Oracle Lab – Dataguard19c Installation
1.创建数据库
请参考实验一和实验二。
1.1.环境准备
主机名:dg1
IP地址:192.168.1.180
数据库:OTTER
DB_UNIQUE_NAME: OTTER_PR
主机名:dg2
IP地址:192.168.1.181
数据库:OTTER
DB_UNIQUE_NAME: OTTER_DR
Oracle Database 19.3
OS: CentOS Linux 7.9
vi /etc/hosts
192.168.1.180 dg1 dg1.lab.com
192.168.1.181 dg2 dg2.lab.com
1.2.oracle用户profile
vi /home/oracle/.bash_profile
export ORACLE_SID=OTTER
export ORACLE_BASE=/oracle/app/oracle
export ORACLE_HOME=/oracle/app/oracle/product/12.2.0.3
export TNS_ADMIN=¥ORACLE_HOME/network/admin
export PATH=¥ORACLE_HOME/bin:¥PATH
export LD_LIBRARY_PATH=¥ORACLE_HOME/lib:¥LD_LIBRARY_PATH
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
export DISPLAY=localhost:10.0
export PS1='[\u@\h:`pwd`]$'
alias sqlplus='rlwrap sqlplus'
alias rman='rlwrap rman'
只需要在dg1创建数据库。
1.3.静默方式
dbca -silent -createDatabase \
-templateName General_Purpose.dbc \
-gdbName OTTER -sid OTTER \
-sysPassword oracle \
-systemPassword oracle \
-emConfiguration NONE \
-datafileDestination "/oradata/data" \
-storageType FS \
-redoLogFileSize 50 \
-characterSet AL32UTF8 \
-ignorePreReqs
1.4.图形方式
请参考 Oracle 安装实验
1.5.配置Listener
listener.ora
LISTENER=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.138.180)(PORT=1521)))
SID_LIST_LISTENER =
(SID_LIST=
(SID_DESC=
(GLOBAL_DBNAME=OTTER)
(SID_NAME=OTTER)
)
)
tnsnames.ora
OTTER_PR =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = dg1)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = OTTER)
)
)
OTTER_DR =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = dg2)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = OTTER)
)
)
sqlnet.ora
NAMES.DIRECTORY_PATH=(TNSNAMES,EZCONNECT)
ADR_BASE = /oracle/app/oracle
2.DataGuard解析
2.1.DataGuard简介
Data Gurad 通过日志同步机制保证Standby数据库和Primary数据库之间的同步,这种同步可以是实时,延时,同步,异步多种形式。Data Gurad常用于异地容灾和小企业的高可用性方案,也可以在Standby数据库上配置执行只读查询,从而分散Primary数据库的性能压力。
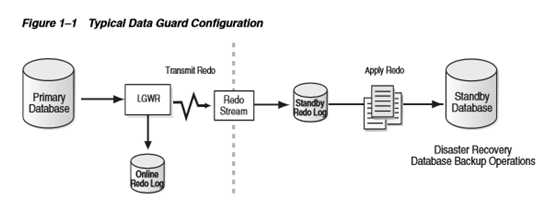
2.2.Active Data Guard (ADG)
Active Data Guard(ADG)是ORACLE 11g企业版的新特性,需要单独的License.可以打开Physical Standby至read only模式,并实时应用redo log,同时用户可以在Standby上进行查询、报表等操作。实时读写分离,以此来分担primary DB的压力。这类似Logical Data Guard备用数据库的功能,但是,数据同步的效率更高、对硬件的资源要求更低。
Database只读模式下允许的操作:
•SELECT操作,包括需要大量临时段的查询
•ALTER SESSION,ALTER SYSTEM
•SET ROLE
•调用Procedure
•使用DBLINK写数据到远程数据库
•通过DBLINK调用远程数据库的Procedure
•在事务级别读一致性使用SET TRANSACTION READ ONLY
•执行复杂的查询,如:GROUPING SET,WITH查询语句等
Database只读模式下不允许的操作:
•任何DML或DDL操作
•访问本地序列的查询
•对本地临时表的DML操作
如何检查当前是否启用ADG?
SQL> select database_role ,open_mode from v$database;
DATABASE_ROLE OPEN_MODE
------------------ --------------------
PHYSICAL STANDBY READ ONLY WITH APPLY
2.3.Physical Standby和Logical Stanbdy
Physical Standby使用的是Media Recovery 技术,基于块对块的与主数据库同样的磁盘数据库结构,提供主数据库的完全一致的物理拷贝。数据库方案,包括索引,是相同的。物理备用数据库与主数据库保持同步通过重做应用,恢复从主数据库收到的重做数据并将重做应用到物理备用数据库。这种方式没有数据类型的限制。Physical Standby数据库只能在Mount 状态下进行恢复,也可以是打开,但只能以只读方式打开,并且打开时不能执行恢复操作。
Logical Standby使用的是Logminer 技术,从主库接收redo log,将redo log中的数据转换成SQL 语句,然后执行这些SQL语句,Logical Standby不支持所有数据类型,可以在视图DBA_LOGSTDBY_UNSUPPORTED 中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致。Logical Standby数据库可以在恢复的同时进行读写操作。
Physical Standby: Redo Apply
Logical Standby: SQL Apply
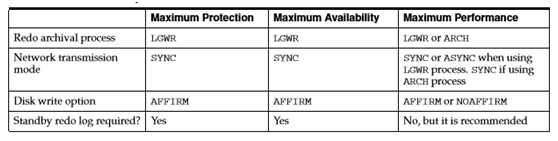
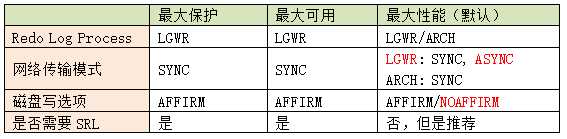
2.4.三种模式
最大可用模式Maximum Availability
This protection mode provides the highest level of data protection that is possible without compromising the availability of a primary database. Transactions do not commit until all redo data needed to recover those transactions has been written to the online redo log and to the standby redo log on at least one synchronized standby database. If the primary database cannot write its redo stream to at least one synchronized standby database, it operates as if it were in maximum performance mode to preserve primary database availability until it is again able to write its redo stream to a synchronized standby database.
最大可用模式: 事务只有在所有相关日志都被传输到至少一个Standby端日志的时候,才可以正式提交。但是,如果Primary在传输日志的过程中,发现所有standby端都不能进行传输,模式会退化到最大性能模式(Maximum Performance)工作方式。应该说,Maximum Availability是一种自适应的保护模式,当出现问题的时候,DG会退而求其次,确保Primary主库事务进行。
最大性能模式(Maximum Performance)
This protection mode provides the highest level of data protection that is possible without affecting the performance of a primary database. This is accomplished by allowing transactions to commit as soon as all redo data generated by those transactions has been written to the online log. Redo data is also written to one or more standby databases, but this is done asynchronously with respect to transaction commitment, so primary database performance is unaffected by delays in writing redo data to the standby database(s).
This protection mode offers slightly less data protection than maximum availability mode and has minimal impact on primary database performance.
This is the default protection mode.
最大性能模式: 在不影响主库工作情况下,可以提供的最高数据保护级别。当事务进行提交的时候,主库不会去确认日志是否写入到备库中,更不会确认是否被apply。这种方式下,主库的工作性能是不会受到备库提交应用的影响。当然,这种保护模式会有一定的事务数据丢失,但是绝对不会出现数据误提交的情况。
最大性能模式是默认的保护模式。当我们完成了DG安装之后,就自动进入了Maximum Performance模式。
最大保护模式(Maximum Protection)
This protection mode ensures that no data loss will occur if the primary database fails. To provide this level of protection, the redo data needed to recover a transaction must be written to both the online redo log and to the standby redo log on at least one synchronized standby database before the transaction commits. To ensure that data loss cannot occur, the primary database will shut down, rather than continue processing transactions, if it cannot write its redo stream to at least one synchronized standby database.
Transactions on the primary are considered protected as soon as Data Guard has written the redo data to persistent storage in a standby redo log file. Once that is done, acknowledgment is quickly made back to the primary database so that it can proceed to the next transaction. This minimizes the impact of synchronous transport on primary database throughput and response time. To fully benefit from complete Data Guard validation at the standby database, be sure to operate in real-time apply mode so that redo changes are applied to the standby database as fast as they are received. Data Guard signals any corruptions that are detected so that immediate corrective action can be taken.
最大保护模式: 是完全HA架构理想中的事务模式。如果Primary数据库进行一个事务,连带Standby数据库也要同步进行操作。如果由于网络、执行模式等原因,Standby不能够跟上主库的操作,那么主库会放弃事务,并且强制停库。
保护模式的三种和数据库之间传输日志的机制是密切相关的。主要体现是否同步传输Redo日志和对日志进行确认两个方面。三种日志模式的配置,以Log_Archive_Config参数配置为基础。
select protection_mode, protection_level from v$database;
当保护模式更改顺序:
maximize protection —> maximize availability —-> maximize performance
当在把dataguard的保护级别按这上面的顺序减低的时候, 不需要primary库在mount状态,
primary在open状态就可以直接执行保护模式更改命令。
2.5.AFFIRM和NOAFFIRM
Controls whether redo transport services use synchronous or asynchronous I/O to write redo data to disk
■ AFFIRM—specifies that all disk I/O to archived redo log files and standby redo log files is performed synchronously and completes successfully before the log writer process continues.
■ NOAFFIRM—specifies that all disk I/O to archived redo log files and standby redo log files is performed asynchronously; the log writer process on the primary database does not wait until the disk I/O completes before continuing.
Usage Notes:
■ These attributes are optional. If neither the AFFIRM nor the NOAFFIRM attribute is specified, the default is NOAFFIRM.
■ The AFFIRM attribute specifies that all disk I/O to archived redo log files and standby redo log files is performed synchronously and must complete before the log writer process continues. The AFFIRM attribute:
- Is one of the required attributes to ensure no data loss will occur if the primary database fails.
- Can be specified with either the LOCATION or SERVICE attributes for archival operations to local or remote destinations.
- Can potentially affect primary database performance, as follows:
When you specify the LGWR and AFFIRM attributes, the log writer process synchronously writes the redo data to disk, control is not returned to the user until the disk I/O completes, and online redo log files on the primary database might not be reusable until archiving is complete.
When you specify the ARCH and AFFIRM attributes, ARCn processes synchronously write the redo data to disk, the archival operation might take longer, and online redo log files on the primary database might not be reusable until archiving is complete.
When you specify the ASYNC and AFFIRM attributes, performance is not affected.
******************************************************
Note:When the primary database is in the maximum protection or maximum availability mode, destinations defined with the LGWR and SYNC attributes are automatically placed in AFFIRM mode.
******************************************************
■ The NOAFFIRM attribute specifies that all disk I/O to archived redo log files and standby redo log files is performed asynchronously; the log writer process on the primary database does not wait until the disk I/O completes before continuing.
■ The AFFIRM and NOAFFIRM attributes apply only to archived redo log files and standby redo log files on remote standby destinations and have no effect on disk I/O for the primary database’s online redo log files.
■ These attributes can be specified with either the LOCATION attribute for local destinations or with the SERVICE attribute for remote destinations.
2.6.SYNC和ASYNC
使用LGWR 进程的SYNC 方式
1)Primary Database 产生的Redo 日志要同时写到日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(LGWR Network Server Process),再由LNSn进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
2)LGWR 必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database 上的事务才能提交,这也是SYNC的含义所在。
3)Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中。
4)Primary Database的日志切换也会触发Standby Database 上的日志切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP 进程复归档日志。
因为Primary Database 的Redo 是实时传递的,于是Standby Database 端可以使用两种恢复方法:
- 实时恢复(Real-Time Apply): 只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
-
归档恢复: 对Standby Redo Log 归档完成时才触发恢复。
Primary Database默认使用ARCH进程,如果使用LGWR进程必须明确指定。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。 示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR SYNC NET_TIMEOUT=30' scope=both;
使用LGWR进程的ASYNC 方式
使用LGWR SYNC方法的可能问题在于,如果日志发送给Standby Database过程失败,LGWR进程就会报错。也就是说Primary Database的LGWR 进程依赖于网络状况,有时这种要求可能过于苛刻,这时就可以使用LGWR ASYNC方式。 它的工作机制如下:
1) Primary Database 一端产生Redo 日志后,LGWR 把日志同时提交给日志文件和本地LNS 进程,但是LGWR进程只需成功写入日志文件就可以,不必等待LNSn进程的网络传送成功。
2) LNSn进程异步地把日志内容发送到Standby Database。多个LNSn进程可以并发发送。
3) Primary Database的Online Redo Log 写满后发生Log Switch,触发归档操作,也触发Standby Database对Standby Database对Standby Redo Log 的归档;然后触发MRP或者LSP 进程恢复归档日志。
因为LGWR进程不会等待LNSn进程的响应结果,所以配置LGWR ASYNC方式时不需要NET_TIMEOUT参数。示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR ASYNC ' scope=both;
LGWR ASYNC 模式插入一万条数据commit 过程是如何呢?是一条一条redo 信息的传给备库还是所有十万条数据插入完才开始传呢?
首先最大可用和最大保护都是sync的,最大可用在当sync不可用时,临时相当于降成最大性能。所以在这2种情况下一般都是commit下就传输一下。
最大性能下,如果是arch传输则是传的归档。如果是lgwr的话,则是把disk上的online redo读取出来再传输,个人觉得当然肯定不是commit下,就去读取下online redo log传输了。可以实验一下。
最大性能模式(max perfermance)的机制就是异步的。如果用LGWR 传输redo,我还用指定ASYNC吗?不用指定,默认就是ASYNC。
2.7.Redo Log传输方式ARCn和LGWR
Primary Database 运行过程中,会源源不断地产生Redo 日志,这些日志需要发送到Standy Database。这个发送动作可以由Primary Database 的LGWR 或者ARCH进程完成,不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法。选择哪个进程对数据保护能力和系统可用性有很大区别。
The ARC or LGWR attributes were deprecated in favor of always using the more efficient LNS process to perform redo shipment.
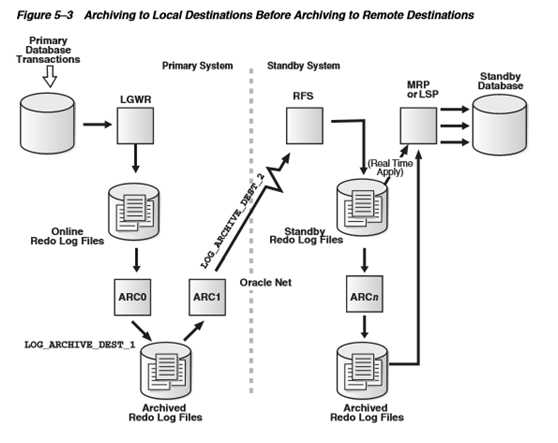
2.7.1.日志发送-使用ARCH进程
Primary Database默认使用ARCH进程。
1)Primary Database 不断产生Redo Log,这些日志被LGWR 进程写到online redo log file。
2)当一组online redo log file被写满后,会发生Log Switch,并且会触发本地归档,本地归档位置是采用 LOG_ARCHIVE_DEST_1=’LOCATION=/path’ 这种格式定义的。
例如:alter system set log_archive_dest_1 = ‘LOCATION=/u01/arch’ scope=both;
3)完成本地归档后,online redo log file就可以被覆盖重用。
4)ARCH 进程通过Oracle Net 把Archive Log发送给Standby Database的RFS(Remote File Server)进程。发送的目标(Standby Database)由Log_archive_dest_n参数指定。
例如:log_archive_dest_2=’SERVICE DEMO_DR …..’
