PostgreSQL体系结构
1.PostgreSQL体系结构的概念
数据库
PostgreSQL 数据库是由一系列位于文件系统上的物理文件组成,在数据库运行过程
中,通过整套高效严谨的逻辑管理这些物理文件。通常将这些物理文件称为数据库。
实例
PostgreSQL中的进程和内存称为数据库的实例,即实例由一系列进程和内存组成。PostgreSQL 使用一个简单的 “每个用户一个进程” 的客户/服务器模型。PostgreSQL 有许多种类型进程。
PostgreSQL体系结构的组件,可以根据PostgreSQL 的功能实现,分为:
- 系统控制器:接收外部连接请求,对请求进行预处理和分发。
- 编译执行系统:对请求进行分析并生成优化后的查询解析树,从文件系统获取结果集或通过事务系统对数据做处理,并由文件系统持久化数据。
- 存储管理系统
- 事务系统:由事务管理器,日志管理器,并发控制,锁管理器组成,日志管理器和事务管理器完成对操作请求的事务一致性支持,锁管理器和并发控制提供对并发访问数据的一致性支持。
- 系统表:在关系数据库中,为了实现数据库系统的控制,必须提供数据字典的功能。数据字典不仅存储各种对象的描述信息,而且存储系统管理所需的各种对象的细节信息。数据字典包含数据库系统中所有对象及其属性的描述信息,对象之间关系的描述信息,对象属性的自然语言含义以及数据字典变化的历史,数据字典是关系数据库系统管理控制信息的核心,在PostgreSQL数据库系统中系统表扮演着数据字典的角色。系统表保存了数据库的所有元数据,所以系统运行时对系统表的访问是非常频繁的。为了提高系统性能,在内存中建立了共享的系统表,使用Hash表提高查询效率。
- 恢复系统
PostgreSQL体系结构,也可以根据数据库的组成,工作过程,以及数据的组织与管理机制来描述。
2.逻辑结构
数据库集群(Database Cluster)
是指由单个PostgreSQL 服务器实例管理的数据库集合,组成数据库集群的
这些数据库使用相同的全局配置文件和监昕端口、共用进程和内存结构,并不是指“一组
数据库服务器构成的集群”,PostgreSQL 中说的某一个数据库实例通常是指某个数据库
集群。
数据库集群是数据库对象的集合,在关系数据库理论中,数据库对象是用于存储或引
用数据的数据结构,包括表、索引、序列、视图、函数等对象。
在PostgreSQL 中,数据库本身也是数据库对象,并且在逻辑上彼此分离,除数据库之外的其他数据库对象( 例如表、索引等)都属于它们各自的数据库,虽然它们隶属同一个数据库集群,但无法直接从集群中的-个数据库访问该集群中的另一个数据库中的对象。
数据库本身也是数据库对象, 一个数据库集群可以包含多个Databases、多个Users,每
个Database 以及Database 中的所有对象都有它们的所有者:User。
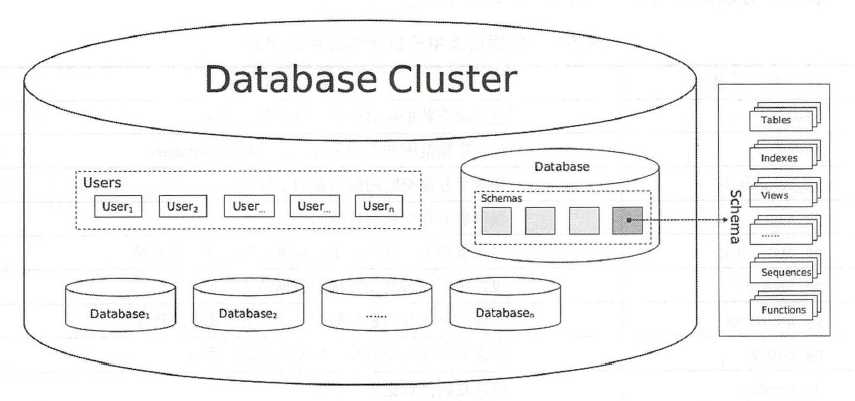
创建一个Database时会为这个Databas创建一个名为public的默认Schema,每个Database 可以有多个Schema,在这个数据库中创建其他数据库对象时如果没有指定Schema , 都会在public 这个Schema中。Schema可以理解为一个数据库中的命名空间,在数据库中创建的所有对象都在Schema中创建一个用户可以从同一个客户端连接中访问不同的Schema 。不同的Schema 中可以有多个相同名称的Table、Index、View、Sequence、Function等数据库对象。
3.物理结构
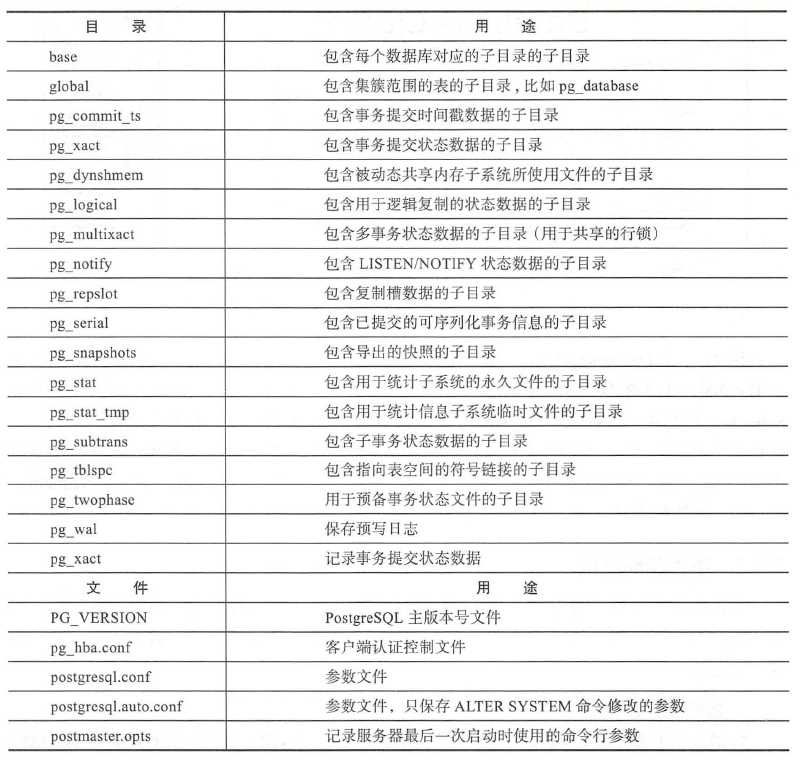
数据库的文件默认保存在initdb 时创建的数据目录中。在数据目录中有很多类型、功
能不同的目录和文件除了数据文件之外还有参数文件、控制文件、数据库运行日志及
预写日志等。
3.1 数据目录结构
数据目录用来存放PostgreSQL 持久化的数据, 通常可以将数据目录路径配置为PGDATA
环境变量。
$tree 一L 1 - d /pgdata/10/data
3.2 OID
PostgreSQL 中的所有数据库对象都由各自的对象标识符(OID)进行内部管理,它们是
无符号的4字节整数。数据库对象和各个OID 之间的关系存储在适当的系统目录中,具体
取决于对象的类型。数据库的OID存储在pg_database系统表中。
