中还有ITL等事务相关信息等。
3.DML操作分析
3.1.Insert
当初始化的时候,pd_lower设置为SizeOfPageHeaderData,pd_upper设置为pd_special。pg_lower和pd_upper随着Tuple的不断插入,pd_lower增大,而pd_upper减小。每插入一条Tuple,需要在当前的pd_lower位置再分配一个Item,记录Tuple的长度,Tuple的起始位置offset,还有flag信息。PageHeader中的pd_lower就是记录分配下一个Item的起始位置。所以如果不断插入,pd_lower不断增加,每增加一条Tuple,就要分配一个Item(4个字节)。
对应实现函数:
PageAddItem
OffsetNumber
PageAddItem(Page page,
Item item,
Size size,
OffsetNumber offsetNumber,
Size tupleSize,
ItemIdFlags flags)
3.2.Delete
对应实现函数:
PageIndexMultiDelete
void
PageIndexMultiDelete(Page page, OffsetNumber *itemnos, int nitems)
4.pageinspect插件
如何简单快速方便的查看Page中的内容?不同于Oracle各种dump,在PG中可以方便的使用pageinspect插件提供的各种函数查看Page中的内容。
4.1.pageinspect说明
4.1.1.General Functions
get_raw_page(relname text, fork text, blkno int) returns bytea
get_raw_page reads the specified block of the named relation and returns a copy as a bytea value. This allows a single time-consistent copy of the block to be obtained. fork should be ‘main’ for the main data fork, ‘fsm’ for the free space map, ‘vm’ for the visibility map, or ‘init’ for the initialization fork.
get_raw_page(relname text, blkno int) returns bytea
A shorthand version of get_raw_page, for reading from the main fork. Equivalent to get_raw_page(relname, ‘main’, blkno)
page_header(page bytea) returns record
page_header shows fields that are common to all PostgreSQL heap and index pages.
A page image obtained with get_raw_page should be passed as argument.
For example:
test=# SELECT * FROM page_header(get_raw_page('pg_class', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+--------+-------+-------+---------+----------+---------+-----------
0/24A1B50 | 0 | 1 | 232 | 368 | 8192 | 8192 | 4 | 0
The returned columns correspond to the fields in the PageHeaderData struct. See for src/include/storage/bufpage.h details.
The checksum field is the checksum stored in the page, which might be incorrect if the page is somehow corrupted. If data checksums are not enabled for this instance, then the value stored is meaningless.
page_checksum(page bytea, blkno int4) returns smallint
page_checksum computes the checksum for the page, as if it was located at the given block.
A page image obtained with get_raw_page should be passed as argument.
For example:
test=# SELECT page_checksum(get_raw_page('pg_class', 0), 0);
page_checksum
---------------
13443
Note that the checksum depends on the block number, so matching block numbers should be passed (except when doing esoteric debugging).
The checksum computed with this function can be compared with the checksum result field of the function page_header. If data checksums are enabled for this instance, then the two values should be equal.
fsm_page_contents(page bytea) returns text
fsm_page_contents shows the internal node structure of a FSM page. For example:
test=# SELECT fsm_page_contents(get_raw_page('pg_class', 'fsm', 0));
The output is a multiline string, with one line per node in the binary tree within the page. Only those nodes that are not zero are printed. The so-called “next” pointer, which points to the next slot to be returned from the page, is also printed.
See src/backend/storage/freespace/README for more information on the structure of an FSM page.
4.1.2.Heap Functions
heap_page_items(page bytea) returns setof record
heap_page_items shows all line pointers on a heap page. For those line pointers that are in use, tuple headers as well as tuple raw data are also shown. All tuples are shown, whether or not the tuples were visible to an MVCC snapshot at the time the raw page was copied.
A heap page image obtained with get_raw_page should be passed as argument. For example:
test=# SELECT * FROM heap_page_items(get_raw_page('pg_class', 0));
See src/include/storage/itemid.h and src/include/access/htup_details.h for explanations of the fields returned.
tuple_data_split(rel_oid oid, t_data bytea, t_infomask integer, t_infomask2 integer, t_bits text [, do_detoast bool]) returns bytea[]
tuple_data_split splits tuple data into attributes in the same way as backend internals.
test=# SELECT tuple_data_split('pg_class'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('pg_class', 0));
This function should be called with the same arguments as the return attributes of heap_page_items.