5)Standby Database 端的RFS (Remote File Server)进程把接收的日志写入到SRL。SRL被写满后,ARCn 写入Archive Log。如果是实时应用,SRL同时被传送给MRP进程。
6)同步数据:物理备库,是Redo Apply方式,由MRP(Managed Recovery Process)进程以介质恢复的方式在Standby Database上应用这些日志。 逻辑备库,是SQL Apply方式,由LSP进程转换成SQL语句,执行SQL语句,在Standby Database上应用这些日志。
创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库。
2.7.2.日志发送-使用LGWR进程SYNC
1)Primary Database 产生的Redo Log要同时写到Online Redo Log File和Oracle Net。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(LGWR Network Server Process),再由LNSn(LGWR Network Server process)进程把Redo Log通过Oracle Net发送给远程的RFS,每个远程RFS对应一个LNS进程,多个LNS进程能够并行工作。
2)LGWR 必须等待写入本地Online Redo Log File操作和通过网络传送到RFS都成功,Primary Database 上的事务才能提交,这也是SYNC的含义所在。
3)Standby Database的RFS(Remote File Server)进程把接收到的Redo Log写入到Standby Redo Log中。
4)Primary Database的Redo Log切换也会触发Standby Database 上的Redo Log切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP 进程恢复归档日志。
5)Primary Database 的Redo 是实时传递的,Standby Database 端可以使用两种恢复方法:
实时恢复(Real-Time Apply):只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
归档恢复:在完成对Standby Redo Log 归档才触发恢复。
Primary Database默认使用ARCH进程,如果使用LGWR进程必须指定。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。
例如:
log_archive_dest_2 = 'SERVICE=DEMO_DR LGWR SYNC NET_TIMEOUT=30' scope=both;
使用LGWR SYNC方法的缺点是,如果日志发送给Standby Database过程失败,LGWR进程就会报错。也就是说Primary Database的LGWR 进程依赖于网络状况,有时这种要求可能过于苛刻。
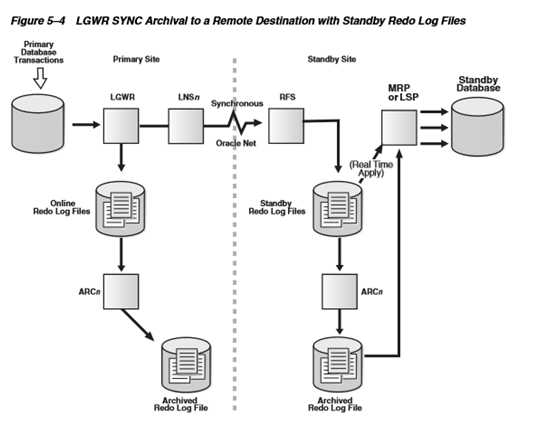
2.7.3.日志发送-使用LGWR进程ASYNC
1) Primary Database 产生Redo Log后,LGWR 把Redo Log同时写入Online Redo Log File和提交给和本地LNS 进程,但是LGWR进程只需成功写入Online Redo Log File,Primary Database 上的事务就可以提交,不必等待LNSn进程的网络传送成功。
2) LNSn进程异步地把日志内容发送到Standby Database。多个LNSn进程可以并行发送。
3) Primary Database的Online Redo Log File写满后发生Log Switch,触发归档操作,同时也触发Standby Database对Standby Redo Log 的归档;然后触发MRP或者LSP 进程恢复归档日志。
因为LGWR进程不会等待LNSn进程的响应结果,所以配置LGWR ASYNC方式时不需要NET_TIMEOUT参数。
例如:
log_archive_dest_2 = 'SERVICE=DEMO_DR LGWR ASYNC';
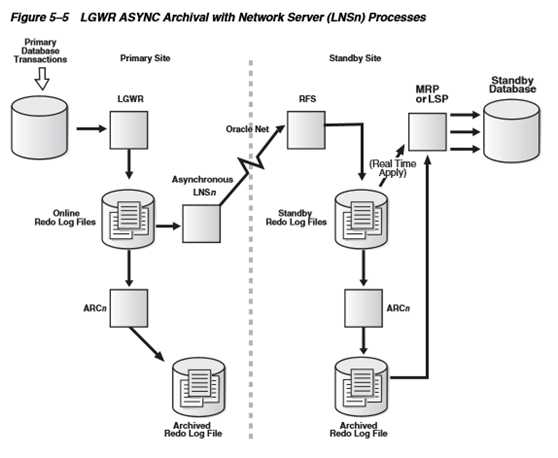
2.7.4.日志接收
Standby Database 的RFS(Remote File Server)进程接收到日志后,把日志写到Standby Redo Log。当Primary Database发生日志切换时,也会触发Standby Database上的Standby Redo Log 的日志切换,并把这个Standby Redo Log 归档。
Redo Log接收后存放的位置:
1)如果配置了STANDBY_ARCHIVE_DEST 参数,则使用该参数指定的目录。
2)如果某个LOG_ARCHIVE_DEST_n 参数明确定义了VALID_FOR=(STANDBY_LOGFILE,*)选项,则使用这个参数指定的目录。
3)如果数据库的COMPATIBLE参数大于等于10.0,则选取任意一个LOG_ARCHIVE_DEST_n的值。
4)如果备库利用standby redo log在备库端自动归档,那么归档日志将会被放置到LOG_ARCHIVE_DEST_n
如果备库是利用主库的ARCH进程传输过来的归档,那么将会被放置到STANDBY_ARCHIVE_DEST
如果STANDBY_ARCHIVE_DEST 和 LOG_ARCHIVE_DEST_n 参数都没有配置,使用缺省的STANDBY_ARCHIVE_DEST参数值,这个缺省值是$ORACLE_HOME/dbs/arc.
2.7.5.日志应用
Redo Log Apply服务,就是在Standby Database上重演Primary Database Redo Log,从而实现两个数据库的数据同步。根据Standby Database重演Redo Log方式的不同,可分为物理Standby(Physical Standby)和逻辑Standby(Logical Standby)。
Physical Standby 使用的是Media Recovery 技术,在数据块级别进行恢复,这种方式没有数据类型的限制,可以保证两个数据库完全一致。 Physical Standby数据库只能在Mount 状态下进行恢复,也可以是打开,但只能已只读方式打开,并且打开时不能执行恢复操作。
Logical Standby 使用的是Logminer 技术,通过把Redo Log内容还原成SQL 语句,然后SQL引擎执行这些语句,Logminer Standby不支持所有数据类型,可以在视图DBA_LOGSTDBY_UNSUPPORTED 中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致。 Logical Standby数据库可以在恢复的同时进行读写操作。
Standby数据库的相关进程读取接收到的Redo数据(可能来自于Standby端的归档文件,也可能来自于Standby Redo logs),再将其写入Standby数据库。
根据Redo Apply发生的时间可以分成两种:
一种是实时应用(Real-Time Apply),每当日志被写入Standby Redo Log时,就会触发恢复,使用这种方式的好处在与可以减少数据库切换(Switchover 或者Failover)的时间,因为切换时间主要用在剩余日志的恢复上。这种方式必须配置Standby Redo Log。
另一种是归档时应用,这种方式在Primary Database发生Redo Log切换,触发Standby Database 归档操作,归档完成后触发恢复。这也是默认的恢复方式。
如何启用实时应用?
如果是Physical Standby,可以使用下面命令启用Real-Time Apply:
alter database recover managed standby database using current logfile;
如果是Logical Standby,可以使用下面命令启用Real-Time Apply:
alter database start logical standby apply immediate;
查看是否使用Real-Time apply:
SQL> select DEST_ID, DEST_NAME, STATUS, RECOVERY_MODE from v$archive_dest_status;
DEST_ID DEST_NAME STATUS RECOVERY_MODE
---------- ------------------------------ --------- ----------------------------------
1 LOG_ARCHIVE_DEST_1 VALID IDLE
2 LOG_ARCHIVE_DEST_2 VALID MANAGED REAL TIME APPLY WITH QUERY
3 LOG_ARCHIVE_DEST_3 INACTIVE IDLE
4 LOG_ARCHIVE_DEST_4 INACTIVE IDLE
5 LOG_ARCHIVE_DEST_5 INACTIVE IDLE
6 LOG_ARCHIVE_DEST_6 INACTIVE IDLE
7 LOG_ARCHIVE_DEST_7 INACTIVE IDLE
8 LOG_ARCHIVE_DEST_8 INACTIVE IDLE
9 LOG_ARCHIVE_DEST_9 INACTIVE IDLE
10 LOG_ARCHIVE_DEST_10 INACTIVE IDLE
11 LOG_ARCHIVE_DEST_11 INACTIVE IDLE
12 LOG_ARCHIVE_DEST_12 INACTIVE IDLE
13 LOG_ARCHIVE_DEST_13 INACTIVE IDLE
14 LOG_ARCHIVE_DEST_14 INACTIVE IDLE
15 LOG_ARCHIVE_DEST_15 INACTIVE IDLE
16 LOG_ARCHIVE_DEST_16 INACTIVE IDLE
17 LOG_ARCHIVE_DEST_17 INACTIVE IDLE
18 LOG_ARCHIVE_DEST_18 INACTIVE IDLE
19 LOG_ARCHIVE_DEST_19 INACTIVE IDLE
20 LOG_ARCHIVE_DEST_20 INACTIVE IDLE
21 LOG_ARCHIVE_DEST_21 INACTIVE IDLE
22 LOG_ARCHIVE_DEST_22 INACTIVE IDLE
23 LOG_ARCHIVE_DEST_23 INACTIVE IDLE
24 LOG_ARCHIVE_DEST_24 INACTIVE IDLE
25 LOG_ARCHIVE_DEST_25 INACTIVE IDLE
26 LOG_ARCHIVE_DEST_26 INACTIVE IDLE
27 LOG_ARCHIVE_DEST_27 INACTIVE IDLE
28 LOG_ARCHIVE_DEST_28 INACTIVE IDLE
29 LOG_ARCHIVE_DEST_29 INACTIVE IDLE
30 LOG_ARCHIVE_DEST_30 INACTIVE IDLE
31 LOG_ARCHIVE_DEST_31 INACTIVE IDLE
31 rows selected.
SQL> select process,status,thread#,sequence#,client_pid from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE# CLIENT_PID
--------- ------------ ---------- ---------- ----------------------------------------
ARCH CLOSING 1 16 11408
DGRD ALLOCATED 0 0 N/A
DGRD ALLOCATED 0 0 N/A
ARCH CONNECTED 0 0 11414
ARCH CLOSING 1 17 11416
ARCH CLOSING 1 15 11418
LNS WRITING 1 18 12017
ARCH CLOSING 1 17 11420
DGRD ALLOCATED 0 0 N/A
9 rows selected.
2.8.Standby Redo Log(SRL)
SRL 其实用于备库,为主库配置SRL是为了以后主从切换后使用。需要在备库创建SRL, 主库克隆到备库时,SRL会一起克隆到备库。
主库发生日志切换时,Remote File System(RFS)进程把primary上的ORL写到standby的SRL,同时standby归档上一个SRL

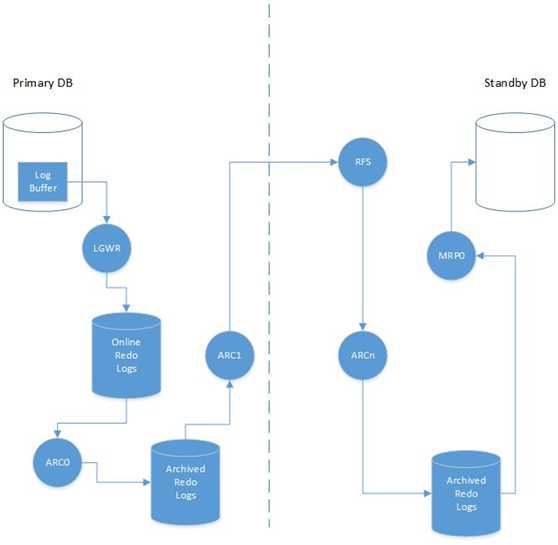
2.9.后台进程
后台进程有两种类型:
Log Transport Service 进程: LGWR, ARCH, FAL, LNSn
Log Apply Service 进程: RFS, ARCH, MRP, LSP
LGWR, ARCH and LNSn
LGWR – Writes the redo data from redo buffer to Online redo log. If the redo transport to standby server is SYNC then it signals the LNS to send the redo data to the standby server and waits for the acknowledgement from LNS that the data is sent. The data is transmitted to the Standby server by the LNS through ftp mechanism. The RFS process in the standby server receives the redo data. Then LNS sends acknowledgement back to the LGWR in the primary server. The primary server then issues Commit Complete.
If the redo transport to standby server is ASYNC then the redo is transmitted to the standby server from the Archived Redo log instead of Online redo log. Again the redo data is transmitted by the LNS.
LGWR and ARCH will never send data to standby redo server they only signal LNS to send the redo data. Transmitting the redo data from one server to another is done by some mechanism like FTP which both LGWR and ARCH cannot handle.
LGWR
LGWR搜集事务日志,并且更新联机日志。在同步模式下,LGWR将redo信息直接传送到备库中的RFS进程,主库在继续进行处理前需要等待备库的确认。在非同步情况下,也是直接将日志信息传递到备库的RFS进程,但是不等待备库的确认信息主库进程可以继续运行处理。
ARCH
ARCHn或者是一个SQL session执行了一个归档操作,为了恢复的需要,创建了一个联机日志的拷贝。ARCHn进程可以在归档的同时,传递日志流到备库的RFS进程。该进程还用于前瞻性检测和解决备库的日志不连续问题(GAP)。
FAL
Fetch Archive Log 只有物理备库才有该进程。
FAL进程提供了一个client/server的机制,用来解决检测在主库产生的连续的归档日志,而在备库接受的归档日志不连续的问题。 该进程只有在需要的时候才会启动,而当工作完成后就关闭了,因此在正常情况下,该进程是无法看见的。 我们可以设置通过LGWR,ARCH进程去传递日志到备库,但是不能两个进程同时传送。
RFS
Remote File Server
RFS进程主要用来接受从主库传送过来的日志信息。对于物理备用数据库而言,RFS进程可以直接将日志写进备用重做日志(Standby Redo Log),也可以直接将日志信息写到归档日志中。为了使用备库重做日志,必须创建它们,一般和主库的联机日志大小以及组一样。
该进程是standby库接受来自primary库LGWR进程触发的redo信息并且写入到standby redo log中。RFS进程无疑是要和其他进程配合的,也就是传输的进程。我们知道触发同步可能由ARCH或者是LGWR进程触发的,两者是不同的。如果是LGWR进程触发,那10g前的话也是由LGWR进程负责传输redo信息,RFS进程负责接收redo信息写入standby redo log中,10g之后则由LNSn进程完成;如果是ARCH进程触发,也就是归档日志传输的话,那就是由ARCH进程负责传输,RFS进程负责接收,然后写入指定的归档位置,然后再应用的。
LNSn
LGWR触发以后真正负责传输的进程,包括初始化网络I/O等一些列功能。
ARCH
只对物理备库,ARCH进程归档备库重做日志,这些日志以后将被MPR进程应用到备库。
MRP
Managed Recovery Process
该进程只针对物理备库。该进程应用归档日志到备库,直接通过standby redo log或者是归档日志(取决于模式不同)来进行的一个数据恢复。 如果我们使用SQL语句启用该进程ALTER DATABASE RECOVER MANAGED STANDBY DATABASE,那么前台进程将会做恢复。如果加上disconnect语句,那么恢复过程将在后台进程,发出该语句的进程可以继续做其他的事情。
LSP
Logical Standby Process
只有逻辑备库才会有该进程。LSP进程控制着应用归档日志到逻辑备用数据库。将redo信息转换成sql语句再恢复到数据库。
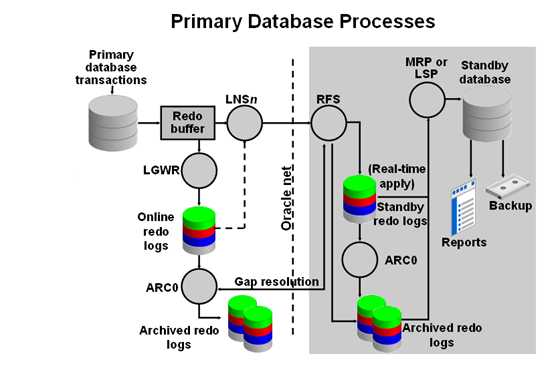
2.10.Archive Gap
当Primary Database的某些日志没有成功发送到Standby Database,就会发生归档裂缝(Archive Gap)。
缺失的这些日志就是裂缝(Gap)。 Data Guard能够自动检测,解决归档裂缝,不需要DBA的介入。需要配置FAL_CLIENT, FAL_SERVER 这两个参数。(FAL: Fetch Archive Log)。
FAL(Fetch Archive Log)过程是Standby Database主动发起的“取” Redo Log的过程,Standby Database 就是FAL_CLIENT, 从FAL_SERVER中取这些Gap, 10g中,这个FAL_SERVER可以是Primary Database,也可以是其他的Standby Database。
例如:FAL_SERVER=’DEMO_PR1, DEMO_DR1, DEMO_DR2′;
FAL_CLIENT和FAL_SERVER两个参数都是Oracle Net Name。 FAL_CLIENT 通过网络向FAL_SERVER发送请求,FAL_SERVER通过网络向FAL_CLIENT发送缺失的日志。但是这两个连接不一定是一个连接。因此FAL_CLIENT向FAL_SERVER发送请求时,会携带FAL_CLIENT参数值,用来告诉FAL_SERVER应该向哪里发送缺少的日志。这个参数值也是一个Oracle Net Name,这个Name是在FAL_SERVER上定义的,用来指向FAL_CLIENT.