SELECT oid, datname FROM pg_database WHERE datname = 'mydb';
数据库中的表、索引、序列等对象的OID 存储在pg_class 系统表中。
SELECT oid, relname, relkind FROM pg_class WHERE relname ~ 'tbl';
3.3 表空间
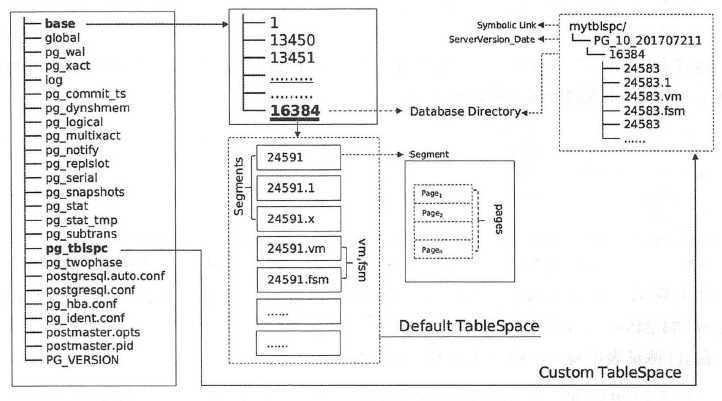
在PostgreSQL中最大的逻辑存储单位是表空间,数据库中创建的对象都保存在表空间中,例如表、索引和整个数据库都可以被分配到特定的表空间。在创建数据库对象时,可以指定数据库对象的表空间,如果不指定则使用默认表空间,也就是数据库对象的文件的位置。初始化数据库目录时会自动创建pg_default和pg_global两个表空间。
#\db
- pg_global表空间的物理文件位置在数据目录的global目录中,它用来保存系统表。
- pg_default表空间的物理文件位置在数据目录中的base目录,是templateO 和templatel 数据库的默认表空间,我们知道创建数据库时,默认从template1 数据库进行克隆,因此除非特别指定了新建数据库的表空间,默认使用templatel 的表空间, 也就是pg_default。
除了两个默认表空间, 用户还可以创建自定义表空间。使用自定义表空间有两个典型的场景:
- 通过创建表空间解决已有表空间磁盘不足并无法逻辑扩展的问题;
- 将索引、WAL 、数据文件分配在性能不同的磁盘上,使硬件利用率和性能最大化。
要创建一个表空间,先用操作系统的postgres用户创建一个目录,然后连接到数据库,使用CREATE TABLESPACE 命令创建表空间,如下所示:
$mkdir - p /pgdata/1 0/mytblspc
$/usr/pgsql - 10/b in /ps ql -p 1921 mydb
mydb=# CREATE TABLESPACE myspc LOCATION '/pgdata/10/mytblspc'
mydb=# \db
mydb=# CREATE TABLE t (id SERIAL PRIMARY KEY , ival int) TABLESPACE myspc ;
由于表空间定义了存储的位置,在创建数据库对象时,会在当前的表空间目录创建一
个以数据库OID命名的目录,该数据库的所有对象将保存在这个目录中,除非单独指定表
空间。例如我们一直使用的数据库mydb,从pg_database系统表查询它的OID,如下所示:
mydb=# SELECT oid, datname FROM pg_database WHERE datname ='mydb';
通过以上查询可知mydb的OID为16384,我们就可以知道mydb的表、索引都会保存在$PGDATA/base/16384这个目录中,如下所示:
11 /pgdata/10/data /base/16384/
3.4 数据文件
pg中,每个索引和表都是一个单独的文件,pg中叫做page。默认是每个大于1G的page会被分割pg_class.relfilenode.1这样的文件。page的大小在initdb的时候指定(–with-segsize)
在数据库中创建对象,例如表、索引时首先会为表和索引分配段。在PostgreSQL中,每个表和索引都用一个文件存储,新创建的表文件以表的OID命名,对于大小超出lGB的表数据文件,PostgreSQL会自动将其切分为多个文件来存储,切分出的文件用OID.<顺序号>来命名。但表文件并不是总是”OID.<顺序号>”命名,实际上真正管理表文件的是pg_class表中的relfilenode字段的值,在新创建对象时会在pg_class系统表中插入该表的记录,默认会以OID作为relfilenode的值,但经过几次VACUUM、TRUNCATE操作之后,relfilenode的值会发生变化。
mydb=# SELECT oid,relfilenode FROM pg_class WHERE relname ='tbl';
mydb=# \ ! ls - 1 / pgdata/10/data/base/16384/16387*
