Oracle 教程 Online Redo Log
1. 简介
Oracle 的Online Redo Log(ORL) 是为确保已经提交的事务不会丢失而建立的一个机制。 因为这种健全的机制,才能让我们在数据库Crash时,恢复数据,保证数据不丢失。
在数据库操作中,只要有任何的数据块变化,都会生成相应的Redo Entry。Redo Entry首先保存在Log Buffer中,最后由LGWR进程写入到Redo Log里面。
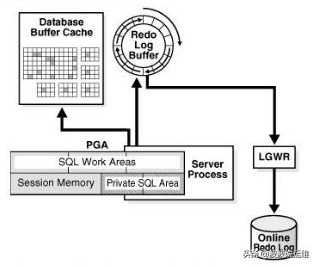
ORL文件的主要作用是记录所有的数据变化和提供一种数据恢复机制。
例如:当数据库中一个事务提交commit的时候,由server process修改Database Buffer Cache中的数据,修改的数据块(脏数据块)不会直接写回到数据文件中。但是commit动作是会触发LGWR进程将事务生成的ORL写入到ORL文件中。
假事务执行过程中时发生数据库突然崩溃事故,在内存中的数据块将会丢失。DBWn还没有将database buffer cache中的脏数据块刷新到数据文件中,同时在实例崩溃时正在运行着的事务被突然中断,则事务为中间状态,也就是既没有提交也没有回滚。这时数据文件里的内容不能体现实例崩溃时的状态。这样关闭的数据库是不一致的。
实例启动时,SMON进程会去检查控制文件中所记录的、每个在线的、可读写的数据文件的END SCN号。
数据库正常运行过程中,控制文件的END SCN号始终为NULL,当数据库正常关闭时,会进行完全检查点,并用检查点SCN号更新控制文件的END SCN。
实例崩溃时,Oracle还来不及更新控制文件的END SCN号,该字段仍然为NULL。当SMON进程发现该字段为空时,就知道实例在上次没有正常关闭,于是由SMON进程就开始进行实例恢复,进行数据库事务重演。
1.1.LGWR写ORL
以下5种情况会触发LGWR写ORL:
1:当一个事务commit的时候
2:每三秒钟LGWR写ORL
3:Redo Log Buffer 1/3满的时候
4:When there is more than a megabyte of changed records in the Redo Log Buffer.
5:产生checkpoints时,DBWn把Database Buffer Cache中的数据写入磁盘之前,触发LGWR写ORL
2.What Is the Redo Log?
What Is the Redo Log?
The most crucial structure for recovery operations is the redo log, which consists of two or more preallocated files that store all changes made to the database as they occur. Every instance of an Oracle Database has an associated redo log to protect the database in case of an instance failure.
Redo Threads
When speaking in the context of multiple database instances, the redo log for each database instance is also referred to as a redo thread.
Redo Log Contents
Redo log files are filled with redo records.
2.1.Redo Threads
When speaking in the context of multiple database instances, the redo log for each database instance is also referred to as a redo thread.
In typical configurations, only one database instance accesses an Oracle Database, so only one thread is present. In an Oracle Real Application Clusters environment, however, two or more instances concurrently access a single database and each instance has its own thread of redo. A separate redo thread for each instance avoids contention for a single set of redo log files, thereby eliminating a potential performance bottleneck.
This chapter describes how to configure and manage the redo log on a standard single-instance Oracle Database. The thread number can be assumed to be 1 in all discussions and examples of statements.
2.2.Redo Log Contents
Redo log files are filled with redo records.
A redo record, also called a redo entry, is made up of a group of change vectors, each of which is a description of a change made to a single block in the database. For example, if you change a salary value in an employee table, you generate a redo record containing change vectors that describe changes to the data segment block for the table, the undo segment data block, and the transaction table of the undo segments.
Redo entries record data that you can use to reconstruct all changes made to the database, including the undo segments. Therefore, the redo log also protects rollback data. When you recover the database using redo data, the database reads the change vectors in the redo records and applies the changes to the relevant blocks.
Redo records are buffered in a circular fashion in the redo log buffer of the SGA and are written to one of the redo log files by the Log Writer (LGWR) database background process. Whenever a transaction is committed, LGWR writes the transaction redo records from the redo log buffer of the SGA to a redo log file, and assigns a system change number (SCN) to identify the redo records for each committed transaction. Only when all redo records associated with a given transaction are safely on disk in the online logs is the user process notified that the transaction has been committed.
Redo records can also be written to a redo log file before the corresponding transaction is committed. If the redo log buffer fills, or another transaction commits, LGWR flushes all of the redo log entries in the redo log buffer to a redo log file, even though some redo records may not be committed. If necessary, the database can roll back these changes.