当然,除了自动地解决Archive Gap,DBA 也可以手工解决Archive Gap。
1)查看是否有日志GAP:
SQL> SELECT UNIQUE THREAD#, MAX(SEQUENCE#) OVER(PARTITION BY THREAD#) LAST FROM V$ARCHIVED_LOG;
SQL> SELECT THREAD#, LOW_SEQUENCE#, HIGH_SEQUENCE# FROM V$ARCHIVE_GAP;
2)如果有,则拷贝过来:
scp
3)手工的注册这些日志:
SQL> ALTER DATABASE REGISTER LOGFILE 'PATH';
2.11.Force Logging
alter database force logging;
select force_logging from v$database;
有一些DDL语句可以通过指定NOLOGGING子句的方式避免写REDO(目的是提高速度,某些时候确实有效)。指定数据库为Force Logging模式后,数据库将会记录除临时表空间或临时回滚段外所有的操作,而忽略类似NOLOGGING之类的指定参数。如果在执行Force Logging时有NOLOGGING之类的语句在执行,那么Force Logging会等待,直到这类语句全部执行。
Force Logging是作为固定参数保存在控制文件中,因此其不受重启之类操作的影响(只执行一次即可),如果想取消,可以通过ALTER DATABASE NO FORCE LOGGING语句关闭强制记录。
Force Logging并不比一般的Logging 记录的日志多,数据库在Force Logging状态下,Nologging选项将无效,因为Nologging将破坏dataguard的可恢复性。Force Logging强制数据库在任何状态下必须记录日志。
2.12.STANDBY NOLOGGING
主要是为了加快主库loading数据
Standby Nologging for Data Availability,即loading操作的commit会被delay,直到所有的standby都apply data为止。
SQL> ALTER DATABASE SET STANDBY NOLOGGING FOR DATA AVAILABILITY;
Standby Nologging for Load Performance,这种模式和上一种类似,但是会在load数据的时候,遇到网络瓶颈时,先不发送数据,这就保证了loading性能,但是丢失了数据。丢失的数据,会从primary中再次获取。
SQL> ALTER DATABASE SET STANDBY NOLOGGING FOR LOAD PERFORMANCE;
3.参数解析
译自Oracle Data Guard 11g Handbook Page 78 – Page 88
3.1.REMOTE_LOGIN_PASSWORD
三个选项,none(不实用密码文件,dg中不使用)exclusive(单个实例使用单个密码文件)或者shared(多个实例可以使用单个密码文件)。Data Guard配置中所有DB服务器SYS密码相同。
3.2.DB_UNIQUE_NAME
因为DG中所有数据库的DB_NAME是一样的, 引入DB_UNIQUE_NAME, 用来区分DG配置中的每一个数据库角色。这个参数需要在所有的数据库中配置,同时需要重启数据库才能生效。
3.3.CONTROL_FILES
备库的控制文件可以是自动创建的,或者手动创建的。 如果使用RMAN Duplicate 方式创建备库, control files 是自动创建的。如果使用冷备方式创建备库,控制文件需要手动的从主库拷贝过来。
使用RMAN Duplicate 方式创建备库,需要指定备用控制文件的位置,例如:
duplicate target database for standby from active database
spfile
set control_files='/u01/app/oracle/oradata/DGDEMO/controlfile/control_01.ctl'
3.4.AUDIT_FILE_DEST
指定备库Audit文件的路径。
3.5.DB_CREATE_FILE_DEST
如果在备库中使用了ASM,需要定义这个参数:
set db_create_file_dest=+DATA
3.6.db_file_name_convert和log_file_name_convert
这两个参数用于RMAN duplicate 命令。
Standby数据库的Data Files路径与Primary数据库Data Files路径不一致时,可以通过设置DB_FILE_NAME_CONVERT参数的方式让其自动转换。该参数值应该成对出现,前面的值表示转换前的形式,后面的值表示转换后的形式。
例如:
duplicate target database for standby from active database
spfile
set db_file_name_convert='/u01/app/oracle/oradata/DEMO_PR','/u01/app/oracle/oradata/DEMO_DR';
set log_file_name_convert='/arcdata/DEMO_PR','/arcdata/DEMO_DR'
上面的命令会将如下数据文件名:
/u01/app/oracle/oradata/DEMO_PR/sysaux.dbf
转换为:
/u01/app/oracle/oradata/DEMO_DR/sysaux.dbf
LOG_FILE_NAME_CONVERT的功能和DB_FILE_NAME_CONVERT参数相同,只是转换的是日志文件,包括ORL文件和任何SRL文件。
从库通过主库的备份恢复控制文件—>恢复控制文件时,oracle查看从库参数文件中的db_file_name_convert和log_file_name_convert参数—->将主库保存数据文件、联机日志的路径转换成从库保存数据文件、联机日志的路径—->生成从库的控制文件
建议主库备库都配置db_file_name_convert和log_file_name_conver,无论如何switchover,数据文件和redo log文件的位置都都不会出错。
如果主库和从库的data file和redo log file文件路径一样,需要设置dummy参数,否则RMAN会出错。
set log_file_name_convert=’dummy’,’dummy’
3.7.LOG_ARCHIVE_MAX_PROCESSES
参数的默认值是2,太小了。在主库中,归档进程负责归档已经写满的在线日志文件(Online Redo Log)并作为重做流(Redo Steam)传输到备用数据库来完成间隔处理(Gap);在备库中,归档进程则是负责归档备库日志文件(Standby Redo Log)并且将其转发到它的级联备用数据库中。(注:级联备用数据库是指当前备用数据库的下一级备库,即Standby的Standby,从这里可以看出不管什么数据库角色,归档进程的工作的内容都是一样的:
- 归档日志文件
- 转发日志文件到Standby
在主库中,有一个归档进程仅限于对在线日志文件提供服务,无权与备库进行通信,这个特殊的ARCH进程被称为“专用ARCH进程”,而其他归档进程是可以完成这两样功能的。当归档进程向备库发送归档日志文件,就无法协助归档ORL文件了;尽管归档进程的主要指令是“先归档在线日志文件,再处理主备库的间隔,”但是在最坏的情况下,仍然可能只有一个归档进程在进行归档任务。如果没有足够的归档进程,在慢速网络,主备库间出现大的日志间隔的时候,你可能就只有那么一个进程在处理日志文件。这里就会有个非常棘手的问题,那就是如果这个时候你所有的日志文件都已经写满,生产库就停滞了,直到其中的一个文件被归档。在10g中引入了多线程间隔处理特性(MAX_CONNECTIONS),它允许DG使用多个归档进程向备用数据库发送单个日志文件,这就意味这我们会使用更多的归档日志进程;因此,这个参数至少要设置4,最大值为30。
duplicate target database for standby from active database
spfile
set log_archive_max_processes='5'
备库专用ARCH进程: 备库中也有一个“备库专用ARCH进程”,在物理备用中,这个专用ARCH进程是没有归档SRL文件功能的。
使用多个归档进程时需要注意,虽然增加归档进程可以减少生产环境中断的可能,但是大量的归档进程会增加主备切换(Switchover)的时间,因为这需要唤醒所有的归档进程并使他们退出。可以通过在执行切换前将该参数调低来避免这种情况。此外,在11g中引入了新的流式功能(Streaming Capability),如果正好主备库间的日志间隔非常大,过多的归档进程传输会把整个网络带宽充满。
3.8.fal_server和fal_client
设置这两个参数可以用来解决Archive Gaps。一旦产生了gap,fal_client会自动向fal_server请求传输gap的archivelog。设置了这2个参数,就不需要在产生gap时手动向standby注册归档日志了。fal_client设置为数据库自身的service name,fal_server设置为远端数据库的service name。fal_server可以设置多个值,用逗号隔开。
例如:
主库中设置:
fal_server=’OTTER_DR’ #远端的TNS名
fal_client=’OTTER_PR’ #自己的TNS 名
备库中设置:(反过来的,否则主备切换会出问题)
fal_server=’OTTER_PR’ #远端的TNS名
fal_client=’OTTER_DR’ #自己的TNS 名
主、从两端都配置FAL_SERVER和FAL_CLIENT是为了切换方便。
FAL_SERVER
FAL(Fetch Archive Log)功能只用于物理备库,它能够使得物理备库在发现问题时,从DG配置中的一个数据库(主库或备库)中获取缺失的归档日志文件,有时我们又称它为被动间隔处理(reactive gap resolution),不过FAL技术已经得到了极大的增强以至于现在几乎不需要再定义FAL参数了。伴随着9iR2版本引入的主动间隔处理(proactive gap resolution)技术的使用,几乎物理或逻辑备库上任何类型的间隔请求都可以由主库上的ping进程来处理了。
在主库的正常工作过程中,归档进程(被指定为ping进程)会轮流查询所有的备库来寻找redo间隔,与此同时处理任何应用进程发来的未解决的间隔请求。当物理备库需要从主库之外的数据库中获得间隔文件时就可以使用FAL技术。举个例子,比如物理备库现在需要进行间隔处理,但是主库无法访问,那么它需要去请求其他的备库来完成间隔处理,为此,将FAL_SERVER参数定义为指向主库或者任意备库的TNS标识符列表。例如:
fal_server=’OTTER_PR, OTTER_DR02′
FAL_CLIENT
FAL客户端就是发起间隔请求的数据库的TNS名称,间隔请求的接收方(FAL_SERVER)需要这个TNS名称以使得FAL服务器上的数据库可以反向连接至请求方。在备库OTTER_DR02上,发送OTTER_DR01作为客户端名称以便OTTER_PR和OTTER_DR02库可以连接回OTTER_DR01库发送缺失的归档日志文件。例如:
fal_client=’ OTTER_DR01′
OTTER_DR01必须在FAL服务器的TNS文件中定义以使得DG能够成功连接备库。和FAL_SERVER参数一样,FAL_CLIENT参数只对物理备库有效。
3.9.STANDBY_FILE_MANAGEMENT
如果为AUTO则表示primary库的数据文件发生修改(新增,重命名),则在standby库会自动做相应的更改。如果是MANUAL,则表示手动。
该参数只用于物理备库。该参数设置成AUTO的时,主库中添加和删除数据文件的同时,备库中也会自动的进行相应的更改。只要备库中顶级目录存在或能够借助于DB_FILE_NAME_CONVERT参数找到,那么DG将会执行DDL语句在备库中创建数据文件。它甚至会尽可能的创建缺失的子目录。默认情况下,这个参数的值为MANUAL,这意味着备库上的应用进程不会创建新的数据文件,需要手动创建它们。
需要对物理备库上的ORL文件执行定义操作的时候,需要将该参数设置成MANUAL。SRL文件能够在不改这个参数的情况下添加。如果需要在物理备库上添加或删除在线日志文件(比如因为主库上发生了更改),需要将这个参数动态的设置成MANUAL,执行DDL操作,然后再还原成AUTO值,无需重启备库。
3.10.LOG_ARCHIVE_CONFIG
该参数定义了可用的DB_UNIQUE_NAME参数值列表。
名称的配置顺序没有要求。
例如:
set log_archive_config='dg_config=(PrimaryDemo,StandbyDemo)'
3.11.LOG_ARCHIVE_DEST_n
log_archive_dest_n:默认值为”.ORACLE最多支持把日志文件归档到10个地方,n从1到10,归档地址可以为本地磁盘,或者网络设备。
如果设置了db_recovery_file_dest,默认的情况下归档日志都是存放在db_recovery_file_dest目录下。不要同时设置log_archive_dest或者log_archive_dest_n。
如果设置了log_archive_dest,就不能设置log_archive_dest_n,也不能设置db_recovery_file_dest,不过可以设log_archive_duplex_dest。
如果设置了log_archive_dest_n,就不能设置log_archive_dest,也不建议设置db_recovery_file_dest。归档日志也不会存放在db_recovery_file_dest,而是存放在log_archive_dest_n指定的目录下。
该参数仅在Primary数据库中有效,指定primary传输redo log到该参数定义的standby database上。定义redo log的传输方式(SYNC /ASYNC)以及传输目标,指定dataguard的数据保护级别。
例如:
Primary Site:
*.LOG_ARCHIVE_DEST_2='SERVICE=OTTER_DR LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES, PRIMARY_ROLE) DB_UNIQUE_NAME=OTTER_DR'
Standby Site: (switch over后生效)
*.LOG_ARCHIVE_DEST_2=' SERVICE=OTTER_PR LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES, PRIMARY_ROLE) DB_UNIQUE_NAME=OTTER_PR'
注意:
1. LOG_ARCHIVE_DEST_2参数里定义的service值,比如OTTER_DR,是tnsnames.ora文件里定义的Oracle Net名称。
2. LOG_ARCHIVE_DEST_2定义DB_UNIQUE_NAME的值,当前节点设置的均为另一端数据库的db_unique_name,例如Primary端,DB_UNIQUE_NAME=OTTER_DR
LOG_ARCHIVE_DEST_n参数有17个属性,所有这些属性都是用来设置主库到备库的重做日志传输的;其实你只需要设置其中的7个就可以让日志传输工作正常了;下面我们会先来介绍一下这7个属性并且用一些例子来展示一下它们的用法,然后我们再探讨一下其余的10个属性以及它们的使用场景和使用原因,我们建议不要设置其中的6个属性。
必须的属性: 1 – 7
可选属性: 8 – 13
不建议使用的属性:14 – 17
3.11.1.SERVICE
指定已经创建的备库的TNSNAMES描述符。
3.11.2.SYNC
指定使用同步方法传送重做数据。
3.11.3.ASYNC
指定使用异步方式发生重做数据。 默认值。这是”最大性能模式”下的日志传输方式。
3.11.4.NET_TIMEOUT
指定LGWR进程等待LNS进程响应的时间,如果这期间没有收到响应,则认为备库发生故障(failed),默认值是30秒,不过10-15可能会是更恰当的值,这取决于网络可靠性。不要将这个值设置为10以下,否则可能会在备库恢复正常后还是无法建立连接,这是因为重新连接备库的操作也会耗费几秒的时间;因此在这之前,我们需要做:
1. 停止旧的LNS进程
2. 启动新的LNS进程
3. 与备库建立连接
4. 检测并停止旧的RFS进程
5. 启动新的RFS进程
6. 选择并打开新的SRL
7. 初始化SR头(注:即备库的重做日志数据)
8. 响应LNS进程告知已经完成准备工作
所有这些操作完成后,LNS进程才会告诉LGWR进程备库已连接成功;如果这个过程耗费的时间超过了NET_TIMEOUT的值,那么LGWR会再次放弃备库;每次发生日志切换时都会进行这个重新连接动作。
3.11.5.REOPEN
该属性控制主库尝试重新连接已经发生故障的备库的等待时间,默认值是300(5分钟),这通常是大家抱怨在停止备库后主库不重连的原因。一般来说,测试的时候都会比较快;先shutdown abort备库,观察主库的alert日志看是否与备库断开连接,再启动备库,在主库中切换日志观察是否发生重连,这些操作会在5分钟内完成,所以如果手快,DG不会在第一次(或者更多次)日志切换时进行重连。这个属性旨在避免这种情况,即如果备库发生故障以后主库立即切换日志,这个时候的重连很有可能就会失败,因此可以考虑将这个属性设置成30秒甚至是15秒,这样DG会尽快的完成重连工作。
3.11.6.DB_UNIQUE_NAME
在参数LOG_ARCHIVE_DEST_n中使用这个属性需要同时设置LOG_ARCHIVE_CONFIG参数,否则DG将拒绝连接这个目标库;这个SERVICE名称是另一端数据库(也就是备库)的唯一名称。
必须同时在两端的数据库中将该唯一名称添加LOG_ARCHIVE_CONFIG参数中。当主库向备库发起连接时,它将发送自己的数据库唯一名称到备库,同时要求备库返回唯一名称。在备库中将会检查LOG_ARCHIVE_CONFIG参数,以确保主库的唯一名确实存在,如果不存在,连接请求将会被拒绝;如果存在,备库会把自己的唯一名返送回主库的LNS进程,如果返送的值和主库中该属性的值不匹配,连接就会被终止。
3.11.7.VALID_FOR
不配置这个属性DG也能正常的工作,不过还是建议配置。该参数的主要功能是定义何时使用目标参数LOG_ARCHIVE_DEST_n以及它作用于哪种类型的Redo Log File。
Both the primary and standby initialization parameters should be configured to support either the primary or standby role so that role reversals via switchover are seamless. To prevent the DBA from having to enable or defer archive destination depending on when that destination should be used, Oracle developed the VALID_FOR attribute. The VALID_FOR attribute is used to specify exactly when an archive destination is to be used and what types of redo logs are to be archived.