在默认情况下, tbl表的OID为16387, relfilenode也是16387,表的物理文件为“/pg_data/IO/data/base/16384/16387”。依次TRUNCATE清空tbl表的所有数据,如下所示:
mydb=# TRUNCATE tbl;
TRUNCATE TABLE
mydb=# CHECKPOINT ;
CHECKPOINT
mydb=# \ ! ls -1 /pgdata/10/data/base/16384/16387*
ls cannot access /pgdata/10/data/base/16384/16387* : No such fi l e or directory
通过上述操作之后,tbl表原先的物理文件“/pgdata/lO/data/base/16384/16387”已经不存在了,那么tbl表的数据文件是哪一个?
postgres@160.40:1922/mydb=# select oid,relfilenode from pg_class where relname ='tbl'
oid | relf ilenode
-----+-------------
16387| 24591
(1 row )
postgres@160.40:1922/mydb=# \! ls - 1 /pgdata/10/data/base/16384/24591*
- rw- ------ 1 postgres postgres 0 Apr 2 21:24 /pgdata/10/data/base/ 16384/24591
如上所示,再次查询问pg_class表得知tbl表的数据文件已经成为“/pgdata/lO/data/base/16384/24591” ,它的命名规则为<relfilenode>.<顺序号>。
在tbl测试表中写入一些测试数据,如下所示:
mydb=# insert into tbl (ival,descr工ption, created_time) select (random()* (2*10^9)) : :
integer as ival, substr ('abcdefghijklmnopqrstuvwxyz', 1, (random()*26)::integer ) as description, date(generate_series(now(),now() + '1 week','1 day')) as
created_time from generate_series(1,2000000);
INSERT 0 16000000
查看表的大小,如下所示:
mydb=# SELECT pg_size_pretty(pg_relation_size ('tbl'::regclass));
通过上述命令看到tbl 表的大小目前为1068MB ,执行一些UPDATE 操作后再次查看数
据文件,如下所示:
/mydb=# \! ls - lh /pgdata/10/data/base/16384/24591*
- rw------- 1 postgres postgres 1.0G Apr 7 08 : 44 /pgdata/10/data/base/16384/24591
-rw---- 1 postgres postgres 383M Apr 7 08 : 44 /pgdata/10/data/base/16384/24591 .1
- rw--- --- 1 postgres postgres 376K Apr 7 08 : 44 /pgdata/10/data/base/16384/24591_fsm
- rw------- 1 postgres postgres 8.0K Apr 7 08 :4 4 /pgdata/10/data/base/1638 4/24591_vm
如前文所述,数据文件的命名规则为<relfilenode>.<顺序号>, tbl表的大小超过lGB, tbl 表的relfilenode为24591,超出1GB之外的数据会按每GB切割,在文件系统中查看时就是名称为24591.1的数据文件。在上述输出结果中,后缀为_fsm和_vm 的这两个表文件的附属文件是空闲空间映射表文件和可见性映射表文件。空闲空间映射用来映射表文件中可用的空间,可见性映射表文件跟踪哪些页面只包含己知对所有活动事务可见的元组,它也眼踪哪些页面只包含未被冻结的元组。下图显示了PostgreSQL数据目录、表空间以及文件的结构概貌。