3.How Oracle Database Writes to the Redo Log
The redo log for a database consists of two or more redo log files. The database requires a minimum of two files to guarantee that one is always available for writing while the other is being archived (if the database is in ARCHIVELOG mode).
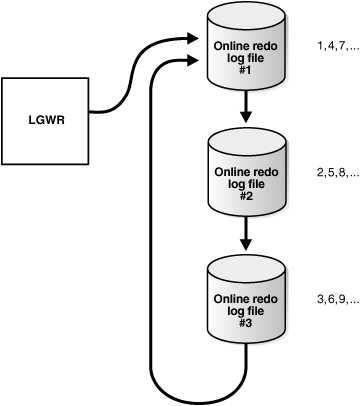
LGWR writes to redo log files in a circular fashion. When the current redo log file fills, LGWR begins writing to the next available redo log file. When the last available redo log file is filled, LGWR returns to the first redo log file and writes to it, starting the cycle again. Figure 11-1 illustrates the circular writing of the redo log file. The numbers next to each line indicate the sequence in which LGWR writes to each redo log file.
Filled redo log files are available to LGWR for reuse depending on whether archiving is enabled.
- If archiving is disabled (the database is in NOARCHIVELOG mode), a filled redo log file is available after the changes recorded in it have been written to the data files.
- If archiving is enabled (the database is in ARCHIVELOG mode), a filled redo log file is available to LGWR after the changes recorded in it have been written to the data files and the file has been archived.
Figure 11-1 Reuse of Redo Log Files by LGWR
3.1.Active (Current) and Inactive Redo Log Files
Oracle Database uses only one redo log file at a time to store redo records written from the redo log buffer. The redo log file that LGWR is actively writing to is called the current redo log file.
Redo log files that are required for instance recovery are called active redo log files. Redo log files that are no longer required for instance recovery are called inactive redo log files.
If you have enabled archiving (the database is in ARCHIVELOG mode), then the database cannot reuse or overwrite an active online log file until one of the archiver background processes (ARCn) has archived its contents. If archiving is disabled (the database is in NOARCHIVELOG mode), then when the last redo log file is full, LGWR continues by overwriting the next log file in the sequence when it becomes inactive.
3.2.Log Switches and Log Sequence Numbers
A log switch is the point at which the database stops writing to one redo log file and begins writing to another. Normally, a log switch occurs when the current redo log file is completely filled and writing must continue to the next redo log file.
However, you can configure log switches to occur at regular intervals, regardless of whether the current redo log file is completely filled. You can also force log switches manually.
Oracle Database assigns each redo log file a new log sequence number every time a log switch occurs and LGWR begins writing to it. When the database archives redo log files, the archived log retains its log sequence number. A redo log file that is cycled back for use is given the next available log sequence number.
Each online or archived redo log file is uniquely identified by its log sequence number. During crash, instance, or media recovery, the database properly applies redo log files in ascending order by using the log sequence number of the necessary archived and redo log files.
4.Planning the Redo Log
4.1 Multiplexing Redo Log File
To protect against a failure involving the redo log itself, Oracle Database allows a multiplexed redo log, meaning that two or more identical copies of the redo log can be automatically maintained in separate locations.
For the most benefit, these locations should be on separate disks. Even if all copies of the redo log are on the same disk, however, the redundancy can help protect against I/O errors, file corruption, and so on. When redo log files are multiplexed, LGWR concurrently writes the same redo log information to multiple identical redo log files, thereby eliminating a single point of redo log failure.
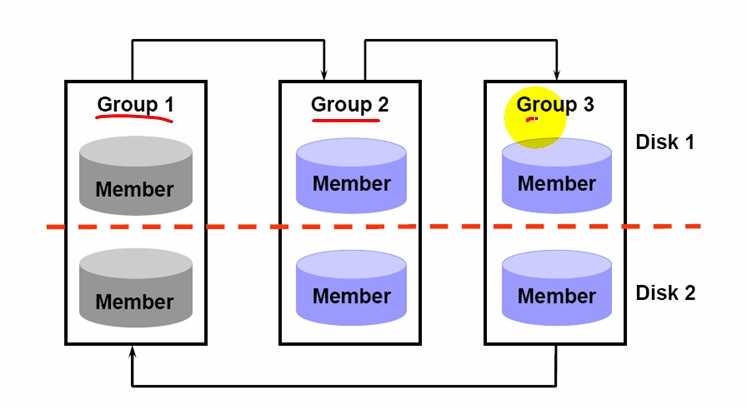
Multiplexing is implemented by creating groups of redo log files. A group consists of a redo log file and its multiplexed copies. Each identical copy is said to be a member of the group. Each redo log group is defined by a number, such as group 1, group 2, and so on.