用来指定有效的传输内容(Redo Log),有两个参数值需要指定:REDO_LOG_TYPE和DATABASE_ROLE,即发送指定角色生成的指定类型的Redo Log File。
REDO_LOG_TYPE的合法值:
1. ONLINE_LOGFILE 仅在归档ORL文件时有效
2. STANDBY_LOGFILE 仅在归档SRL文件时有效
3. ALL_LOGFILES 无论是那种重做日志文件类型都有效
DATABASE_ROLE的合法值:
1. PRIMARY_ROLE 仅在主库中生效
2. STANDBY_ROLE 仅在备库中生效
3. ALL_ROLES 主备角色都有效
如果这两个参数的答复都是TRUE,VALID_FOR就会允许使用目标参数。目标参数会在VALID_FOR的上述两个子项都是TRUE的时候被使用。
例如:valid_for=(ONLINE_LOGFILES, PRIMARY_ROLE)
如果当前数据库是主库并且归档ORL文件,LOG_ARCHIVE_DEST_n内的属性设置就会生效。
VALID_FOR参数默认值是:VALID_FOR=(ALL_LOGFILES,ALL_ROLES)。
有了这个参数,我们就可以预定义DG中所有数据库的所有目标参数了,并其它们仅在VALID_FOR属性都是TRUE的时候生效,这样就没必要再在角色转换时启用和禁用目标了。
LOG_ARCHIVE_DEST_n最多可以设置9个目标,也就是说可以有最多9个备库。其实可以使用10个,不过一个是保留用做默认的本地归档目标的。
例如:
使用2号参数来添加一个位于曼彻斯特的最高可用的备库:
log_archive_dest_2='service=Matrix_DR0
SYNC REOPEN=15 NET_TIMEOUT=15
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix_DR0'
再添加一个位于纽瓦克市的备库作为3号参数,它的网络延迟比SYNC长,所以这里以异步模式来传输:
log_archive_dest_3='service=Matrix_DR1
ASYNC REOPEN=15
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix_DR1'
使用了DB_UNIQUE_NAME属性,所以还需要配置LOG_ARCHIVE_CONFIG参数:
log_archive_config='dg_config=(Matrix,Matrix_DR0,Matrix_DR1)'
逻辑Standby在默认情况下就处于OPEN READ WRITE模式,不仅有REDO数据而且还包含多种日志文件(Online Redologs、Archived Redologs及Standby Redologs)。
默认情况下,逻辑Standby数据库生成的归档文件和接收到的归档文件在相同的路径下,这既不便于管理,也极有可能带来一些隐患。建议对每个LOG_ARCHIVE_DEST_n参数设置合适的VALID_FOR属性。本地生成的归档文件和接收到的归档文件最好分别保存于不同路径下。
3.11.8.AFFIRM
这是使用SYNC方式的默认值。要求LNS进程等待RFS进程完成对SRL文件的直接I/O再返回成功消息,还要求是“最高可用”或”最大保护“模式;因为这个属性默认值,所以不需要设置;尽管在10g中可以为ASYNC方式指定这个属性,不过依然是没有理由的。实际上,它会拖慢LNS进程。在11g中,AFFIRM属性会被ASYNC目标忽略掉。
3.11.9.NOAFFIRM
如果没有特别指定,它会是ASYNC的默认值。用于“最大性能”模式;因为它是ASYNC的默认值,所以没有必要去指定它;并且如果你对SYNC目标设置NOAFFIRM属性,你的保护模式将违反规定,被标记为“已重新同步”状态。如果这是你唯一的SYNC备库,并且处于最大可用模式,那么你将无法进行零数据丢失的故障转移(Failover);如果这是你唯一的SYNC目标,并且处于最大保护模式,那么设置AFFIRM属性会让你的主库崩溃。
3.11.10.COMPRESSION
这个属性将启用对备用目标的高级压缩功能。默认情况下,这就意味着任何一个向该目标发送间隔日志的归档进程都会在发送时压缩归档。如果你设置了这个隐藏属性,那么它也会压缩当前发送的重做日志流。举个例子,假如设置这个隐藏参数,我们来对当前的两个目标库来添加COMPRESSION属性:
log_archive_dest_2='service=Matrix_DR0
LGWR SYNC REOPEN=15 NET_TIMEOUT=15
COMPRESSION=ENABLE
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix_DR0'
log_archive_dest_3='service=Matrix_DR1
LGWR ASYNC REOPEN=15
COMPRESSION=ENABLE
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix_DR1'
Matrix_DR0目标库仅在ARCH进程发送用于间隔处理的归档日志的时候才会使用压缩功能(并非用于同步SYNC的归档日志),而Matrix_DR1库自始至终都会压缩重做日志。这里说明日志并不会在磁盘也保持压缩状态,因为只会在传输过程中压缩日志,所以这些传输到备库的数据会被解压缩,然后再写入到SRL文件中。
3.11.11.MAX_CONNECTIONS
该属性在10gR2中被引入,它允许你指定用于备库间隔处理的归档进程的数量,在11g中已经弃用。不过如果你的版本是10g,你可以为它指定值1-5(默认值1);如果你设置的值大于1时,每当备库需要进行间隔处理的时候,主库将分配对应数量的归档进程用来发送归档日志文件,这些文件会被分片给这些归档进程,同时在网络中以并行流的形式传送,并在传送到备库时重新装配。例如:
log_archive_dest_2='service=Matrix_DR0
LGWR SYNC REOPEN=15 NET_TIMEOUT=15
MAX_CONNECTIONS=5
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix_DR0'
现在当Matrix_DR0库与主库断开连接的时候,主库的间隔处理进程将会对每一个确实的归档日志文件使用多个重做流。
不要在11g数据库中使用MAX_CONNECTIONS属性,这会降低日志传输的性能。
3.11.12.DELAY
这个属性并不是像大多数想象的那样延迟重做数据的传输,它只是用来指示备库目标的日志应用进程在DELAY属性设置的时间(秒)后应用重做数据。有了闪回数据库,这个属性几乎被弃用,尤其在自从我们建议在主备库中一直启用闪回数据库功能后。 如果你倾向于完成一些闪回数据库无法处理的任务量,则可能需要设置这个延迟时间。
如果指定了delay属性,但没有指定值,则默认是30分钟。注意,该属性并不是说延迟发送redo数据到standby,而是指明归档到standby后,开始应用的时刻。
取消延迟应用:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE NODELAY;
3.11.13.ALTERNATE
替代(ALTERNATE)目标最初的目的是,当正在归档ORL日志文件的磁盘空间已满时,保持数据库的持续运行。使用替代目标,你可以将归档日志文件重定向到一个备用磁盘中。有了闪回恢复区(自动管理空间),这个问题基本上消失了。
如果你有多个指向备库的网络路径,也可以为远程备用目标使用该属性。显然,你会在RAC环境中使用多个备库网络路径,但是这并不是ALTERNATE属性设计的初衷。对于有着多网卡的单实例或者RAC的环境,在备库的TNS描述符中使用connect-time failover会更简便。
从功能上来看,REOPEN与ALTERNATE是有一定重复的,不过需要注意一点,REOPEN属性比ALTERNATE属性的优先级要高,如果你指定REOPEN属性的值>0,则LGWR(或ARCn)进程会首先尝试向主归档目的地写入,直到达到最大重试次数,如果仍然写入失败,才会向ALTERNATE属性指定的路径写。
3.11.14.LOCATION
在10gR2之前,该属性必须指定一个文件位置用于归档进程存储归档日志文件,并且这在主库(对于ORL文件)和备库(对于SRL文件)确实是正确的。不过随着闪回恢复区和默认本地归档的使用,这个属性已经不再需要设置了。编号为10的目标将自动设置成闪回恢复区。
SQL> ARCHIVE LOG LIST
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
如果你正在使用闪回恢复区,并且你想定义一个本地目标,那么应该使用相同的语法:
log_archive_dest_1='location=USE_DB_RECOVERY_FILE_DEST
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix'
如果你还是不使用闪回恢复区,也可以使用旧的磁盘路径写法:
log_archive_dest_1='location=/u03/oradata/Matrix/arch/
valid_for=(ONLINE_LOGFILES,PRIMARY_ROLE)
db_unique_name=Matrix'
注意在如上的两种情况下,DB_UNIQUE_NAME都是指向你在其上定义了目标(注:也就是归档的存放位置)的数据库,而并非远程的备库。在上面的例子中,归档位置目标在Matrix库上,因此如果你要在这里使用DB_UNIQUE_NAME属性,就需要指定Matrix为DB_UNIQUE_NAME的值。
注意:如果使用闪回恢复区,就不要使用LOCATION属性来指定本地归档位置了。
3.11.15.MANDATORY
这是备库上最危险的属性之一。基本上,它规定ORL文件中的redo信息必须发送到该备库。如果redo信息无法发送到备库,那么主库中包含redo信息的这个ORL文件在成功发送到备库之前将无法被重用(reuse)。试想当备库无法访问并且主库中所有可用的日志文件都被遍历完了,那么生产系统就会停滞。当然,有一个本地目标是MANDATORY的以使文件存放在磁盘上,不过没有必要再设置另一个了。默认情况下,本地归档中的一个目标会被设置成MANDATORY。
注意:不要设置MANDATORY属性。
3.11.16.MAX_FAILURE
这个属性是所有属性中最遭人误解的一个。人们都倾向与认为这个属性表示LGWR进程在放弃发生故障的备库并继续产生日志之前,重新连接备库的次数。事实并非如此,如果你设置了该属性,实际是定义了LGWR尝试重连有故障的备库时,日志组切换的次数(注:原文写的更加让人容易误解,这里的意思就是切换一次日志,重连一次备库)。举例来说,如果将MAX_FAILURE的值设置成5,那么LGWR将会在它循环切换日志期间对故障备库总共发起5次连接请求,如果切换了5次还是无法连接到故障备库,那么LGWR将放弃重连,之后你要么等手动重新启用它或者等主库重启重新生效该属性。
注意:不要设置MAX_FAILURE属性。
3.11.17.NOREGISTER
默认情况下,DG要求任何发送到备库的redo数据都需要在归档至磁盘的时候完成对备库的注册。对于一个物理备库来说,意味着数据会被注册到备库的控制文件中;而对于逻辑备库来说,它意味着SQL Apply会在元数据中注册日志文件。DG不需要这个属性,它可以用在使用downstream特性的Streams目标库中。
注意:不要设置NOREGISTER属性。
3.12.LOG_ARCHIVE_DEST_STATE_n
是否允许REDO传输服务传输REDO数据到指定的路径。该参数共拥有4个属性值。
主库的日志发送是由log_archive_dest_n参数设置,log_archive_dest_state_n是和它相对应的开关参数。
- enable: Specifies that a valid log archive destination can be used for a subsequent archiving operation (automatic or manual). This is the default.
- defer: Specifies that valid destination information and attributes are preserved, but the destination is excluded from archiving operations until reenabled.
- alternate: Specifies that a log archive destination is not enabled but will become enabled if communications to another destination fail.
例如:
alter system set log_archive_dest_state_2 = 'defer';
3.13.STANDBY_ARCHIVE_DEST
对于 Standby_archive_dest 参数,实际上从10g R2 开始就感觉是可有可无了,在11g中、被标记为废弃,不再被支持。如果用了之后启动数据库会提示用了一个过时的参数。
3.14.switchover_status参数

4.DG搭建-冷备方式(关闭闪回)
4.1.创建数据库
dbca -silent -createDatabase \
-templateName General_Purpose.dbc \
-gdbName OTTER -sid OTTER \
-initParams db_unique_name=OTTER_PR,db_name=OTTER \
-sysPassword oracle \
-systemPassword oracle \
-emConfiguration NONE \
-datafileDestination "/oradata/data" \
-storageType FS \
-redoLogFileSize 50 \
-characterSet AL32UTF8 \
-ignorePreReqs
4.2.开启归档模式
启动到mount状态,设置归档日志路径
alter system set log_archive_dest_1='location=/oradata/arc';
打开归档模式
alter database archivelog;
修改日志文件命名格式:
alter system set log_archive_max_processes = 4;
alter system set log_archive_format = "arc_%t_%s_%r.dbf" scope=spfile;
alter database open;
查看状态
alter system switch logfile;
archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oradata/arc
Oldest online log sequence 3
Next log sequence to archive 5
Current log sequence 5
4.3.关闭闪回模式
默认是关闭的。
启动到mount状态
alter database flashback off;
alter system set db_recovery_file_dest='' scope=spfile sid='*';
select flashback_on from v$database;
show parameter db_recovery
4.4.开启force_loging
无论什么操作都进行redo的写入。
alter database force logging;
select force_logging from v$database;
The FORCE LOGGING option is the safest method to ensure that all the changes made in the database will be captured and available for recovery in the redo logs. Force logging is the new feature added to the family of logging attributes.
Before the existence of FORCE LOGGING, Oracle provided logging and nologging options. These two options have higher precedence at the schema object level than the tablespace level; therefore, it was possible to override the logging settings at the tablespace level with nologging setting at schema object level.
就是说,设置FORCE LOGGING 之后。本来一些可以指定nologging减少redo log的操作 ,虽然不报错,但事实上redo log还是都纪录了。
等于是,没法nologging了
4.5.主备库配置listener,tnsnames
主库,备库是一样的。参考4.4
备库从主库拷贝(scp命令)listener.ora, tnsnames.ora, sqlnet.ora 三个文件, 只需要修改listener.ora中的IP地址。其余两个文件完全一样。
主库和备库测试:
tnsping OTTER_DR
tnsping OTTER_PR
4.6.主库增加Standby Redo Logfile
SRL: Standby Redo Log
ORL: Online Redo Log
- SRL只有在备库中才起作用。备库中SRL相当于主库中的ORL,在主库发生日志切换时,Remote File System(RFS)进程把主库中的ORL写到备库中的SRL,同时备库归档上一个SRL。
- 每个SRL 至少要和主库的ORL 一样大,为了方便管理,Oracle 建议主备库的ORL 设置成一样的大小。
- SRL 至少要比主库的ORL多一组。 可以在主库查询v$log视图,来确定主库有多少组ORL。
公式:nx+1 (n为日志组数,x为节点数) - Oracle 建议在主库也创建SRL,在进行switchover 之后, 主库变为备库,不需要再创建SRL。
alter database add standby logfile group 4 '/oradata/data/OTTER/standby_redo04.dbf' size 50M;
alter database add standby logfile group 5 '/oradata/data/OTTER/standby_redo05.dbf' size 50M;
alter database add standby logfile group 6 '/oradata/data/OTTER/standby_redo06.dbf' size 50M;
alter database add standby logfile group 7 '/oradata/data/OTTER/standby_redo07.dbf' size 50M;
col status for a10
col member for a45
col IS_RECOVERY_DEST_FILE for a5
col status for a5
select group#, status, type, member, IS_RECOVERY_DEST_FILE from v$logfile order by 1;
GROUP# STATU TYPE MEMBER IS_RE
---------- ----- ------- --------------------------------------------- -----
1 ONLINE /oradata/data/OTTER/redo01.dbf NO
2 ONLINE /oradata/data/OTTER/redo02.dbf NO
3 ONLINE /oradata/data/OTTER/redo03.dbf NO
4 STANDBY /oradata/data/OTTER/standby_redo04.dbf NO
5 STANDBY /oradata/data/OTTER/standby_redo05.dbf NO
6 STANDBY /oradata/data/OTTER/standby_redo06.dbf NO
7 STANDBY /oradata/data/OTTER/standby_redo06.dbf NO
Check redo log size in MB:
select group#, bytes/1024/1024 MB from v$log;
GROUP# MB
---------- ---------------
1 50
2 50
3 50
Check Standby Redo Log size in MB:
select group#, bytes/1024/1024 MB from v$standby_log;
GROUP# MB
---------- ----------
4 50
5 50
6 50
7 50
Example of drop a log group
alter database drop standby logfile group 4;
alter database drop standby logfile group 5;
alter database drop standby logfile group 6;
alter database drop standby logfile group 7;
Database altered.
alter database add standby logfile group 4 '/oradata/data/OTTER/standby_redo04.dbf' size 200M;
alter database add standby logfile group 5 '/oradata/data/OTTER/standby_redo05.dbf' size 200M;
alter database add standby logfile group 6 '/oradata/data/OTTER/standby_redo06.dbf' size 200M;
alter database add standby logfile group 7 '/oradata/data/OTTER/standby_redo07.dbf' size 200M;
SELECT GROUP#, BYTES/1024/1024 MB FROM V$STANDBY_LOG;
GROUP# MB
---------- ----------
4 200
5 200
6 200
7 200
4.7.主库修改参数文件
create pfile from spfile;
cd $ORACLE_HOME/dbs
vi initOTTER.ora
*.audit_file_dest='/oracle/app/oracle/admin/OTTER/adump'
*.audit_trail='db'
*.compatible='19.0.0'
*.control_files='/oradata/data/OTTER/control01.ctl','/oradata/data/OTTER/control02.ctl'
*.db_block_size=8192
*.db_flashback_retention_target=1440
*.db_name='OTTER'
*.db_unique_name='OTTER_PR'
*.diagnostic_dest='/oracle/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=OTTERXDB)'
*.log_archive_dest_1='location=/oradata/arc valid_for=(online_logfile,primary_role) db_unique_name=OTTER_PR'
*.LOG_ARCHIVE_DEST_STATE_1=enable
*.log_archive_format='arc_%t_%s_%r.dbf'
*.log_archive_max_processes=5
*.log_archive_config='DG_CONFIG=(OTTER_PR,OTTER_DR)'
*.log_archive_dest_2='SERVICE=OTTER_DR LGWR ASYNC valid_for=(online_logfile,primary_role) db_unique_name=OTTER_DR'
*.LOG_ARCHIVE_DEST_STATE_2=enable
*.memory_target=1579m
*.nls_language='AMERICAN'
*.nls_territory='AMERICA'
*.open_cursors=300
*.processes=320
*.remote_login_passwordfile='EXCLUSIVE'
*.undo_tablespace='UNDOTBS1'
*.FAL_SERVER=OTTER_DR
*.FAL_CLIENT=OTTER_PR
*.DB_FILE_NAME_CONVERT='OTTER','OTTER'
*.LOG_FILE_NAME_CONVERT='OTTER','OTTER'
*.STANDBY_FILE_MANAGEMENT=AUTO
创建SPFILE
shutdown immediate;
startup pfile=initOTTER.ora
create spfile from pfile;
4.8.主库停库冷备
shutdown immediate
cd /oradata
tar -zcvf otter_pr.tar.gz *
4.9.主库生成standby controlfile
startup mount
alter database create standby controlfile as '/oradata/standby_control01.ctl';
4.10.拷贝主库文件到备库
拷贝冷备文件,Standby controlfile, 参数文件,密码文件
[oracle@dg2:/oradata]ls
[oracle@dg2:/oradata]scp oracle@dg1:/oradata/otter_pr.tar.gz .