3.5 表文件内部结构
在PostgreSQL中,将保存在磁盘中的块称为Page,而将内存中的块称为Buffer,表和索引称为Relation,行称为Tuple,如图所示。数据的读写是以Page为最小单位,每个Page 默认大小为8kB ,在编译PostgreSQL时指定的BLCKSZ大小决定Page的大小。每个表文件由多个BLCKSZ 字节大小的Page组成,每个Page包含若干Tuple。对于I/O性能较好的硬件,并且以分析为主的数据库,适当增加BLCKSZ大小可以小幅提升数据库性能。
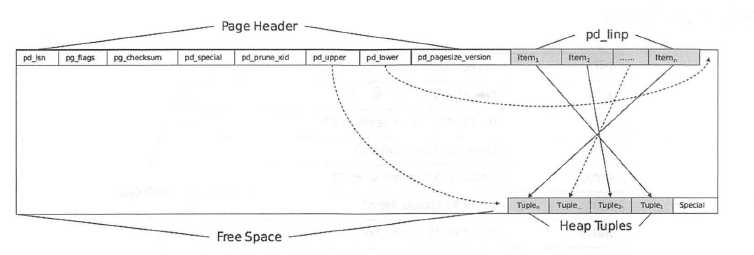
PageHeader描述了一个数据页的页头信息,包含页的一些元信息。它的结构及其结构指针PageHeader的定义如下:
- pd_lsn : 在ARIES Recovery Algorithm的解释中,这个lsn称为PageLSN,它确定和记录了最后更改此页的xlog记录的LSN,把数据页和WAL日志关联,用于恢复数据时校验日志文件和数据文件的一致性;pd_lsn的高位为xlogid,低位记录偏移量;因为历史原因,64位的LSN保存为两个32位的值。
- pg_flags :标识页面的数据存储情况。
- pd_special : 指向索引相关数据的开始位置,该项在数据文件中为空,主要是针对不同索引。
- pd_lower :指向空闲空间的起始位置。
- pd_upper :指向空闲空间的结束位置。
- pd_pagesize version : 不同的PostgreSQL版本的页的格式可能会不同。
- pd_linp[l]:行指针数组,即图中的Item1, Item2, … , Itemn,这些地址指向Tuple的存储位置。
如果一个表由一个只包含一个堆元组的页面组成。该页面的pd_lower指向第一行指针,并且行指针和pd_upper都指向第一个堆元组。当第二个元组被插入时,它被放置在第一个元组之后。第二行指针被压入第一行,并指向第二个元组。pd_lower更改为指向第二行指针,pd_upper更改为第二个堆元组。此页面中的其他头数据(例如,pd_lsn, pg_checksum、pg_flag)也被重写为适当的值。
当从数据库中检索数据时有两种典型的访问方法,顺序扫描和B树索引扫描。顺序扫描通过扫描每个页面中的所有行指针顺序读取所有页面中的所有元组。B树索引扫描时,索引文件包含索引元组,每个元组由索引键和指向目标堆元组的TID组成。如果找到了正在查找的键的索引元组,PostgreSQL使用获取的TID值读取所需的堆元组。
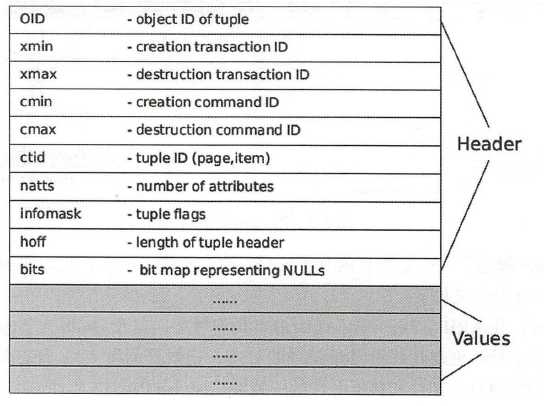
每个Tuple包含两部分的内容,一部分为HeapTupleHeader,用来保存Tuple的元信息,如图所示,包含该Tuple的OID、xmin、cmin等;另一部分为HeapTuple,用来保存Tuple的数据。
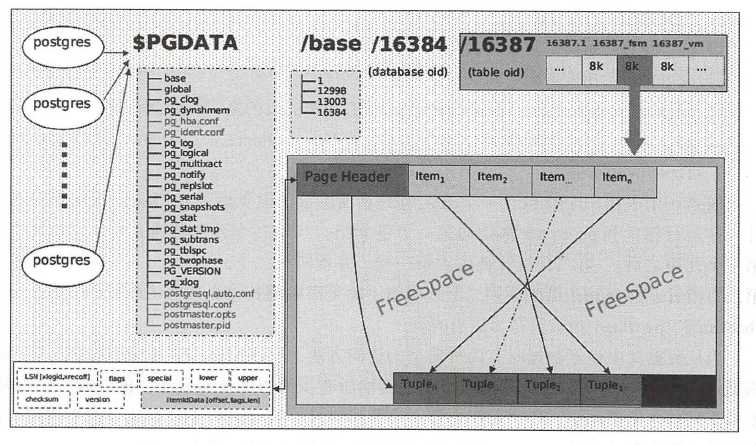
一个完整的文件布局:
3.6 控制文件
控制文件在数据库目录的global目录下($PGDATA/global/pg_control)。控制文件记录了数据库运行的一些重要信息。比如数据库id,是否open,wal的位置,checkpoint的位置,等等。
pg_controldata可以查看控制文件的内容:
$ pg_controldata $PGDATA
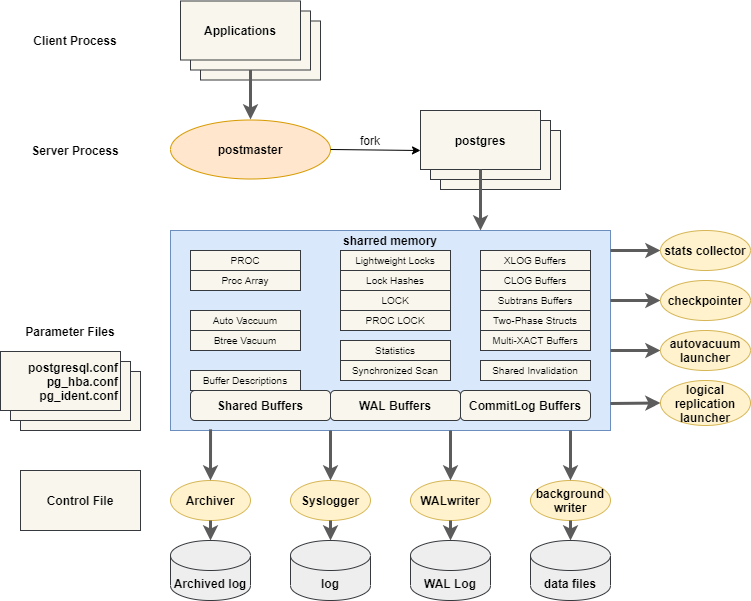
4. 进程
PostgreSQL是一用户一进程的客户端/服务器的应用程序。
4.1 Postmaster守护进程
管理后端的守护进程,默认监听UNIX Domain Socket和TCP/IP(Windows等,一部分的平台只监听TCP/IP)的5432端口,等待来自前端的的连接处理。监听的端口号可以在PostgreSQL的设置文件postgresql.conf中更改。
Postmaster就像一个处理客户端请求的调度中心。当客户端程序需要对数据库进行操作时,首先会发出一个起始消息给Postmaster进行请求。Postmaster将根据这个起始消息中的信息对客户端的身份进行验证,如果身份验证通过,Postmaster就为该客户端新建(fork)一个服务进程Postgres。随后Postmaster将与客户端的交互工作转交给Postgres服务进程,由Postgres来完成客户端所需要的数据库操作。