If do_detoast is true, attribute that will be detoasted as needed. Default value is false.
heap_page_item_attrs(page bytea, rel_oid regclass [, do_detoast bool]) returns setof record
heap_page_item_attrs is equivalent to heap_page_items except that it returns tuple raw data as an array of attributes that can optionally be detoasted by do_detoast which is false by default.
A heap page image obtained with get_raw_page should be passed as argument. For example:
test=# SELECT * FROM heap_page_item_attrs(get_raw_page('pg_class', 0), 'pg_class'::regclass);
4.1.3.B-tree Functions
bt_metap(relname text) returns record
bt_metap returns information about a B-tree index’s metapage. For example:
test=# SELECT * FROM bt_metap('pg_cast_oid_index');
-[ RECORD 1 ]-----------+-------
magic | 340322
version | 3
root | 1
level | 0
fastroot | 1
fastlevel | 0
oldest_xact | 582
last_cleanup_num_tuples | 1000
bt_page_stats(relname text, blkno int) returns record
bt_page_stats returns summary information about single pages of B-tree indexes. For example:
test=# SELECT * FROM bt_page_stats('pg_cast_oid_index', 1);
-[ RECORD 1 ]-+-----
blkno | 1
type | l
live_items | 256
dead_items | 0
avg_item_size | 12
page_size | 8192
free_size | 4056
btpo_prev | 0
btpo_next | 0
btpo | 0
btpo_flags | 3
bt_page_items(relname text, blkno int) returns setof record
bt_page_items returns detailed information about all of the items on a B-tree index page. For example:
test=# SELECT * FROM bt_page_items('pg_cast_oid_index', 1);
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------
1 | (0,1) | 12 | f | f | 23 27 00 00
2 | (0,2) | 12 | f | f | 24 27 00 00
3 | (0,3) | 12 | f | f | 25 27 00 00
4 | (0,4) | 12 | f | f | 26 27 00 00
5 | (0,5) | 12 | f | f | 27 27 00 00
6 | (0,6) | 12 | f | f | 28 27 00 00
7 | (0,7) | 12 | f | f | 29 27 00 00
8 | (0,8) | 12 | f | f | 2a 27 00 00
In a B-tree leaf page, ctid points to a heap tuple. In an internal page, the block number part of ctid points to another page in the index itself, while the offset part (the second number) is ignored and is usually 1.
Note that the first item on any non-rightmost page (any page with a non-zero value in the btpo_next field) is the page’s “high key”, meaning its data serves as an upper bound on all items appearing on the page, while its ctid field is meaningless. Also, on non-leaf pages, the first real data item (the first item that is not a high key) is a “minus infinity” item, with no actual value in its data field. Such an item does have a valid downlink in its ctid field, however.
bt_page_items(page bytea) returns setof record
It is also possible to pass a page to bt_page_items as a bytea value. A page image obtained with get_raw_page should be passed as argument. So the last example could also be rewritten like this:
test=# SELECT * FROM bt_page_items(get_raw_page('pg_cast_oid_index', 1));
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------
1 | (0,1) | 12 | f | f | 23 27 00 00
2 | (0,2) | 12 | f | f | 24 27 00 00
3 | (0,3) | 12 | f | f | 25 27 00 00
4 | (0,4) | 12 | f | f | 26 27 00 00
5 | (0,5) | 12 | f | f | 27 27 00 00
6 | (0,6) | 12 | f | f | 28 27 00 00
7 | (0,7) | 12 | f | f | 29 27 00 00
8 | (0,8) | 12 | f | f | 2a 27 00 00
All the other details are the same as explained in the previous item.