[oracle@dg2:/oradata]scp oracle@dg1:/oradata/standby_control01.ctl .
[oracle@dg2:/oradata]ls
otter_pr.tar.gz standby_control01.ctl
[oracle@dg2:/oradata]cd $ORACLE_HOME/dbs
[oracle@dg2:/oracle/app/oracle/product/12.2.0.3/dbs]scp oracle@dg1:/oracle/app/oracle/product/12.2.0.3/dbs/initOTTER.ora .
[oracle@dg2:/oracle/app/oracle/product/12.2.0.3/dbs]scp oracle@dg1:/oracle/app/oracle/product/12.2.0.3/dbs/orapwOTTER .
4.11.备库修改参数文件
*.db_unique_name='OTTER_DR'
*.log_archive_dest_1='location=/oradata/arc valid_for=(online_logfile,primary_role) db_unique_name=OTTER_DR'
*.log_archive_dest_2='SERVICE=OTTER_PR LGWR ASYNC valid_for=(online_logfile,primary_role) db_unique_name=OTTER_PR'
*.FAL_SERVER=OTTER_PR
*.FAL_CLIENT=OTTER_DR
4.12.备库创建目录
[oracle@dg2:/oracle]$mkdir -p /oracle/app/oracle/admin/OTTER/adump
4.13.备库/etc/oratab
OTTER:/oracle/app/oracle/product/12.2.0.3:N
4.14.备库解压冷备文件
[oracle@dg2:/oracle]cd /oradata
[oracle@dg2:/oradata]tar -zxvf otter_pr.tar.gz
[oracle@dg2:/oradata]ls
arc data fra
4.15.启动备库到nomount恢复控制文件
[oracle@dg2:/oradata]env|grep ORA
ORACLE_SID=OTTER
ORACLE_BASE=/oracle/app/oracle
ORACLE_HOME=/oracle/app/oracle/product/12.2.0.3
startup nomount
[oracle@dg2:/oradata]rman target /
RMAN> startup nomount;
RMAN> restore controlfile from '/oradata/standby_control01.ctl';
Starting restore at 16-MAY-20
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=262 device type=DISK
channel ORA_DISK_1: copied control file copy
output file name=/oradata/data/OTTER/control01.ctl
output file name=/oradata/data/OTTER/control02.ctl
Finished restore at 16-MAY-20
4.16.启动备库
RMAN> alter database mount;
using target database control file instead of recovery catalog
Statement processed
RMAN> alter database open;
Statement processed
备库:
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- ---------- -------------------- --------------------
PHYSICAL STANDBY READ ONLY MAXIMUM PERFORMANCE RECOVERY NEEDED
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oradata/arc
Oldest online log sequence 9
Next log sequence to archive 11
主库:
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- ---------- -------------------- --------------------
PRIMARY READ WRITE MAXIMUM PERFORMANCE TO STANDBY
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oradata/arc
Oldest online log sequence 11
Next log sequence to archive 13
Current log sequence 13
4.17.备库启用应用redolog模式
SQL> recover managed standby database using current logfile disconnect from session;
Media recovery complete.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oradata/arc
Oldest online log sequence 0
Next log sequence to archive 0
Current log sequence 0
SQL> select sequence#,standby_dest,archived,applied,status from v$archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
12 NO YES YES A
11 NO YES YES A
主库:
SQL> select sequence#,standby_dest,archived,applied,status from v$archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
5 NO YES NO A
6 NO YES NO A
7 NO YES NO A
8 NO YES NO A
9 NO YES NO A
10 NO YES NO A
11 NO YES NO A
12 NO YES NO A
12 YES YES YES A
11 YES YES YES A
10 rows selected.
4.18.测试:插入数据
主库:
SQL> create table test(id varchar(10), name varchar(10));
Table created.
SQL> insert into test values('10','Tom');
1 row created.
SQL> commit;
Commit complete.
备库:
SQL> select * from test;
ID NAME
---------- ----------
10 Tom
4.19.测试:switch logfile
主库:
SQL> alter system switch logfile;
SQL> select sequence#,standby_dest,archived,applied,status from v$archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
5 NO YES NO A
6 NO YES NO A
7 NO YES NO A
8 NO YES NO A
9 NO YES NO A
10 NO YES NO A
11 NO YES NO A
12 NO YES NO A
12 YES YES YES A
11 YES YES YES A
13 NO YES NO A
13 YES YES YES A
备库:
SQL> select sequence#,standby_dest,archived,applied,status from v$archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
12 NO YES YES A
11 NO YES YES A
13 NO YES YES A
SQL> select process, pid, status, client_process from v$managed_standby;
PROCESS PID STATUS CLIENT_P
--------- ------------------------ ------------ --------
ARCH 7712 CONNECTED ARCH
DGRD 7714 ALLOCATED N/A
DGRD 7716 ALLOCATED N/A
ARCH 7719 CONNECTED ARCH
ARCH 7721 CLOSING ARCH
ARCH 7723 CLOSING ARCH
ARCH 7725 CONNECTED ARCH
RFS 7753 IDLE LGWR
RFS 7755 IDLE UNKNOWN
RFS 7757 IDLE Archival
RFS 7760 IDLE UNKNOWN
MRP0 8199 APPLYING_LOG N/A
12 rows selected.
4.20.测试:switchover
主库:
ALTER DATABASE COMMIT TO SWITCHOVER TO PHYSICAL STANDBY WITH SESSION SHUTDOWN;
shutdown abort;
startup mount;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
Database altered.
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PHYSICAL STANDBY MOUNTED MAXIMUM PERFORMANCE NOT ALLOWED
备库:
SQL> SELECT SWITCHOVER_STATUS FROM V$DATABASE;
SWITCHOVER_STATUS
--------------------
TO PRIMARY
SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO PRIMARY WITH SESSION SHUTDOWN;
Database altered.
SQL> ALTER DATABASE OPEN;
Database altered.
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- ---------- -------------------- --------------------
PRIMARY READ WRITE MAXIMUM PERFORMANCE TO STANDBY
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
5.RMAN duplicate方式(关闭闪回)
使用RMAN duplicate 命令可以创建一个具有不同DBID 的复制库。 RMAN 的duplicate 有2种方法实现:
1. Active database duplication
2. Backup-based duplication
Active database duplication 通过网络,直接copy target 库到auxiliary 库,然后创建复制库。 这种方法不需要先用RMAN 备份数据库,然后将备份文件发送到auxiliary端。
这个功能的优势很明显,尤其是对T级别的库。 因为对这样的库进行备份,然后将备份集发送到备库,再进行duplicate 的代价是非常大的。 备份要占用时间,还要占用存储空间,而且在网络传送的时候,还需要占用带宽和时间。所以Active database duplicate对大库的迁移非常有用。
19c上创建失败
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
Finished Duplicate Db at 18-MAY-20
12.2.0.1上创建成功
5.1.创建数据库
dbca -silent -createDatabase \
-templateName General_Purpose.dbc \
-gdbName OTTER -sid OTTER \
-initParams db_unique_name=OTTER_PR,db_name=OTTER \
-sysPassword oracle \
-systemPassword oracle \
-emConfiguration NONE \
-datafileDestination "/oradata/data" \
-storageType FS \
-redoLogFileSize 50 \
-characterSet AL32UTF8 \
-ignorePreReqs
5.2.开启归档模式
启动到mount状态 设置归档日志路径
alter system set log_archive_dest_1='location=/oradata/arc';
打开归档模式
alter database archivelog;
修改日志文件命名格式
alter system set log_archive_max_processes = 5;
alter system set log_archive_format = "arc_%t_%s_%r.dbf" scope=spfile;
alter database open;
查看状态
alter system switch logfile;
archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oradata/arc
Oldest online log sequence 3
Next log sequence to archive 5
Current log sequence 5
5.3.关闭闪回模式
默认是关闭的。
启动到mount状态
alter database flashback off;
alter system set db_recovery_file_dest='' scope=spfile sid='*';
select flashback_on from v$database;
show parameter db_recovery
5.4.开启force_loging
alter database force logging;
select force_logging from v$database;
5.5.主备库配置listener,tnsnames
主库,备库是一样的。参考4.4
备库从主库拷贝(scp命令)listener.ora, tnsnames.ora, sqlnet.ora 三个文件, 只需要修改listener.ora中的IP地址。其余两个文件完全一样。
主库和备库测试:
tnsping OTTER_DR
tnsping OTTER_PR
5.6.主库增加Standby Redo Logfile
SRL: Standby Redo Log
ORL: Online Redo Log
- SRL只有在备库中才起作用。备库中SRL相当于主库中的ORL,在主库发生日志切换时,Remote File System(RFS)进程把主库中的ORL写到备库中的SRL,同时备库归档上一个SRL。
- 每个SRL 至少要和主库的ORL 一样大,为了方便管理,Oracle 建议主备库的ORL 设置成一样的大小。
- SRL 至少要比主库的ORL多一组。 可以在主库查询v$log视图,来确定主库有多少组ORL。
公式:nx+1 (n为日志组数,x为节点数) - Oracle 建议在主库也创建SRL,在进行switchover 之后, 主库变为备库,不需要再创建SRL。
SQL> select group#, thread#, bytes/1024/1024 from vlog;
GROUP# THREAD# BYTES/1024/1024
---------- ---------- ---------------
1 1 50
2 1 50
3 1 50
alter database add standby logfile group 4 '/oradata/data/OTTER_PR/standby_redo04.dbf' size 50M;
alter database add standby logfile group 5 '/oradata/data/OTTER_PR/standby_redo05.dbf' size 50M;
alter database add standby logfile group 6 '/oradata/data/OTTER_PR/standby_redo06.dbf' size 50M;
alter database add standby logfile group 7 '/oradata/data/OTTER_PR/standby_redo07.dbf' size 50M;
col MEMBER for a50
SQL> select group#, status, type, member, IS_RECOVERY_DEST_FILE from v¥logfile order by 1;
GROUP# STATU TYPE MEMBER IS_RE
---------- ----- ------- --------------------------------------------- -----
1 ONLINE /oradata/data/OTTER_PR/redo01.dbf NO
2 ONLINE /oradata/data/OTTER_PR/redo02.dbf NO
3 ONLINE /oradata/data/OTTER_PR/redo03.dbf NO
4 STANDBY /oradata/data/OTTER_PR/standby_redo04.dbf NO
5 STANDBY /oradata/data/OTTER_PR/standby_redo05.dbf NO
6 STANDBY /oradata/data/OTTER_PR/standby_redo06.dbf NO
7 STANDBY /oradata/data/OTTER_PR/standby_redo07.dbf NO
SQL> select group#, bytes/1024/1024 MB from vlog;
GROUP# MB
---------- ----------
1 50
2 50
3 50
SQL> SELECT GROUP#, BYTES/1024/1024 MB FROM V¥STANDBY_LOG;
GROUP# MB
---------- ----------
4 50
5 50
6 50
7 50
5.7.主库参数设置
alter system set db_unique_name='OTTER_PR' scope=spfile;
alter system set db_file_name_convert=' /oradata/data/OTTER_DR',' /oradata/data/OTTER_PR' scope=spfile;
alter system set log_file_name_convert=' /oradata/data/OTTER_DR',' /oradata/data/OTTER_PR' scope=spfile;
alter system set fal_server='OTTER_DR' scope=spfile;
alter system set fal_client='OTTER_PR' scope=spfile;
alter system set log_archive_config='DG_CONFIG=(OTTER_PR, OTTER_DR)' scope=spfile;
alter system set log_archive_dest_2='SERVICE=OTTER_DR LGWR ASYNC valid_for=(online_logfile,primary_role) db_unique_name=OTTER_DR' scope=spfile;
alter system set log_archive_dest_state_2='enable' scope=spfile;
alter system set remote_login_passwordfile=exclusive scope=spfile;
alter system set log_archive_max_processes=5 scope=spfile;
alter system set standby_file_management=auto scope=spfile;
alter system set standby_file_management=auto scope=spfile;
不要设置standby_file_management参数,默认值是manual。如果设置成auto,duplicate出错:
Oracle error from auxiliary database: ORA-01275: Operation RENAME is not allowed if standby file management is automatic.
RMAN-05535: warning: All redo log files were not defined properly.
Oracle error from auxiliary database: ORA-01275: Operation RENAME is not allowed if standby file management is automatic.
所有Redo Log 文件都无法复制。
重启数据库
5.8.备库/etc/oratab
OTTER:/oracle/app/oracle/product/12.2.0.3:N
5.9.创建init.ora文件
对于 RMAN duplicate方法而言,init.ora 文件仅需要一个参数:db_name(甚至不必是数据库的真实名称 — 可使用任意名称)。RMAN 将从主数据库复制 spfile,因此仅在复制的第一阶段需要该 init.ora 文件。
db_name = OTTER
创建PFILE
cd $ORACLE_HOME/dbs
vi initOTTER.ora
DB_NAME=OTTER
DB_UNIQUE_NAME=OTTER_DR
其余的参数将通过RMAN Duplicate 命令设置。
duplicate命令可以设置spfile参数,但是必须以pfile启动,否则会出错:
RMAN-05537: DUPLICATE without TARGET connection when auxiliary instance is started with spfile cannot use SPFILE clause
5.10.备库拷贝密码文件
[oracle@dg2:/oracle/app/oracle/product/12.2.0.3/dbs]$scp oracle@dg1:/oracle/app/oracle/product/12.2.0.3/dbs/orapwOTTER .
测试是否可以正常登陆。
sqlplus sys/oracle@OTTER_DR as sysdba
5.11.创建相应的目录
/oradata/data
/oradata/fra
[oracle@dg2:/oracle]mkdir -p /oracle/app/oracle/admin/OTTER/adump
[oracle@dg2:/oracle]mkdir -p /oracle/app/oracle/audit
[oracle@dg2:/oradata]ls -l
total 0
drwxr-xr-x 2 oracle oinstall 6 May 17 21:11 arc
drwxr-xr-x 2 oracle oinstall 6 May 17 21:11 data
drwxr-xr-x 2 oracle oinstall 6 May 17 21:10 fra
5.12.备库启动到nomount
startup nomount pfile=?/dbs/initOTTER.ora
Make sure you exit sqlplus after starting the database in nomount. The duplicate procedure will restart the database and an open connection can cause the process to fail.