没有fork的windows平台,通过createProcess()生成新的进程。和fork不同的是,父进程的数据不会被继承过来,需要利用共享内存把父进程的数据继承过来。
Postmaster也负责管理整个系统范围的操作,例如中断等操作,Postmaster本身不进行这些操作,它只是指派一个子进程在适当的时间去处理它们。同时它要在数据库崩溃的时候重启系统。Postmaster进程在起始时会建立共享内存和信号库,Postmaster及其子进程的通信就通过共享内存和信号来实现。这种多进程设计使得整个系统的稳定性更好,即使某个后台进程崩溃也不会影响系统中其他进程的工作,Postmaster只需要重置共享内存即可从单个后台进程的崩溃中恢复。
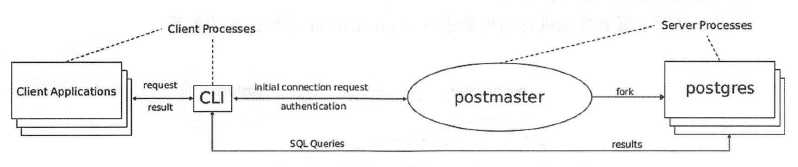
postmaster(守护进程)主要职责有:
- 数据库的启停
- 监听客户端连接
- 为每个客户端连接fork单独的postgres服务进程
- 当postgres服务进程出错时进行修复
- 管理数据文件
- 管理与数据库运行相关的辅助进程
PostgreSQL使用基于消息的协议用于前端和后端(服务器和客户端)之间通信。通信都是通过一个消息流进行,消息的第一个字节标识消息类型,后面跟着的四个字节声明消息剩下部分的长度,该协议在TCP/IP和Unix域套接字上实现。服务器作业之间通过信号和共享内存通信,以保证并发访问时的数据完整性。
用户可以使用postmaster、postgres或者pg_ctl命令启动Postmaster。
4.2 Postgres Process
postgres进程根据pg_hba.conf定义的安全策略来判断是否允许进行连接,根据策略,会拒绝某些特定的IP及网络,或者也可以只允许某些特定的用户或者对某些数据库进行连接。
Postgres会接受前端过来的查询,然后对数据库进行检索,把结果返回,有时也会对数据库进行更新。更新的数据同时还会记录在事务日志里面(PostgreSQL称为WAL日志),WAL日志的作用是,当停电的时候,服务器宕机,重新启动的时候进行恢复处理的时候使用。另外,把日志归档保存起来,可在需要进行数据恢复的时候使用。在PostgreSQL9.0以后,通过把WAL日志传送给其它的数据库,可以实时地进行数据库复制。
4.3 Background Writer Process
Background Writer Process(BGWriter)在适当的时间点把共享内存上的缓存写到磁盘。通过这个进程,可以防止在检查点的时候(checkpoint),大量写磁盘而导致性能恶化,使得服务器可以保持比较稳定的性能。BGWriter起来以后就一直常驻内存,但是并非一直在工作,它会在工作一段时间后进行休眠,休眠的时间间隔通过postgresql.conf里面的参数bgwriter_delay设置,默认是200微秒。
BGWriter的另外一个重要的功能是定期执行checkpoint。
执行checkpoint的时候,会把共享内存上的缓存内容写入数据库文件,使得内存和文件的状态一致。这样,可以在系统崩溃的时候可以缩短从WAL恢复的时间,另外也可以防止WAL无限的增长。 可以通过postgresql.conf的checkpoint_segments、checkpoint_timeout指定执行检查点的时间间隔。
BGWriter是把共享内存中的脏页写到磁盘上的进程。它的作用有两个:一是定期把脏数据从内存缓冲区刷出到磁盘中,减少查询时的阻塞;二是在定期执行检查点时需要把所有脏页写出到磁盘,通过BGWriter预先写出一些脏页,可以减少设置检查点时要进行的IO操作,使系统的IO负载趋向平稳。BGWriter是PostgreSQL8.0以后新加的特性,它的机制可以通过postgresql.conf文件中以”bgwriter_”开头的参数来控制:
- bgwriter_delay:backgroud writer进程连续两次flush数据之间的时间的间隔。默认值是200,单位是毫秒。