Figure 11-2 Multiplexed Redo Log Files
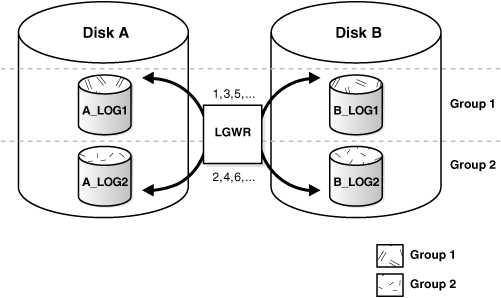
A_LOG1 and B_LOG1 are both members of Group 1, A_LOG2 and B_LOG2 are both members of Group 2, and so forth. Each member in a group must be the same size.
Each member of a log file group is concurrently active—that is, concurrently written to by LGWR—as indicated by the identical log sequence numbers assigned by LGWR. In Figure 11-2, first LGWR writes concurrently to both A_LOG1 and B_LOG1. Then it writes concurrently to both A_LOG2 and B_LOG2, and so on. LGWR never writes concurrently to members of different groups (for example, to A_LOG1 and B_LOG2).
Note: Oracle recommends that you multiplex your redo log files. The loss of the log file data can be catastrophic if recovery is required. Note that when you multiplex the redo log, the database must increase the amount of I/O that it performs. Depending on your configuration, this may impact overall database performance.
4.1.1.Responding to Redo Log Failure
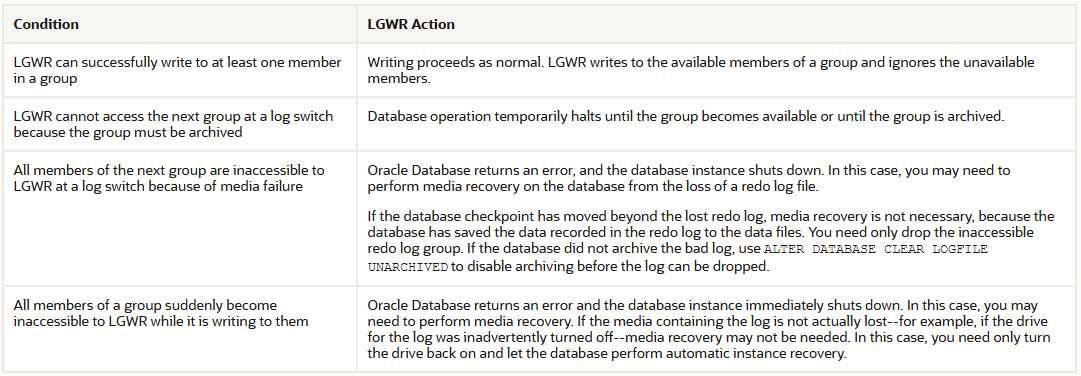
Whenever LGWR cannot write to a member of a group, the database marks that member as INVALID and writes an error message to the LGWR trace file and to the database alert log to indicate the problem with the inaccessible files.
The specific reaction of LGWR when a redo log member is unavailable depends on the reason for the lack of availability, as summarized in the table that follows.
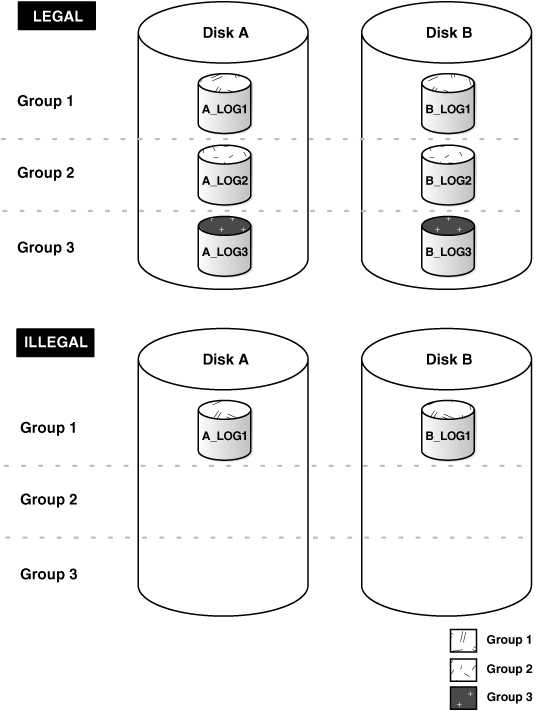
4.1.2.Legal and Illegal Configurations
In most cases, a multiplexed redo log should be symmetrical: all groups of the redo log should have the same number of members. However, the database does not require that a multiplexed redo log be symmetrical.