5.13.创建备库
rman
Recovery Manager: Release 19.0.0.0.0 - Production on Sun May 17 22:38:18 2020
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
RMAN>
RMAN> connect target sys/oracle@OTTER_PR
connected to target database: OTTER (DBID=480368616)
RMAN> connect auxiliary sys/oracle@OTTER_DR
connected to auxiliary database: OTTER (not mounted)
运行duplicate命令:
run {
allocate channel cl1 type disk;
allocate channel cl2 type disk;
allocate channel cl3 type disk;
allocate auxiliary channel c1 type disk;
allocate auxiliary channel c2 type disk;
allocate auxiliary channel c3 type disk;
duplicate target database
for standby
from active database
dorecover
spfile
set DB_UNIQUE_NAME='OTTER_DR'
set audit_file_dest='/oracle/app/oracle/admin/OTTER/adump'
set control_files='/oradata/data/OTTER_PR/control01.ctl','/oradata/data/OTTER_DR/control02.ctl'
set db_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set log_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set fal_server='OTTER_PR'
set fal_client='OTTER_DR'
set log_archive_config='dg_config=(OTTER_PR,OTTER_DR)'
set log_archive_dest_2='service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'
nofilenamecheck;
release channel c1;
release channel c2;
release channel c3;
release channel cl1;
release channel cl2;
release channel cl3;
}
using target database control file instead of recovery catalog
allocated channel: cl1
channel cl1: SID=10 device type=DISK
allocated channel: cl2
channel cl2: SID=397 device type=DISK
allocated channel: cl3
channel cl3: SID=13 device type=DISK
allocated channel: c1
channel c1: SID=433 device type=DISK
allocated channel: c2
channel c2: SID=10 device type=DISK
allocated channel: c3
channel c3: SID=150 device type=DISK
Starting Duplicate Db at 18-MAY-20
current log archived
contents of Memory Script:
{
backup as copy reuse
targetfile '/oracle/app/oracle/product/12.2.0.1/dbs/orapwOTTER' auxiliary format
'/oracle/app/oracle/product/12.2.0.1/dbs/orapwOTTER' ;
restore clone from service 'OTTER_PR' spfile to
'/oracle/app/oracle/product/12.2.0.1/dbs/spfileOTTER.ora';
sql clone "alter system set spfile= ''/oracle/app/oracle/product/12.2.0.1/dbs/spfileOTTER.ora''";
}
executing Memory Script
Starting backup at 18-MAY-20
Finished backup at 18-MAY-20
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: restoring SPFILE
output file name=/oracle/app/oracle/product/12.2.0.1/dbs/spfileOTTER.ora
channel c1: restore complete, elapsed time: 00:00:01
Finished restore at 18-MAY-20
sql statement: alter system set spfile= ''/oracle/app/oracle/product/12.2.0.1/dbs/spfileOTTER.ora''
contents of Memory Script:
{
sql clone "alter system set db_unique_name =
''OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set audit_file_dest =
''/oracle/app/oracle/admin/OTTER/adump'' comment=
'''' scope=spfile";
sql clone "alter system set control_files =
''/oradata/data/OTTER/control01.ctl'', ''/oradata/data/OTTER/control02.ctl'' comment=
'''' scope=spfile";
sql clone "alter system set db_file_name_convert =
''/oradata/data/OTTER'', ''/oradata/data/OTTER'' comment=
'''' scope=spfile";
sql clone "alter system set log_file_name_convert =
''/oradata/data/OTTER'', ''/oradata/data/OTTER'' comment=
'''' scope=spfile";
sql clone "alter system set fal_server =
''OTTER_PR'' comment=
'''' scope=spfile";
sql clone "alter system set fal_client =
''OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set log_archive_config =
''dg_config=(OTTER_PR,OTTER_DR)'' comment=
'''' scope=spfile";
sql clone "alter system set log_archive_dest_2 =
''service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'' comment=
'''' scope=spfile";
shutdown clone immediate;
startup clone nomount;
}
executing Memory Script
sql statement: alter system set db_unique_name = ''OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set audit_file_dest = ''/oracle/app/oracle/admin/OTTER/adump'' comment= '''' scope=spfile
sql statement: alter system set control_files = ''/oradata/data/OTTER/control01.ctl'', ''/oradata/data/OTTER/control02.ctl'' comment= '''' scope= spfile
sql statement: alter system set db_file_name_convert = ''/oradata/data/OTTER'', ''/oradata/data/OTTER'' comment= '''' scope=spfile
sql statement: alter system set log_file_name_convert = ''/oradata/data/OTTER'', ''/oradata/data/OTTER'' comment= '''' scope=spfile
sql statement: alter system set fal_server = ''OTTER_PR'' comment= '''' scope=spfile
sql statement: alter system set fal_client = ''OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set log_archive_config = ''dg_config=(OTTER_PR,OTTER_DR)'' comment= '''' scope=spfile
sql statement: alter system set log_archive_dest_2 = ''service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_P R'' comment= '''' scope=spfile
Oracle instance shut down
connected to auxiliary database (not started)
Oracle instance started
Total System Global Area 1660944384 bytes
Fixed Size 8621376 bytes
Variable Size 1073742528 bytes
Database Buffers 570425344 bytes
Redo Buffers 8155136 bytes
allocated channel: c1
channel c1: SID=134 device type=DISK
allocated channel: c2
channel c2: SID=263 device type=DISK
allocated channel: c3
channel c3: SID=388 device type=DISK
contents of Memory Script:
{
restore clone from service 'OTTER_PR' standby controlfile;
}
executing Memory Script
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: restoring control file
channel c1: restore complete, elapsed time: 00:00:01
output file name=/oradata/data/OTTER/control01.ctl
output file name=/oradata/data/OTTER/control02.ctl
Finished restore at 18-MAY-20
contents of Memory Script:
{
sql clone 'alter database mount standby database';
}
executing Memory Script
sql statement: alter database mount standby database
contents of Memory Script:
{
set newname for tempfile 1 to
"/oradata/data/OTTER/temp01.dbf";
switch clone tempfile all;
set newname for datafile 1 to
"/oradata/data/OTTER/system01.dbf";
set newname for datafile 3 to
"/oradata/data/OTTER/sysaux01.dbf";
set newname for datafile 4 to
"/oradata/data/OTTER/undotbs01.dbf";
set newname for datafile 7 to
"/oradata/data/OTTER/users01.dbf";
restore
from nonsparse from service
'OTTER_PR' clone database
;
sql 'alter system archive log current';
}
executing Memory Script
executing command: SET NEWNAME
renamed tempfile 1 to /oradata/data/OTTER/temp01.dbf in control file
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: specifying datafile(s) to restore from backup set
channel c1: restoring datafile 00001 to /oradata/data/OTTER/system01.dbf
channel c2: starting datafile backup set restore
channel c2: using network backup set from service OTTER_PR
channel c2: specifying datafile(s) to restore from backup set
channel c2: restoring datafile 00003 to /oradata/data/OTTER/sysaux01.dbf
channel c3: starting datafile backup set restore
channel c3: using network backup set from service OTTER_PR
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00004 to /oradata/data/OTTER/undotbs01.dbf
channel c3: restore complete, elapsed time: 00:00:03
channel c3: starting datafile backup set restore
channel c3: using network backup set from service OTTER_PR
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00007 to /oradata/data/OTTER/users01.dbf
channel c3: restore complete, elapsed time: 00:00:01
channel c1: restore complete, elapsed time: 00:00:06
channel c2: restore complete, elapsed time: 00:00:06
Finished restore at 18-MAY-20
sql statement: alter system archive log current
current log archived
contents of Memory Script:
{
restore clone force from service 'OTTER_PR'
archivelog from scn 1422661;
switch clone datafile all;
}
executing Memory Script
Starting restore at 18-MAY-20
channel c1: starting archived log restore to default destination
channel c1: using network backup set from service OTTER_PR
channel c1: restoring archived log
archived log thread=1 sequence=6
channel c2: starting archived log restore to default destination
channel c2: using network backup set from service OTTER_PR
channel c2: restoring archived log
archived log thread=1 sequence=7
channel c3: starting archived log restore to default destination
channel c3: using network backup set from service OTTER_PR
channel c3: restoring archived log
archived log thread=1 sequence=8
channel c1: restore complete, elapsed time: 00:00:00
channel c2: restore complete, elapsed time: 00:00:00
channel c3: restore complete, elapsed time: 00:00:00
Finished restore at 18-MAY-20
datafile 1 switched to datafile copy
input datafile copy RECID=1 STAMP=1040744094 file name=/oradata/data/OTTER/system01.dbf
datafile 3 switched to datafile copy
input datafile copy RECID=2 STAMP=1040744094 file name=/oradata/data/OTTER/sysaux01.dbf
datafile 4 switched to datafile copy
input datafile copy RECID=3 STAMP=1040744094 file name=/oradata/data/OTTER/undotbs01.dbf
datafile 7 switched to datafile copy
input datafile copy RECID=4 STAMP=1040744094 file name=/oradata/data/OTTER/users01.dbf
contents of Memory Script:
{
set until scn 1422838;
recover
standby
clone database
delete archivelog
;
}
executing Memory Script
executing command: SET until clause
Starting recover at 18-MAY-20
starting media recovery
archived log for thread 1 with sequence 6 is already on disk as file /oradata/arc/arc_1_6_1040743203.dbf
archived log for thread 1 with sequence 7 is already on disk as file /oradata/arc/arc_1_7_1040743203.dbf
archived log for thread 1 with sequence 8 is already on disk as file /oradata/arc/arc_1_8_1040743203.dbf
archived log file name=/oradata/arc/arc_1_6_1040743203.dbf thread=1 sequence=6
archived log file name=/oradata/arc/arc_1_7_1040743203.dbf thread=1 sequence=7
archived log file name=/oradata/arc/arc_1_8_1040743203.dbf thread=1 sequence=8
media recovery complete, elapsed time: 00:00:01
Finished recover at 18-MAY-20
Finished Duplicate Db at 18-MAY-20
released channel: c1
released channel: c2
released channel: c3
released channel: cl1
released channel: cl2
released channel: cl3
RMAN>
6.RMAN duplicate方式(开启闪回)推荐
6.1.创建数据库
dbca -silent -createDatabase \
-templateName General_Purpose.dbc \
-gdbName OTTER -sid OTTER \
-initParams db_unique_name=OTTER_PR,db_name=OTTER \
-sysPassword oracle \
-systemPassword oracle \
-emConfiguration NONE \
-datafileDestination "/oradata/data" \
-storageType FS \
-redoLogFileSize 50 \
-characterSet AL32UTF8 \
-ignorePreReqs
6.2.开启闪回模式
开启归档
在开启闪回功能之前,必须先开启数据库归档。
启动到mount状态。
默认归档存储路径是USE_DB_RECOVERY_FILE_DEST。
开启闪回的时候设置。
SQL> alter database archivelog;
Database altered.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /oracle/app/oracle/product/12.2.0.3/dbs/arc
Oldest online log sequence 18
Next log sequence to archive 20
Current log sequence 20
不要设置log_archive_dest_1参数,开启闪回的时候,设置db_recovery_file_dest。
开启闪回
alter system set db_recovery_file_dest_size=2g;
alter system set db_recovery_file_dest='/oradata/fra';
alter database flashback on;
alter system set db_flashback_retention_target=1440 scope=spfile;
SQL> show parameter db_recovery
NAME TYPE VALUE
------------------------------------ ----------- ------------
db_recovery_file_dest string /oradata/fra
db_recovery_file_dest_size big integer 2G
SQL> select flashback_on from v$database;
FLASHBACK_ON
------------------
YES
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 18
Next log sequence to archive 20
Current log sequence 20
6.3.设置force_loging
alter database force logging;
select force_logging from v$database;
6.4.配置Listener,tnsnames
主库,备库配置是一样的。参考4.4
备库从主库拷贝(scp命令)listener.ora, tnsnames.ora, sqlnet.ora 三个文件, 只需要修改listener.ora中的IP地址。其余两个文件完全一样。
主库和备库测试:
tnsping OTTER_DR
tnsping OTTER_PR
6.5.主库增加Standby Redo Logfile
SRL: Standby Redo Log
ORL: Online Redo Log
- SRL只有在备库中才起作用。备库中SRL相当于主库中的ORL,在主库发生日志切换时,Remote File System(RFS)进程把主库中的ORL写到备库中的SRL,同时备库归档上一个SRL。
- 每个SRL 至少要和主库的ORL 一样大,为了方便管理,Oracle 建议主备库的ORL 设置成一样的大小。
- SRL 至少要比主库的ORL多一组。 可以在主库查询v$log视图,来确定主库有多少组ORL。
公式:nx+1 (n为日志组数,x为节点数) - Oracle 建议在主库也创建SRL,在进行switchover 之后, 主库变为备库,不需要再创建SRL。
SQL> select group#, thread#, bytes/1024/1024 from vlog;
GROUP# THREAD# BYTES/1024/1024
---------- ---------- ---------------
1 1 50
2 1 50
3 1 50
alter database add standby logfile group 4 '/oradata/data/OTTER_PR/standby_redo04.dbf' size 50M;
alter database add standby logfile group 5 '/oradata/data/OTTER_PR/standby_redo05.dbf' size 50M;
alter database add standby logfile group 6 '/oradata/data/OTTER_PR/standby_redo06.dbf' size 50M;
alter database add standby logfile group 7 '/oradata/data/OTTER_PR/standby_redo07.dbf' size 50M;
set linesize 500
col MEMBER for a50
SQL> select group#, status, type, member, IS_RECOVERY_DEST_FILE from vlogfile order by 1;
GROUP# STATU TYPE MEMBER IS_RE
---------- ----- ------- --------------------------------------------- -----
1 ONLINE /oradata/data/OTTER_PR/redo01.dbf NO
2 ONLINE /oradata/data/OTTER_PR/redo02.dbf NO
3 ONLINE /oradata/data/OTTER_PR/redo03.dbf NO
4 STANDBY /oradata/data/OTTER_PR/standby_redo04.dbf NO
5 STANDBY /oradata/data/OTTER_PR/standby_redo05.dbf NO
6 STANDBY /oradata/data/OTTER_PR/standby_redo06.dbf NO
7 STANDBY /oradata/data/OTTER_PR/standby_redo07.dbf NO
SQL> select group#, bytes/1024/1024 MB from v$log;
GROUP# MB
---------- ----------
1 50
2 50
3 50
SQL> SELECT GROUP#, BYTES/1024/1024 MB FROM V¥STANDBY_LOG;
GROUP# MB
---------- ----------
4 50
5 50
6 50
7 50
6.6.主库参数设置
alter system set db_file_name_convert=' /oradata/data/OTTER_DR',' /oradata/data/OTTER_PR' scope=spfile;
alter system set log_file_name_convert=' /oradata/data/OTTER_DR',' /oradata/data/OTTER_PR' scope=spfile;
alter system set fal_server='OTTER_DR' scope=spfile;
alter system set fal_client='OTTER_PR' scope=spfile;
alter system set log_archive_config='DG_CONFIG=(OTTER_PR, OTTER_DR)' scope=spfile;
alter system set log_archive_dest_2='SERVICE=OTTER_DR LGWR ASYNC valid_for=(online_logfile,primary_role) db_unique_name=OTTER_DR' scope=spfile;
alter system set log_archive_dest_state_2='enable' scope=spfile;
alter system set remote_login_passwordfile=exclusive scope=spfile;
alter system set log_archive_max_processes=5 scope=spfile;
alter system set standby_file_management=auto scope=spfile;
不要设置standby_file_management参数,默认值是manual。如果设置成auto,duplicate出错:
Oracle error from auxiliary database: ORA-01275: Operation RENAME is not allowed if standby file management is automatic.
RMAN-05535: warning: All redo log files were not defined properly.
Oracle error from auxiliary database: ORA-01275: Operation RENAME is not allowed if standby file management is automatic.
所有Redo Log 文件都无法复制。
可以在duplicate 完成后设置此参数。
重启数据库
6.7.备库/etc/oratab
OTTER:/oracle/app/oracle/product/12.2.0.3:N
6.8.创建init.ora文件
对于 RMAN duplicate方法而言,init.ora 文件仅需要一个参数:db_name(甚至不必是数据库的真实名称 — 可使用任意名称)。RMAN 将从主数据库复制 spfile,因此仅在复制的第一阶段需要该 init.ora 文件。
db_name = OTTER
创建PFILE
cd $ORACLE_HOME/dbs
vi initOTTER.ora
DB_NAME=OTTER
DB_UNIQUE_NAME=OTTER_DR
其余的参数将通过RMAN Duplicate 命令设置。
duplicate命令可以设置spfile参数,但是必须以pfile启动,否则会出错:
RMAN-05537: DUPLICATE without TARGET connection when auxiliary instance is started with spfile cannot use SPFILE clause
6.9.备库拷贝密码文件
[oracle@dg2:/oracle/app/oracle/product/12.2.0.3/dbs]$scp oracle@dg1:/oracle/app/oracle/product/12.2.0.3/dbs/orapwOTTER .
测试是否可以正常登陆。
sqlplus sys/oracle@OTTER_DR as sysdba
6.10.创建相应的目录
/oradata/data
/oradata/fra
[oracle@dg2:/oracle]mkdir -p /oracle/app/oracle/admin/OTTER_DR/adump
[oracle@dg2:/oracle]mkdir -p /oracle/app/oracle/audit
[oracle@dg2:/oradata]ls -l
total 0
drwxr-xr-x 2 oracle oinstall 6 May 17 21:11 arc
drwxr-xr-x 2 oracle oinstall 6 May 17 21:11 data
drwxr-xr-x 2 oracle oinstall 6 May 17 21:10 fra
6.11.备库启动到nomount
startup nomount pfile=?/dbs/initOTTER.ora
Make sure you exit sqlplus after starting the database in nomount. The duplicate procedure will restart the database and an open connection can cause the process to fail.