- bgwriter_lru_maxpages:BGWriter每次写的最多数据量,默认值是100,单位buffers。如果脏数据量小于该数值时,写操作全部由BGWriter完成;反之,大于该值时,大于的部分将有server process进程完成。设置该值为0时表示禁用BGWriter,完全由server process来完成;配置为-1时表示所有脏数据都由BGWriter来完成,不包括checkpoint操作。
- bgwriter_lru_multiplier:这个参数表示每次往磁盘写数据块的数量,当然该值必须小于bgwriter_lru_maxpages。设置太小时需要写入的脏数据量大于每次写入的数据量,这样剩余需要写入磁盘的工作需要server process进程来完成,将会降低性能;设置太大说明写入的脏数据量多于当时所需buffer的数量,方便了后面再次申请buffer的工作,同时可能出现IO的浪费。该参数的默认值是2.0。bgwriter的最大数据量计算方式:
1000/bgwriter_delay*bgwriter_lru_maxpages*8K=最大数据量 - bgwriter_flush_after:数据页大小达到bgwriter_flush_after时触发BgWriter,默认是512KB。
4.4 WAL Writer Process
WAL Writer Process(WALwriter)把共享内存上的WAL缓存在适当的时间点写入磁盘,可以减轻后端进程在写WAL缓存时的压力,提高性能。另外,非同步提交设为true的时候,可以保证在一定的时间间隔内,把WAL缓存上的内容写入WAL日志文件。
预写式日志WAL(Write Ahead Log,也称为Xlog)的目的是确保对数据文件的修改必须发生在修改已经记录到日志之后,也就是先写日志后写数据。使用这种机制可以避免数据频繁的写入磁盘,可以减少磁盘I/O。数据库在宕机重启后可以运用这些WAL日志来恢复数据库。postgresql.conf文件中与WALwriter相关的参数如下:
- wal_level:控制wal存储的级别。wal_level决定有多少信息被写入到WAL中。 默认值是最小的(minimal),其中只写入从崩溃或立即关机中恢复的所需信息。replica 增加 wal 归档信息 同时包括只读服务器需要的信息。(9.6 中新增,将之前版本的 archive 和 hot_standby 合并)。
- logical 主要用于logical decoding 场景
- fsync:该参数直接控制日志是否先写入磁盘。默认值是ON(先写入),表示更新数据写入磁盘时系统必须等待WAL的写入完成。可以配置该参数为OFF,表示更新数据写入磁盘完全不用等待WAL的写入完成。
- synchronous_commit:参数配置是否等待WAL完成后才返回给用户事务的状态信息。默认值是ON,表明必须等待WAL完成后才返回事务状态信息;配置成OFF能够更快地反馈回事务状态。
- wal_sync_method:WAL写入磁盘的控制方式,默认值是fsync,可选用值包括open_datasync、fdatasync、fsync_writethrough、fsync、open_sync。open_datasync和open_sync分别表示在打开WAL文件时使用O_DSYNC和O_SYNC标志;fdatasync和fsync分别表示在每次提交时调用fdatasync和fsync函数进行数据写入,两个函数都是把操作系统的磁盘缓存写回磁盘,但fdatasync只写入文件的数据部分,而fsync还会同步更新文件的属性;fsync_writethrough表示在每次提交并写回磁盘会保证操作系统磁盘缓存和内存中的内容一致。
- full_page_writes:表明是否将整个page写入WAL。
- wal_buffers:用于存放WAL数据的内存空间大小,系统默认值是64K,该参数还受wal_writer_delay、commit_delay两个参数的影响。
- wal_writer_delay:WALWriter的写间隔时间,默认值是200毫秒,如果时间过长可能造成WAL缓冲区的内存不足;时间过短将会引起WAL的不断写入,增加磁盘I/O负担。
- commit_delay:表示一个已经提交的数据在WAL缓冲区中存放的时间,默认值是0毫秒,表示不用延迟;设置为非0值时事务执行commit后不会立即写入WAL中,而仍存放在WAL缓冲区中,等待WALWriter周期性地写入磁盘。