4.1.4.BRIN Functions
brin_page_type(page bytea) returns text
brin_page_type returns the page type of the given BRIN index page, or throws an error if the page is not a valid BRIN page. For example:
test=# SELECT brin_page_type(get_raw_page('brinidx', 0));
brin_page_type
----------------
meta
brin_metapage_info(page bytea) returns record
brin_metapage_info returns assorted information about a BRIN index metapage. For example:
test=# SELECT * FROM brin_metapage_info(get_raw_page('brinidx', 0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 4 | 2
brin_revmap_data(page bytea) returns setof tid
brin_revmap_data returns the list of tuple identifiers in a BRIN index range map page. For example:
test=# SELECT * FROM brin_revmap_data(get_raw_page('brinidx', 2)) LIMIT 5;
pages
---------
(6,137)
(6,138)
(6,139)
(6,140)
(6,141)
brin_page_items(page bytea, index oid) returns setof record
brin_page_items returns the data stored in the BRIN data page. For example:
test=# SELECT * FROM brin_page_items(get_raw_page('brinidx', 5),
'brinidx')
ORDER BY blknum, attnum LIMIT 6;
itemoffset | blknum | attnum | allnulls | hasnulls | placeholder | value
------------+--------+--------+----------+----------+-------------+--------------
137 | 0 | 1 | t | f | f |
137 | 0 | 2 | f | f | f | {1 .. 88}
138 | 4 | 1 | t | f | f |
138 | 4 | 2 | f | f | f | {89 .. 176}
139 | 8 | 1 | t | f | f |
139 | 8 | 2 | f | f | f | {177 .. 264}
The returned columns correspond to the fields in the BrinMemTuple and BrinValues structs. See src/include/access/brin_tuple.h for details.
4.1.5.GIN Functions
gin_metapage_info(page bytea) returns record
gin_metapage_info returns information about a GIN index metapage. For example:
test=# SELECT * FROM gin_metapage_info(get_raw_page('gin_index', 0));
-[ RECORD 1 ]----+-----------
pending_head | 4294967295
pending_tail | 4294967295
tail_free_size | 0
n_pending_pages | 0
n_pending_tuples | 0
n_total_pages | 7
n_entry_pages | 6
n_data_pages | 0
n_entries | 693
version | 2
gin_page_opaque_info(page bytea) returns record
gin_page_opaque_info returns information about a GIN index opaque area, like the page type. For example:
test=# SELECT * FROM gin_page_opaque_info(get_raw_page('gin_index', 2));
rightlink | maxoff | flags
-----------+--------+------------------------
5 | 0 | {data,leaf,compressed}
(1 row)
gin_leafpage_items(page bytea) returns setof record
gin_leafpage_items returns information about the data stored in a GIN leaf page. For example:
test=# SELECT first_tid, nbytes, tids[0:5] AS some_tids
FROM gin_leafpage_items(get_raw_page('gin_test_idx', 2));
first_tid | nbytes | some_tids
-----------+--------+----------------------------------------------------------
(8,41) | 244 | {"(8,41)","(8,43)","(8,44)","(8,45)","(8,46)"}
(10,45) | 248 | {"(10,45)","(10,46)","(10,47)","(10,48)","(10,49)"}
(12,52) | 248 | {"(12,52)","(12,53)","(12,54)","(12,55)","(12,56)"}
(14,59) | 320 | {"(14,59)","(14,60)","(14,61)","(14,62)","(14,63)"}