6.12.创建备库
rman
Recovery Manager: Release 19.0.0.0.0 - Production on Sun May 17 22:38:18 2020
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
RMAN>
RMAN> connect target sys/oracle@OTTER_PR
connected to target database: OTTER (DBID=480368616)
RMAN> connect auxiliary sys/oracle@OTTER_DR
connected to auxiliary database: OTTER (not mounted)
运行duplicate命令:
run {
allocate channel cl1 type disk;
allocate channel cl2 type disk;
allocate channel cl3 type disk;
allocate auxiliary channel c1 type disk;
allocate auxiliary channel c2 type disk;
allocate auxiliary channel c3 type disk;
duplicate target database
for standby
from active database
dorecover
spfile
set DB_UNIQUE_NAME='OTTER_DR'
set audit_file_dest='/oracle/app/oracle/admin/OTTER_DR/adump'
set control_files='/oradata/data/OTTER_DR/control01.ctl','/oradata/data/OTTER_DR/control02.ctl'
set db_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set log_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set fal_server='OTTER_PR'
set fal_client='OTTER_DR'
set log_archive_config='dg_config=(OTTER_PR,OTTER_DR)'
set log_archive_dest_2='service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'
nofilenamecheck;
release channel c1;
release channel c2;
release channel c3;
release channel cl1;
release channel cl2;
release channel cl3;
}
坑:
应该设置:
set db_file_name_convert OTTER_PR -> OTTER_DR
set log_file_name_convert OTTER_PR -> OTTER_DR
duplicate 命令运行时,会把主库数据文件从OTTER_PR目录拷贝到OTTER_DR目录。
如果设置成,OTTER_DR -> OTTER_PR, 会出现以下错误:
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
RMAN-05535: warning: All redo log files were not defined properly.
spfile: 设置备库的参数文件, values for parameters specific to the auxiliary instance can be set here.
for standby: the duplicate is for use as a standby so a DBID change will not be forced.
from active database: instructs RMAN to use the active target database instead of disk based backups.
dorecover: do recovery bringing the standby database up to the current point in time.
nofilenamecheck: this option is added because the duplicate database files uses the same name as the source database. When NOFILENAMECHECK is used with the DUPLICATE command, RMAN does not validate the filenames during restoration. If the primary database and the standby database are on the same host, The DUPLICATE NOFILENAMECHECK option should not be used.
target atabase: 主库 connect target sys/oracle@OTTER_PR
auxiliary: 备库 connect auxiliary sys/oracle@OTTER_DR
db_unique_name: 必须指定,否则出错:RMAN-05558: Must specify DB_UNIQUE_NAME with FOR STANDBY clause
audit_file_dest: 必须指定,否则出错:RMAN-04014: startup failed: ORA-09925: Unable to create audit trail file
如果备库PFILE是拷贝主库修改生成的,就不需要在spfile参数中设置参数,可以直接运行duplicate命令。例如:
RMAN>duplicate target database for standby from active database nofilenamecheck;
RMAN> run {
allocate channel cl1 type disk;
allocate channel cl2 type disk;
allocate channel cl3 type disk;
allocate auxiliary channel c1 type disk;
allocate auxiliary channel c2 type disk;
allocate auxiliary channel c3 type disk;
duplicate target database
for standby
from active database
dorecover
spfile
set DB_UNIQUE_NAME='OTTER_DR'
set audit_file_dest='/oracle/app/oracle/admin/OTTER_DR/adump'
set control_files='/oradata/data/OTTER_DR/control01.ctl','/oradata/data/OTTER_DR/control02.ctl'
set db_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set log_file_name_convert='/oradata/data/OTTER_PR','/oradata/data/OTTER_DR'
set fal_server='OTTER_PR'
set fal_client='OTTER_DR'
set log_archive_config='dg_config=(OTTER_PR,OTTER_DR)'
set log_archive_dest_2='service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'
nofilenamecheck;
release channel c1;
release channel c2;
release channel c3;
release channel cl1;
release channel cl2;
release channel cl3;
29> }
using target database control file instead of recovery catalog
allocated channel: cl1
channel cl1: SID=148 device type=DISK
allocated channel: cl2
channel cl2: SID=401 device type=DISK
allocated channel: cl3
channel cl3: SID=27 device type=DISK
allocated channel: c1
channel c1: SID=10 device type=DISK
allocated channel: c2
channel c2: SID=150 device type=DISK
allocated channel: c3
channel c3: SID=294 device type=DISK
Starting Duplicate Db at 18-MAY-20
current log archived
contents of Memory Script:
{
backup as copy reuse
passwordfile auxiliary format '/oracle/app/oracle/product/12.2.0.3/dbs/orapwOTTER' ;
restore clone from service 'OTTER_PR' spfile to
'/oracle/app/oracle/product/12.2.0.3/dbs/spfileOTTER.ora';
sql clone "alter system set spfile= ''/oracle/app/oracle/product/12.2.0.3/dbs/spfileOTTER.ora''";
}
executing Memory Script
Starting backup at 18-MAY-20
Finished backup at 18-MAY-20
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: restoring SPFILE
output file name=/oracle/app/oracle/product/12.2.0.3/dbs/spfileOTTER.ora
channel c1: restore complete, elapsed time: 00:00:01
Finished restore at 18-MAY-20
sql statement: alter system set spfile= ''/oracle/app/oracle/product/12.2.0.3/dbs/spfileOTTER.ora''
contents of Memory Script:
{
sql clone "alter system set db_unique_name =
''OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set audit_file_dest =
''/oracle/app/oracle/admin/OTTER_DR/adump'' comment=
'''' scope=spfile";
sql clone "alter system set control_files =
''/oradata/data/OTTER_DR/control01.ctl'', ''/oradata/data/OTTER_DR/control02.ctl'' comment=
'''' scope=spfile";
sql clone "alter system set db_file_name_convert =
''/oradata/data/OTTER_PR'', ''/oradata/data/OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set log_file_name_convert =
''/oradata/data/OTTER_PR'', ''/oradata/data/OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set fal_server =
''OTTER_PR'' comment=
'''' scope=spfile";
sql clone "alter system set fal_client =
''OTTER_DR'' comment=
'''' scope=spfile";
sql clone "alter system set log_archive_config =
''dg_config=(OTTER_PR,OTTER_DR)'' comment=
'''' scope=spfile";
sql clone "alter system set log_archive_dest_2 =
''service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'' comment=
'''' scope=spfile";
shutdown clone immediate;
startup clone nomount;
}
executing Memory Script
sql statement: alter system set db_unique_name = ''OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set audit_file_dest = ''/oracle/app/oracle/admin/OTTER_DR/adump'' comment= '''' scope=spfile
sql statement: alter system set control_files = ''/oradata/data/OTTER_DR/control01.ctl'', ''/oradata/data/OTTER_DR/control02.ctl'' comment= '''' scope=spfile
sql statement: alter system set db_file_name_convert = ''/oradata/data/OTTER_PR'', ''/oradata/data/OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set log_file_name_convert = ''/oradata/data/OTTER_PR'', ''/oradata/data/OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set fal_server = ''OTTER_PR'' comment= '''' scope=spfile
sql statement: alter system set fal_client = ''OTTER_DR'' comment= '''' scope=spfile
sql statement: alter system set log_archive_config = ''dg_config=(OTTER_PR,OTTER_DR)'' comment= '''' scope=spfile
sql statement: alter system set log_archive_dest_2 = ''service=OTTER_PR LGWR async valid_for=(ONLINE_LOGFILE,PRIMARY_ROLE) db_unique_name=OTTER_PR'' comment= '''' scope=spfile
Oracle instance shut down
connected to auxiliary database (not started)
Oracle instance started
Total System Global Area 1660940992 bytes
Fixed Size 8897216 bytes
Variable Size 956301312 bytes
Database Buffers 687865856 bytes
Redo Buffers 7876608 bytes
allocated channel: c1
channel c1: SID=134 device type=DISK
allocated channel: c2
channel c2: SID=262 device type=DISK
allocated channel: c3
channel c3: SID=389 device type=DISK
contents of Memory Script:
{
restore clone from service 'OTTER_PR' standby controlfile;
}
executing Memory Script
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: restoring control file
channel c1: restore complete, elapsed time: 00:00:01
output file name=/oradata/data/OTTER_DR/control01.ctl
output file name=/oradata/data/OTTER_DR/control02.ctl
Finished restore at 18-MAY-20
contents of Memory Script:
{
sql clone 'alter database mount standby database';
}
executing Memory Script
sql statement: alter database mount standby database
contents of Memory Script:
{
set newname for tempfile 1 to
"/oradata/data/OTTER_DR/temp01.dbf";
switch clone tempfile all;
set newname for datafile 1 to
"/oradata/data/OTTER_DR/system01.dbf";
set newname for datafile 3 to
"/oradata/data/OTTER_DR/sysaux01.dbf";
set newname for datafile 4 to
"/oradata/data/OTTER_DR/undotbs01.dbf";
set newname for datafile 7 to
"/oradata/data/OTTER_DR/users01.dbf";
restore
from nonsparse from service
'OTTER_PR' clone database
;
sql 'alter system archive log current';
}
executing Memory Script
executing command: SET NEWNAME
renamed tempfile 1 to /oradata/data/OTTER_DR/temp01.dbf in control file
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
Starting restore at 18-MAY-20
channel c1: starting datafile backup set restore
channel c1: using network backup set from service OTTER_PR
channel c1: specifying datafile(s) to restore from backup set
channel c1: restoring datafile 00001 to /oradata/data/OTTER_DR/system01.dbf
channel c2: starting datafile backup set restore
channel c2: using network backup set from service OTTER_PR
channel c2: specifying datafile(s) to restore from backup set
channel c2: restoring datafile 00003 to /oradata/data/OTTER_DR/sysaux01.dbf
channel c3: starting datafile backup set restore
channel c3: using network backup set from service OTTER_PR
channel c3: specifying datafile(s) to restore from backup set
channel c3: restoring datafile 00004 to /oradata/data/OTTER_DR/undotbs01.dbf
channel c2: restore complete, elapsed time: 00:00:07
channel c2: starting datafile backup set restore
channel c2: using network backup set from service OTTER_PR
channel c2: specifying datafile(s) to restore from backup set
channel c2: restoring datafile 00007 to /oradata/data/OTTER_DR/users01.dbf
channel c1: restore complete, elapsed time: 00:00:08
channel c2: restore complete, elapsed time: 00:00:01
channel c3: restore complete, elapsed time: 00:00:08
Finished restore at 18-MAY-20
sql statement: alter system archive log current
current log archived
contents of Memory Script:
{
restore clone force from service 'OTTER_PR'
archivelog from scn 2051277;
switch clone datafile all;
}
executing Memory Script
Starting restore at 18-MAY-20
channel c1: starting archived log restore to default destination
channel c1: using network backup set from service OTTER_PR
channel c1: restoring archived log
archived log thread=1 sequence=25
channel c2: starting archived log restore to default destination
channel c2: using network backup set from service OTTER_PR
channel c2: restoring archived log
archived log thread=1 sequence=26
channel c1: restore complete, elapsed time: 00:00:00
channel c2: restore complete, elapsed time: 00:00:01
Finished restore at 18-MAY-20
datafile 1 switched to datafile copy
input datafile copy RECID=1 STAMP=1040758675 file name=/oradata/data/OTTER_DR/system01.dbf
datafile 3 switched to datafile copy
input datafile copy RECID=2 STAMP=1040758675 file name=/oradata/data/OTTER_DR/sysaux01.dbf
datafile 4 switched to datafile copy
input datafile copy RECID=3 STAMP=1040758675 file name=/oradata/data/OTTER_DR/undotbs01.dbf
datafile 7 switched to datafile copy
input datafile copy RECID=4 STAMP=1040758675 file name=/oradata/data/OTTER_DR/users01.dbf
contents of Memory Script:
{
set until scn 2051507;
recover
standby
clone database
delete archivelog
;
}
executing Memory Script
executing command: SET until clause
Starting recover at 18-MAY-20
starting media recovery
archived log for thread 1 with sequence 25 is already on disk as file /oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_25_hd672l78_.arc
archived log for thread 1 with sequence 26 is already on disk as file /oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_26_hd672l99_.arc
archived log file name=/oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_25_hd672l78_.arc thread=1 sequence=25
archived log file name=/oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_26_hd672l99_.arc thread=1 sequence=26
media recovery complete, elapsed time: 00:00:00
Finished recover at 18-MAY-20
contents of Memory Script:
{
delete clone force archivelog all;
}
executing Memory Script
deleted archived log
archived log file name=/oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_25_hd672l78_.arc RECID=1 STAMP=1040758674
Deleted 1 objects
deleted archived log
archived log file name=/oradata/fra/OTTER_DR/archivelog/2020_05_18/o1_mf_1_26_hd672l99_.arc RECID=2 STAMP=1040758674
Deleted 1 objects
Finished Duplicate Db at 18-MAY-20
released channel: c1
released channel: c2
released channel: c3
released channel: cl1
released channel: cl2
released channel: cl3
RMAN>
6.13.查看备库状态
SQL> select open_mode, database_role, switchover_status from v$database;
OPEN_MODE DATABASE_ROLE SWITCHOVER_STATUS
-------------------- ---------------- --------------------
MOUNTED PHYSICAL STANDBY NOT ALLOWED
SQL> select protection_mode from v¥database;
PROTECTION_MODE
--------------------
MAXIMUM PERFORMANCE
7.测试
7.1.启动和停止Real Time Apply
SQL> alter database open read only;
Database altered.
SQL> alter database recover managed standby database using current logfile disconnect from session;
Database altered.
alter database recover managed standby database cancel;
7.2.检查主备库是否sync
主库:
SQL> select max(sequence#) from v$archived_log;
MAX(SEQUENCE#)
--------------
23
备库:
SQL> select max(sequence#) from v¥archived_log;
MAX(SEQUENCE#)
--------------
23
select sequence#,standby_dest,archived,applied,status from v¥archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
22 NO YES YES D
23 NO YES YES D
select unique thread# as thread, max(sequence#) over (partition by thread#) as last from v¥archived_log;
SELECT NAME, CREATOR, SEQUENCE#, APPLIED, COMPLETION_TIME FROM V$ARCHIVED_LOG;
NAME CREATOR SEQUENCE# APPLIED COMPLETION_TIME
---------------------------------------------------------------------- ------- ---------- --------- ------------------
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_20_hd8cb0mz_.arc ARCH 20 YES 19-MAY-20
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_21_hd8col7q_.arc FGRD 21 YES 19-MAY-20
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_22_hd8cqbbw_.arc FGRD 22 YES 19-MAY-20
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_23_hd8cqbff_.arc FGRD 23 YES 19-MAY-20
OTTER_DR FGRD 24 NO 19-MAY-20
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_24_hd8hf9ov_.arc FGRD 24 YES 19-MAY-20
/oradata/fra/OTTER_PR/archivelog/2020_05_19/o1_mf_1_25_hd8hrbfj_.arc ARCH 25 YES 19-MAY-20
7.3.检查主备库是否有GAP
select thread#, low_sequence#, high_sequence# from v$archive_gap;
SQL> select status, gap_status from v¥archive_dest_status where dest_id=2;
STATUS GAP_STATUS
--------- ------------------------
VALID NO GAP
7.4.检查备库进程状态
SQL> select process,status from v$managed_standby;
PROCESS STATUS
--------- ------------
ARCH CONNECTED
DGRD ALLOCATED
DGRD ALLOCATED
ARCH CONNECTED
ARCH CONNECTED
ARCH CONNECTED
ARCH CONNECTED
MRP0 APPLYING_LOG
RFS IDLE
RFS IDLE
select process,client_process,status,sequence# from v¥managed_standby;
SQL> select role,thread#,sequence#,action from v¥dataguard_process;
ROLE THREAD# SEQUENCE# ACTION
------------------------ ---------- ---------- ------------
log writer 0 0 IDLE
redo transport monitor 0 0 IDLE
gap manager 0 0 IDLE
redo transport timer 0 0 IDLE
archive local 0 0 IDLE
archive redo 0 0 IDLE
archive redo 0 0 IDLE
archive redo 0 0 IDLE
archive redo 0 0 IDLE
RFS archive 0 0 IDLE
RFS async 1 27 IDLE
RFS ping 1 27 IDLE
managed recovery 0 0 IDLE
recovery logmerger 1 27 APPLYING_LOG
recovery apply slave 0 0 IDLE
recovery apply slave 0 0 IDLE
recovery apply slave 0 0 IDLE
recovery apply slave 0 0 IDLE
18 rows selected.
7.5.主备切换switchover
1)查看主库,备库的状态
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PRIMARY READ WRITE MAXIMUM PERFORMANCE TO STANDBY
SQL> select database_role,open_mode,protection_mode,switchover_status from v¥database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PHYSICAL STANDBY READ ONLY WITH APPLY MAXIMUM PERFORMANCE NOT ALLOWED
2)检查主库上的会话,是否仍有用户使用数据库,若仍有人使用,是不允许切换的,切换前要通知确保无用户使用。
SQL> select username, sid from v$session where username is not null and username <> 'SYS';
no rows selected
3)确认恢复进程正在运行, Verify Managed Recovery is running on the standby
SQL> select process,client_process,status,sequence# from v$managed_standby;
PROCESS CLIENT_P STATUS SEQUENCE#
--------- -------- ------------ ----------
ARCH ARCH CONNECTED 0
DGRD N/A ALLOCATED 0
DGRD N/A ALLOCATED 0
ARCH ARCH CONNECTED 0
ARCH ARCH CONNECTED 0
ARCH ARCH CONNECTED 0
ARCH ARCH CONNECTED 0
MRP0 N/A APPLYING_LOG 24
RFS Archival IDLE 0
RFS LGWR IDLE 24
If managed standby recovery is not running or not started with real-time apply, restart managed recovery with real-time apply enabled:
alter database recover managed standby database cancel;
alter database recover managed standby database using current logfile disconnect from session;
4)检查日志的状态确保没有GAP,Verify there are no large Gaps
SQL> select sequence#, standby_dest, archived,applied, status from v$archived_log;
SEQUENCE# STA ARC APPLIED S
---------- --- --- --------- -
22 NO YES YES D
23 NO YES YES D
Verify the target physical standby database has applied up to, but not including the logs from the primary query. On the standby the following query should be within 1 or 2 of the primary query result.
SELECT THREAD#, MAX(SEQUENCE#) FROM V¥ARCHIVED_LOG WHERE APPLIED = 'YES' AND RESETLOGS_CHANGE# = (SELECT RESETLOGS_CHANGE# FROM V¥DATABASE_INCARNATION WHERE STATUS = 'CURRENT') GROUP BY THREAD#;
5)检查主库的角色, Verify that the primary database can be switched to the standby role
SQL> select database_role,open_mode,protection_mode,switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PRIMARY READ WRITE MAXIMUM PERFORMANCE TO STANDBY
Switch over always originates from Primary database. On the request of switchover sql statement “alter database commit to switchover to physical standby with session shutdown”, Primary will generate special marker called EOR (end-of-redo) that is placed in the header of online redo log sequence. So this online redo log sequence will be archived locally and sent to all standby databases.
Only upon receiving and applying EOR (end-of-redo), v¥database.switchover_status will change from “not allowed” to “to primary” or “sessions active”.