- wal_writer_flush_after:
- commit_siblings:表示当一个事务发出提交请求时,如果数据库中正在执行的事务数量大于commit_siblings值,则该事务将等待一段时间(commit_delay的值);否则该事务则直接写入WAL。系统默认值是5,该参数还决定了commit_delay的有效性。
- wal_writer_flush_after:当脏数据超过阈值时,会被刷出到磁盘。
4.5 Archive Process
Archive process(PgArch)把WAL日志转移到归档日志里。如果保存了基础备份以及归档日志,即使实在磁盘完全损坏的时候,也可以恢复数据库到最新的状态。
类似于Oracle数据库的ARCH归档进程,不同的是ARCH是吧redo log进行归档,PgArch是把WAL日志进行归档。WAL日志会被循环使用,也就是说,旧的WAL日志会被新产生的日志覆盖,PgArch进程就是为了在覆盖前把WAL日志备份出来。归档日志的作用是为了数据库能够使用全量备份和备份后产生的归档日志,从而让数据库回到过去的任一时间点。PG从8.X版本开始提供的PITR(Point-In-Time-Recovery)技术,就是运用的归档日志。
PgArch进程通过postgresql.conf文件中的如下参数进行:
- archive_mode:表示是否进行归档操作,可选择为off(关闭)、on(启动)和always(总是开启),默认值为off(关闭)。
- archive_command:由管理员设置的用于归档WAL日志的命令。在用于归档的命令中,预定义变量“%p”用来指代需要归档的WAL全路径文件名,“%f”表示不带路径的文件名(这里的路径都是相对于当前工作目录的路径)。每个WAL段文件归档时将调用archive_command所指定的命令。当归档命令返回0时,PostgreSQL就会认为文件被成功归档,然后就会删除或循环使用该WAL段文件。否则,如果返回一个非零值,PostgreSQL会认为文件没有被成功归档,便会周期性地重试直到成功。
- archive_timeout:表示归档周期,在超过该参数设定的时间时强制切换WAL段,默认值为0(表示禁用该功能)。
4.6 Stats Collector Process
Stats Collector Process(PgStat)是统计信息的收集进程。收集好统计表的访问次数,磁盘的访问次数等信息。收集到的信息除了能被autovaccum利用,还可以给其他数据库管理员作为数据库管理的参考信息。
PgStat进程是PostgreSQL数据库的统计信息收集器,用来收集数据库运行期间的统计信息,如表的增删改次数,数据块的个数,索引的变化等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。postgresql.conf文件中与PgStat进程相关的参数,如下:
- track_activities:表示是否对会话中当前执行的命令开启统计信息收集功能,该参数只对超级用户和会话所有者可见,默认值为on(开启)。
- track_counts:表示是否对数据库活动开启统计信息收集功能,由于在AutoVacuum自动清理进程中选择清理的数据库时,需要数据库的统计信息,因此该参数默认值为on。
- track_io_timing:定时调用数据块I/O,默认是off,因为设置为开启状态会反复的调用数据库时间,这给数据库增加了很多开销。只有超级用户可以设置。
- track_functions:表示是否开启函数的调用次数和调用耗时统计。
- track_activity_query_size:设置用于跟踪每一个活动会话的当前执行命令的字节数,默认值为1024,只能在数据库启动后设置。
- stats_temp_directory:统计信息的临时存储路径。路径可以是相对路径或者绝对路径,参数默认为pg_stat_tmp,设置此参数可以减少数据库的物理I/O,提高性能。此参数只能在postgresql.conf文件或者服务器命令行中修改。
4.7 Logger Process
把PostgreSQL的活动状态写到日志信息文件(并非事务日志),在指定的时间间隔里面,对日志文件进行rotate.