(167,16) | 376 | {"(167,16)","(167,17)","(167,18)","(167,19)","(167,20)"}
(170,30) | 376 | {"(170,30)","(170,31)","(170,32)","(170,33)","(170,34)"}
(173,44) | 197 | {"(173,44)","(173,45)","(173,46)","(173,47)","(173,48)"}
(7 rows)
4.1.6.Hash Functions
hash_page_type(page bytea) returns text
hash_page_type returns page type of the given HASH index page. For example:
test=# SELECT hash_page_type(get_raw_page('con_hash_index', 0));
hash_page_type
----------------
metapage
hash_page_stats(page bytea) returns setof record
hash_page_stats returns information about a bucket or overflow page of a HASH index. For example:
test=# SELECT * FROM hash_page_stats(get_raw_page('con_hash_index', 1));
-[ RECORD 1 ]---+-----------
live_items | 407
dead_items | 0
page_size | 8192
free_size | 8
hasho_prevblkno | 4096
hasho_nextblkno | 8474
hasho_bucket | 0
hasho_flag | 66
hasho_page_id | 65408
hash_page_items(page bytea) returns setof record
hash_page_items returns information about the data stored in a bucket or overflow page of a HASH index page. For example:
test=# SELECT * FROM hash_page_items(get_raw_page('con_hash_index', 1)) LIMIT 5;
itemoffset | ctid | data
------------+-----------+------------
1 | (899,77) | 1053474816
2 | (897,29) | 1053474816
3 | (894,207) | 1053474816
4 | (892,159) | 1053474816
5 | (890,111) | 1053474816
hash_bitmap_info(index oid, blkno int) returns record
hash_bitmap_info shows the status of a bit in the bitmap page for a particular overflow page of HASH index. For example:
test=# SELECT * FROM hash_bitmap_info('con_hash_index', 2052);
bitmapblkno | bitmapbit | bitstatus
-------------+-----------+-----------
65 | 3 | t
hash_metapage_info(page bytea) returns record
hash_metapage_info returns information stored in meta page of a HASH index. For example:
test=# SELECT magic, version, ntuples, ffactor, bsize, bmsize, bmshift,
test-# maxbucket, highmask, lowmask, ovflpoint, firstfree, nmaps, procid,
test-# regexp_replace(spares::text, '(,0)*}', '}') as spares,
test-# regexp_replace(mapp::text, '(,0)*}', '}') as mapp
test-# FROM hash_metapage_info(get_raw_page('con_hash_index', 0));
-[ RECORD 1 ]-------------------------------------------------------------------------------
magic | 105121344
version | 4
ntuples | 500500
ffactor | 40
bsize | 8152
bmsize | 4096
bmshift | 15
maxbucket | 12512
highmask | 16383
lowmask | 8191
ovflpoint | 28
firstfree | 1204
nmaps | 1
procid | 450
spares | {0,0,0,0,0,0,1,1,1,1,1,1,1,1,3,4,4,4,45,55,58,59,508,567,628,704,1193,1202,1204}
mapp | {65}
4.2.pageinspect安装
安装
它在源码的crontrib目录下面
#cd $PGSRC/contrib/pageinspect
#make
#make install
使用
#psql -d test
testdb#create extension pageinspect; -- 首次使用需创建Extension
创建测试表
drop table if exists t_new;
create table t_new (id char(4),c1 varchar(20));
insert into t_new values('1','#');
查看page header&item
SELECT * FROM page_header(get_raw_page('t_new', 0));
select * from heap_page_items(get_raw_page('t_new',0));
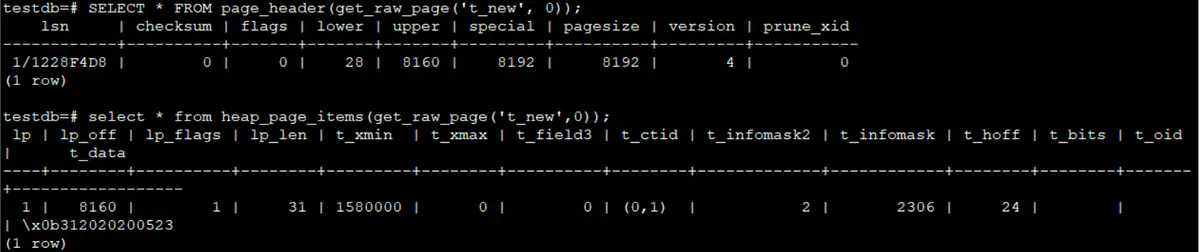
查看Page中的raw内容
x
select * from get_raw_page('t_new', 0);