6)主库变为物理备库
SQL> alter database commit to switchover to physical standby;
Database altered.
7)启动新的物理备库到mount状态
startup mount
8)验证standby是否能被切换成primary角色,在standby执行
SQL> SELECT SWITCHOVER_STATUS FROM V$DATABASE;
SWITCHOVER_STATUS
--------------------
TO PRIMARY
当结果是TO_PRIMARY 或SESSIONS ACTIVE时,主库才可以切换成standby角色。
9)在备库执行切换为primay操作
SQL> alter database commit to switchover to primary;
Database altered.
TO_PRIMARY,可以省略WITH SESSION SHUTDOWN子句。
SQL> select open_mode from v$database;
OPEN_MODE
--------------------
MOUNTED
10)打开新的主库
SQL> alter database open;
Database altered.
SQL> select database_role, open_mode, protection_mode, switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PRIMARY READ WRITE MAXIMUM PERFORMANCE TO STANDBY
11)在新的备库开启redo日志应用
SQL> alter database recover managed standby database using current logfile disconnect from session;
Database altered.
SQL> select database_role, open_mode, protection_mode, switchover_status from v$database;
DATABASE_ROLE OPEN_MODE PROTECTION_MODE SWITCHOVER_STATUS
---------------- -------------------- -------------------- --------------------
PHYSICAL STANDBY READ ONLY WITH APPLY MAXIMUM PERFORMANCE NOT ALLOWED
7.6.故障转移failover
Changes a standby database to the primary role in response to a primary database failure. If the primary database was not operating in either maximum protection mode or maximum availability mode before the failure, some data loss may occur. If Flashback Database is enabled on the primary database, it can be reinstated as a standby for the new primary database once the reason for the failure is corrected.
1)配置TNS
配置failover,测试连接
测试sqlplus是否能连接主库
2)查看主库归档信息
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 25
Next log sequence to archive 27
Current log sequence 27
3)关闭主库,模拟为主库损坏
关闭之前先做全备份。
shutdown immediate;
测试sqlplus是否能连接备库
4)备库确认是否有日志没有同步
SQL> select thread#, low_sequence#, high_sequence# from v$archive_gap;
no rows selected
5)如果有日志没有同步,需要把日志从主库拷贝到备库,并注册到数据库中
alter database register physical logfile 'log_file_name_xxxxx.dbf';
6)查询日志是否应用到最新状态
SQL> select distinct thread#, max(sequence#) over(partition by thread#) last from v$archived_log;
THREAD# LAST
---------- ----------
1 27
7)备库停止Apply
SQL> alter database recover managed standby database cancel;
Database altered.
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PHYSICAL STANDBY NOT ALLOWED
8)备库finish applying
SQL> alter database recover managed standby database finish;
Database altered.
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PHYSICAL STANDBY TO PRIMARY
9)备库switchover
SQL> alter database commit to switchover to primary with session shutdown;
Database altered.
SQL> alter database open;
Database altered.
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PRIMARY FAILED DESTINATION
10)Failover完成
在failover之后,如果原主库故障解决,故障数据库启动之后,它的角色仍然是Primary,DataGuard环境崩溃了。这时,有3种方法将故障数据库转换为新的备库。
- 根据新主库,配置故障数据库为备库。
- Flashback,然后转为备库。
- RMAN恢复,然后转为备库。
11)查询原备库转换成主库时的SCN
SQL> select to_char(standby_became_primary_scn) from v$database;
TO_CHAR(STANDBY_BECAME_PRIMARY_SCN)
----------------------------------------
2233900
12)Flash back故障数据库
SQL> shutdown immediate;
SQL> startup mount
SQL> flashback database to scn 2233900;
13)将故障数据库转为备库
alter database convert to physical standby;
shutdown immediate
startup
新主库:
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PRIMARY TO STANDBY
新备库:
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PHYSICAL STANDBY RECOVERY NEEDED
14)开启Real time apply
alter database recover managed standby database using current logfile disconnect from session;
SQL> select database_role, switchover_status from v$database;
DATABASE_ROLE SWITCHOVER_STATUS
---------------- --------------------
PHYSICAL STANDBY NOT ALLOWED
以上测试flashback方式,RMAN方式步骤相同,仅仅是步骤11不同:
RMAN >
run {
set until scn <standby_became_primary_scn+1>;
restore database;
recover database;
}
7.7.Flush Redo
在Oracle 11g里,Data Guard 切换多了一个新的功能:flush redo。
Flush 能把没有发送的redo 从主库传送到standby库。 只要主库能启动到mount 状态,那么Flush 就可以把没有发送的归档和current online redo 发送到备库。
Flush语法:
ALTER SYSTEM FLUSH REDO TO target_db_name;
For target_db_name, specify the DB_UNIQUE_NAME of the standby database that is to receive the redo flushed from the primary database.
Flush 会将未发送的redo 从主库传到备库,并且等待redo 在standby 库上apply 之后返回成功。 所以只要Flush成功,那么Failover 就没有数据丢失。
如果Primary 已经不能启动到mount 状态,那么就只能手动复制相应归档及REDO文件,然后注册,备库需要在应用状态。
alter database register logfile '/u01/archivelog/arc_1_160_821829622.arc';
7.8.Lag
Transport Lag:
col name for a15
col SOURCE_DB_UNIQUE_NAME for a10
col VALUE for a15
col TIME_COMPUTED for a20
col DATUM_TIME for a20
col CON_ID for 99
SQL> select * from v$dataguard_stats where name='transport lag';
SOURCE_DBID SOURCE_DB_ NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- ---------- --------------- --------------- ------------------------------ -------------------- -------------------- ------
480536289 OTTER_DR transport lag +00 00:00:00 day(2) to second(0) interval 05/19/2020 20:45:18 05/19/2020 20:45:17 0
Apply lag:
SQL> select * from v$dataguard_stats where name='apply lag';
SOURCE_DBID SOURCE_DB_ NAME VALUE UNIT TIME_COMPUTED DATUM_TIME CON_ID
----------- ---------- --------------- --------------- ------------------------------ -------------------- -------------------- ------
480536289 OTTER_DR apply lag +00 00:00:00 day(2) to second(0) interval 05/19/2020 20:45:01 05/19/2020 20:45:00 0
查询SCN实时比较primary和standby的LAG:
SQL> create database link standby connect to system identified by 'oracle' using 'standby';
SQL> select scn_to_timestamp((select current_scn from v¥database))-scn_to_timestamp((select current_scn from v$database@standby)) LAG from dual;
STANDBY_MAX_DATA_DELAT参数:
STANDBY_MAX_DATA_DELAT={INTERGE|NONE},默认NONE,单位:秒,用来指定可容忍的LAG限定,参数为会话级,对SYS用户无效。
如果standby查询超出指定的时间,抛出ORA-3172 STANDBY_MAX_DATA_DELAY has been exceeded.
强制redo apply同步:
SQL> alter session sync with primary;
执行此命令后,将会阻塞应用直到standby与primary同步。
监控LAG:
V¥DATAGUARD_STATS
V$STANDBY_EVENT_HISTOGRAM
监控redo apply性能:
V$RECOVERY_PROGRESS
7.9.OEM
7.10.Snapshot Standby
Snapshot Standby是一种特殊的Standby类型。它以某一个时点的Physical Standby作为基础,通过convert操作变成snapshot备库。该备库可以进行修改操作(增加、修改和删除)操作。当执行结束之后,可以重新回到Physical Standby角色。“失联”期间发生的所有update操作,都全部被取消掉。“失联”期间主库发生的修改动作,也会在应用apply日志的时候追赶上。在实际环境,特别是应用开发、测试环境中,我们偶尔会需要一个临时性的测试环境。这个环境上进行一些临时性、可抛弃的测试。这个时候,就可以使用这个snapshot standby。
Snapshot Standby,此功能可将备库置身于”可读写状态”用于不方便在生产环境主库中测试的内容,比如模拟上线测试等任务。当备库读写状态下任务完成后,可以非常轻松的完成Snapshot Standby数据库角色切换回备库角色,恢复与主库数据同步。在Snapshot Standby数据库状态下,备库是可以接受主库传过来的日志,但是不能够将变化应用在备库中。
物理备库要转换成Snapshot的前提条件:
- 停止备库上的日志应用,并切换到mount状态。
- 备库开启数据库闪回功能。
1)停止备库上的日志应用
备库已经是mount状态
alter database recover managed standby database cancel;
2)开启备库数据库闪回功能
alter database flashback on;
SQL> select flashback_on from v$database;
FLASHBACK_ON
------------------
YES
3)将备库转为snapshot
alter database convert to snapshot standby;
SQL> select open_mode, database_role, protection_mode from v$database;
OPEN_MODE DATABASE_ROLE PROTECTION_MODE
-------------------- ---------------- --------------------
READ WRITE SNAPSHOT STANDBY MAXIMUM PERFORMANCE
Physical Standby切换到Snapshot Standby的过程:
- 创建一个Flashback的恢复点
- 传输剩余的Standby Redo Log日志信息
- 清理Standby端的online redo log日志组
- 使用reset log方法,创建出新的朝代数据
4)在主库中修改数据
SQL> select * from test;
ID NAME
---------- ----------
10 Tom
SQL> insert into test values('20','Mike');
1 row created.
SQL> commit;
Commit complete.
5)在备库中修改数据
SQL> alter database open;
Database altered.
SQL> select open_mode from v$database;
OPEN_MODE
--------------------
READ WRITE
SQL> select * from test;
ID NAME
---------- ----------
10 Tom
SQL> insert into test values('30', 'Jason');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from test;
ID NAME
---------- ----------
10 Tom
30 Jason
转换到snapshot后,对主库做的更改数据有没有被应用。
在Standby端,有两套体系。从Primary传输来的归档日志,不断地在Archived Redo Log中集合积累,只是没有被Apply。同时,Online redo log体系中,通过reset log,日志sequence系列从1开始重新计数。
6) 将snapshot转为physical standby
切换到mout状态
shutdown immediate
startup mount
alter database convert to physical standby;
SQL> select open_mode, database_role, protection_mode from v$database;
OPEN_MODE DATABASE_ROLE PROTECTION_MODE
-------------------- ---------------- --------------------
MOUNTED PHYSICAL STANDBY MAXIMUM PERFORMANCE
alter database open;
7)打开备库real apply
alter database recover managed standby database using current logfile disconnect from session;
8)检查备库中test表数据
SQL> select * from test;
ID NAME
---------- ----------
10 Tom
20 Mike
Snapshot 的测试数据被丢弃,主库的更改已经被应用。
7.11.Standby Nologging
In versions before 18c, when configuring Data Guard, the only option we had for the logging property of the databases other than the default, was enabling FORCE LOGGING as:
ALTER DATABASE FORCE LOGGING;
Starting with 18c, we have the following new options:
ALTER DATABASE SET STANDBY NOLOGGING FOR DATA AVAILABILITY;
or
ALTER DATABASE SET STANDBY NOLOGGING FOR LOAD PERFORMANCE;
The names give away what to expect from them, but here are their descriptions from the documentation:
Enable an Appropriate Logging Mode
- STANDBY NOLOGGING FOR DATA AVAILABILITY mode causes the load operation to send the loaded data to each standby through its own connection to the standby. The commit is delayed until all the standbys have applied the data as part of running managed recovery in an Active Data Guard environment.
- STANDBY NOLOGGING FOR LOAD PERFORMANCE is similar to the previous mode except that the loading process can stop sending the data to the standbys if the network cannot keep up with the speed at which data is being loaded to the primary. In this mode it is possible that the standbys may have missing data, but each standby automatically fetches the data from the primary as a normal part of running managed recovery in an Active Data Guard environment.
So DATA AVAILABILITY and LOAD PERFORMANCE NOLOGGING modes are kind of similar to how the MAXIMUM AVAILABILITY and MAXIMUM PERFORMANCE Data Guard modes operate.
One important thing to notice here: these options work in an Active Data Guard environment, which is and extra cost option and needs to be licensed on top of Enterprise Edition.
Another important thing from the Licensing Manual:

Notice the N under Enteprise Edition (N). The above means these features can not be used in regular on-premise Enterprise Edition databases, even if licensed with the Active Data Guard options. As of now, these new features can be used only on Engineered Systems (EE-ES) and Database Cloud Service (DBCS).
Below I have Active Data Guard configured between my primary database VIR_O73 (running on host O73) and my standby database VIR_O74 (running on host O74). The version is 18.4 as it can be seen from the output. I have already enabled NOLOGGING FOR DATA AVAILABILITY. These are 2 Oracle Linux 7.5 virtual machines running on a KVM test environment, which is clearly not Cloud or an Engineered System. To “emulate” Exadata for the above feature, I used the good old “_exadata_feature_on” parameter.
Simulate an Exadata using the hidden parameter “_exadata_feature_on” on both servers (do not in production).
alter system set "\_exadata_feature_on"=true scope=spfile;
After both databases restart let’s try:
[oracle@o73 ~]$ dgmgrl /
DGMGRL for Linux: Release 18.0.0.0.0 - Production on Mon Dec 31 18:02:40 2018
Version 18.4.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Welcome to DGMGRL, type "help" for information.
Connected to "VIR_O73"
Connected as SYSDG.
DGMGRL> show configuration
Configuration - virdr
Protection Mode: MaxAvailability
Members:
vir_o73 - Primary database
vir_o74 - Physical standby database
Fast-Start Failover: DISABLED
Configuration Status:
SUCCESS (status updated 12 seconds ago)
DGMGRL>
The primary database:
[oracle@o73 ~]$ sqlplus -S / as sysdba
select force_logging from v¥database;
FORCE_LOGGING
---------------------------------------
STANDBY NOLOGGING FOR DATA AVAILABILITY
show parameter _exadata_feature_on
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
_exadata_feature_on boolean TRUE
exit
[oracle@o73 ~]
The standby database:
[oracle@o74 ~] sqlplus -S / as sysdba
select open_mode from v$database;
OPEN_MODE
--------------------
READ ONLY WITH APPLY
show parameter _exadata_feature_on
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
_exadata_feature_on boolean TRUE
exit
[oracle@o74 ~]
Setting up the environment in the primary database for testing. This means creating a tablespace, a user, and fairly large (3GB) table:
SQL> create tablespace bp_ts datafile size 1G autoextend on next 1G maxsize 8G;
Tablespace created.
SQL> create user bp identified by bp default tablespace bp_ts quota unlimited on bp_ts;
User created.
SQL> grant create table, create session, select_catalog_role to bp;
Grant succeeded.
SQL> create table bp.t1 as select * from dba_objects;
Table created.
SQL> insert into bp.t1 select * from bp.t1;
22744 rows created.
SQL> /
45488 rows created.
SQL> /
90976 rows created.
SQL> /
181952 rows created.
SQL> /
363904 rows created.
SQL> /
727808 rows created.
SQL> /
1455616 rows created.
SQL> /
2911232 rows created.
SQL> /
5822464 rows created.
SQL> /
11644928 rows created.
SQL> commit;
Commit complete.
SQL> select bytes/1024/1024 from user_segments where segment_name = 'T1';
BYTES/1024/1024
---------------
3072
SQL> set sqlprompt 'SYS - VIR_O73> '
SYS - VIR_O73> conn / as sysdba
Connected.
SYS - VIR_O73>
Querying it on the standby from another session:
SQL> set sqlprompt 'SYS - VIR_O74> '
SYS - VIR_O74> select count(*) from bp.t1;
COUNT(*)
----------
23289856
SYS - VIR_O74>
For a start, let’s check if the promised feature really works. On the primary database copy this table with a nologging CTAS:
SYS - VIR_O73> set timing on
SYS - VIR_O73> select ss.value from v¥sesstat ss join v$statname sn on (ss.statistic# = sn.statistic#) where sn.name = 'redo size' and ss.sid = sys_context('userenv', 'sid');
VALUE
----------
0
Elapsed: 00:00:00.00
SYS - VIR_O73> create table bp.t2 nologging as select * from bp.t1;
Table created.
Elapsed: 00:00:40.04
SYS - VIR_O73> select ss.value from v¥sesstat ss join v¥statname sn on (ss.statistic# = sn.statistic#) where sn.name = 'redo size' and ss.sid = sys_context('userenv', 'sid');
VALUE
----------
980472
Elapsed: 00:00:00.01
SYS - VIR_O73>
So I copied a 3 GB table and that generated a little less than 1 MB redo. Querying this new table right after on the standby:
SYS - VIR_O74> select count(*) from bp.t2;
COUNT(*)
----------
23289856
Elapsed: 00:00:07.43
SYS - VIR_O74>
8.性能调优
ASYNC is DEFAULT attribute. When the default mode of ASYNC is used, the log network server (LNS) process does not wait for each network I/O to complete before proceeding to minimize the overhead of Oracle Data Guard on the primary database. To ensure minimal overhead of Oracle Data Guard when operating in ASYNC mode, LNS will always attempt to read redo from the log buffer to avoid disk I/O; should the log buffer have been flushed, LNS will then read from online redo and subsequently archived redo. Obviously, in this case it is more efficient for LNS to read from the log buffer (instead of performing physical I/O), so we should ensure that LNS is reading from the log buffer as often as possible. To check how often LNS is reading from the log buffer, we can query x$logbuf_readhist.