4.8 Autovacuum Launcher Process
Autovacuum Launcher Process是由Postmaster启动的进程。它是不可以启动自己的。这样可以提高系统的可靠性。
在PostgreSQL数据库中,对数据进行UPDATE或者DELETE操作后,数据库不会立即删除旧版本的数据,而是标记为删除状态。这是因为PostgreSQL数据库具有多版本的机制,如果这些旧版本的数据正在被另外的事务打开,那么暂时保留他们是很有必要的。当事务提交后,旧版本的数据已经没有价值了,数据库需要清理垃圾数据腾出空间,而清理工作就是AutoVacuum进程进行的。postgresql.conf文件中与AutoVacuum进程相关的参数有:
- autovacuum:是否启动系统自动清理功能,默认值为on。
- log_autovacuum_min_duration:这个参数用来记录 autovacuum 的执行时间,当 autovaccum 的执行时间超过 log_autovacuum_min_duration参数设置时,则autovacuum信息记录到日志里,默认为 “-1”, 表示不记录。
- autovacuum_max_workers:设置系统自动清理工作进程的最大数量。
- autovacuum_naptime:设置两次系统自动清理操作之间的间隔时间。
- autovacuum_vacuum_threshold和autovacuum_analyze_threshold:设置当表上被更新的元组数的阈值超过这些阈值时分别需要执行vacuum和analyze。
- autovacuum_vacuum_scale_factor和autovacuum_analyze_scale_factor:设置表大小的缩放系数。
- autovacuum_freeze_max_age:设置需要强制对数据库进行清理的XID上限值。
- autovacuum_vacuum_cost_delay:当autovacuum进程即将执行时,对 vacuum 执行 cost 进行评估,如果超过 autovacuum_vacuum_cost_limit设置值时,则延迟,这个延迟的时间即为 autovacuum_vacuum_cost_delay。如果值为 -1, 表示使用 vacuum_cost_delay 值,默认值为 20 ms。
- autovacuum_vacuum_cost_limit:这个值为autovacuum 进程的评估阀值, 默认为 -1, 表示使用 “vacuum_cost_limit ” 值,如果在执行autovacuum 进程期间评估的cost 超过autovacuum_vacuum_cost_limit, 则 autovacuum 进程则会休眠。
Autovacuum Worker Process进程实际执行vacuum的任务。有时候会同时启动多个vacuum进程。
4.9 Wal Sender / Wal Receiver
Wal Sender 进程和Wal Receiver进程是实现PostgreSQL复制(streaming replication)的进程。Wal Sender进程通过网络传送WAL日志,而其他PostgreSQL实例的Wal Receiver进程则接收相应的日志。Wal Receiver进程的PostgreSQL(也称为Standby)接受到WAL日志后,在数据库上还原,生成一个和Wal Sender的PostgreSQL(也称为Master)完全一样的数据库。
4.10 CheckPoint Process
检查点是系统设置的事务序列点,设置检查点保证检查点前的日志信息刷到磁盘中。
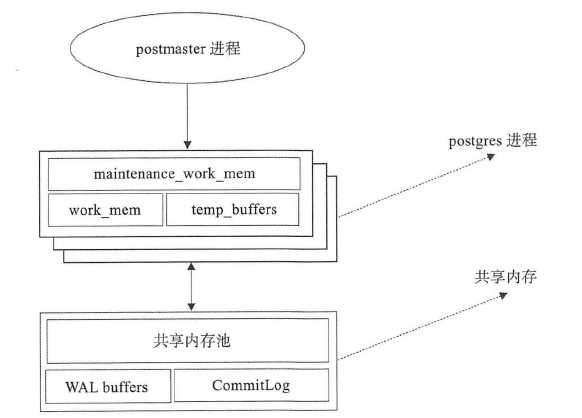
5. 内存结构
5.1 本地内存
本地内存由每个后端服务进程分配以供自己使用,当后端服务进程被fork时,每个后端进程为查询分配一个本地内存区域。本地内存由三部分组成: work_mem、maintenance_work_mem 和temp_buffers。
– work mem :当使用ORDER BY 或DISTINCT操作对元组进行排序时会使用这部分内存。
– maintenance_work_mem : 维护操作,例如VACUUM 、REINDEX 、CREATE INDEX等操作使用这部分内存。
– temp_buffers :临时表相关操作使用这部分内存。
5.2 共享内存
共享内存在PostgreSQL服务器启动时分配,由所有后端进程共同使用。共享内存主要由三部分组成:
– Shared Buffer : PostgreSQL将表和索引中的页面从持久存储装载到这里,并直接操作它们。
– WAL Buffer: WAL文件持久化之前的缓冲区。
– CommitLog Buffer : PostgreSQL在Commit Log中保存事务的状态,并将这些状态保留在共享内存缓冲区中,在整个事务处理过程中使用。