page头部:

page尾部:

4.3.pageinspect实验
创建建测试表t1,插入数据:
test=# create table t1(id int, name varchar(10));
CREATE TABLE
test=# insert into t1 select generate_series(1,1000), generate_series(1,1000)||'_x';
INSERT 0 1000
test=# select * from t1 limit 3;
id | name
----+------
1 | 1_x
2 | 2_x
3 | 3_x
(3 rows)
test=# select count(*) from t1;
count
-------
1000
(1 row)
test=# select max(ctid) from t1;
max
--------
(5,73)
(1 row)
test=# \d+
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+-------+-------+----------+-------------+------------+-------------
public | t1 | table | postgres | permanent | 72 kB |
public | t_new | table | postgres | permanent | 8192 bytes |
(2 rows)
test=# select ctid, * from t_new;
ctid | id | c1
-------+------+----
(0,1) | 1 | #
(1 row)
1000行数据用了6个数据块来存储,数据块从0开始,第6个数据块包含了73条记录(tuple)。
ctid: 表示数据记录的物理行信息,指的是一条记录位于哪个数据块的位移。 和Oracle中伪列rowid类似;只是形式不一样。
例如:
test=# select ctid, * from t1 where id < 8;
ctid | id | name
-------+----+------
(0,1) | 1 | 1_x
(0,2) | 2 | 2_x
(0,3) | 3 | 3_x
(0,4) | 4 | 4_x
(0,5) | 5 | 5_x
(0,6) | 6 | 6_x
(0,7) | 7 | 7_x
(7 rows)
ctid的格式是(blockid,itemid):例如(0,1);0表示块id;1表示块中的第一条记录。
Pageinspect查看page_header
test=# select * from page_header(get_raw_page('t1',0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/161A278 | 0 | 0 | 772 | 784 | 8192 | 8192 | 4 | 0
(1 row)
第0个page的pd_lsn为0/1671188,checksum和flags都是0,没有开启checksum;tuple开始偏移是772(pd_lower),结束偏移是784(pd_upper),这个page是个表,所以它没有special,sepcial值是8192,指向末尾;pagesize是8192即8K,version是4,没有需要清理的tuple,所以存储需要清理的tuple的最早事务的id就是0(prune_xid)。
Pageinspect查看heap_page_items
test=# select * from heap_page_items(get_raw_page('t1',0)) limit 1;
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------
1 | 8160 | 1 | 32 | 491 | 0 | 0 | (0,1) | 2 | 2306 | 24 | | | \x0100000009315f78
(1 row)
查看第一行记录,(lp=1),tuple的开始偏移量8160(lp_off),tuple的长度是32 bytes(lp_len为32,这个tuple是第一个插入的tuple,所以lp_off+lp_len=8160+32=8192),这行记录的插入事务id是491(t_xmin),和tuple的删除事务id是0(t_xmax),数据没有被删除,所以都是0。t_ctid是(0,1),表示这个tuple是这个page中第一个块的第一条tuple;t_infomask2是2,t_infomask为2306,十六进制就是 0x0902 ,可以根据预定义HEAP_*的值去看看具体的含义,0x0902 = 0x0100 + 0x0800 +0x0002;tuple头部结构(行头)的长度是24(t_hoff),t_data就是16进制存储的真正的数据了。
删除一行数据观察prune_xid
test=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | |
name | character varying(10) | | |
test=# select * from page_header(get_raw_page('t1',0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/161A278 | 0 | 0 | 772 | 784 | 8192 | 8192 | 4 | 0
(1 row)
test=# delete from t1 where id=1;
DELETE 1
test=# select * from page_header(get_raw_page('t1',0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/162D2C0 | 0 | 0 | 772 | 784 | 8192 | 8192 | 4 | 493
(1 row)
prune_xid的值从“0”变为“493”,493就是删除这个tuple的事务id(当前最早的删除或更改tuple的事务id)。
test=# select * from heap_page_items(get_raw_page('t1',0)) limit 1;
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------
1 | 8160 | 1 | 32 | 491 | 493 | 0 | (0,1) | 8194 | 258 | 24 | | | \x0100000009315f78
(1 row)
lp为1的这个tuple的t_xmax为493,也就是删除这个tuple的事务id。