For example, one group can have only one member, and other groups can have two members. This configuration protects against disk failures that temporarily affect some redo log members but leave others intact.
The only requirement for an instance redo log is that it have at least two groups. Figure 11-3 shows legal and illegal multiplexed redo log configurations. The second configuration is illegal because it has only one group.
Figure 11-3 Legal and Illegal Multiplexed Redo Log Configuration
4.2.Placing Redo Log Members on Different Disks
When setting up a multiplexed redo log, place members of a group on different physical disks. If a single disk fails, then only one member of a group becomes unavailable to LGWR and other members remain accessible to LGWR, so the instance can continue to function.
If you archive the redo log, spread redo log members across disks to eliminate contention between the LGWR and ARCn background processes. For example, if you have two groups of multiplexed redo log members (a duplexed redo log), place each member on a different disk and set your archiving destination to a fifth disk. Doing so will avoid contention between LGWR (writing to the members) and ARCn (reading the members).
Data files should also be placed on different disks from redo log files to reduce contention in writing data blocks and redo records.
4.3.Planning the Size of Redo Log Files
When setting the size of redo log files, consider whether you will be archiving the redo log. Redo log files should be sized so that a filled group can be archived to a single unit of offline storage media (such as a tape or disk), with the least amount of space on the medium left unused.
For example, suppose only one filled redo log group can fit on a tape and 49% of the tape storage capacity remains unused. In this case, it is better to decrease the size of the redo log files slightly, so that two log groups could be archived on each tape.
All members of the same multiplexed redo log group must be the same size. Members of different groups can have different sizes. However, there is no advantage in varying file size between groups. If checkpoints are not set to occur between log switches, make all groups the same size to guarantee that checkpoints occur at regular intervals.
The minimum size permitted for a redo log file is 4 MB.
用ORACLE的安装向导创建的数据库,它的Redo Log File大小有可能不能满足典型的OLTP应用, 在数据库日志文件(alert_orasid.log)里会记录着频繁的Logswitch。
ORACLE推荐Logswitch时间最好在15–30分钟之间, 所以Redo Log File的大小由数据库DML操作数据量的大小决定其最佳大小。
4.4.Planning the Block Size of Redo Log Files
Unlike the database block size, which can be between 2K and 32K, redo log files always default to a block size that is equal to the physical sector size of the disk. Historically, this has typically been 512 bytes (512B).
Some newer high-capacity disk drives offer 4K byte (4K) sector sizes for both increased ECC capability and improved format efficiency. Most Oracle Database platforms are able to detect this larger sector size. The database then automatically creates redo log files with a 4K block size on those disks.
However, with a block size of 4K, there is increased redo wastage. In fact, the amount of redo wastage in 4K blocks versus 512B blocks is significant. You can determine the amount of redo wastage by viewing the statistics stored in the V¥SESSTAT and V$SYSSTAT views.
SQL> SELECT name, value FROM v$sysstat WHERE name = 'redo wastage';
NAME VALUE
-------------------------------- ----------
redo wastage 17941684
To avoid the additional redo wastage, if you are using emulation-mode disks—4K sector size disk drives that emulate a 512B sector size at the disk interface—you can override the default 4K block size for redo logs by specifying a 512B block size or, for some platforms, a 1K block size. However, you will incur a significant performance degradation when a redo log write is not aligned with the beginning of the 4K physical sector. Because seven out of eight 512B slots in a 4K physical sector are not aligned, performance degradation typically does occur. Thus, you must evaluate the trade-off between performance and disk wastage when planning the redo log block size on 4K sector size emulation-mode disks.
You can specify the block size of online redo log files with the BLOCKSIZE keyword in the CREATE DATABASE, ALTER DATABASE, and CREATE CONTROLFILE statements. On some platforms, the permissible block sizes are 512 and 4096. On other platforms, the permissible block sizes are 1024 and 4096.
The following statement adds a redo log file group with a block size of 512B. The BLOCKSIZE 512 clause is valid but not required for 512B sector size disks. For 4K sector size emulation-mode disks, the BLOCKSIZE 512 clause overrides the default 4K size.
ALTER DATABASE orcl ADD LOGFILE
GROUP 4 ('/u01/logs/orcl/redo04a.log','/u01/logs/orcl/redo04b.log')
SIZE 100M BLOCKSIZE 512 REUSE;
To ascertain the redo log file block size, run the following query:
SQL> SELECT BLOCKSIZE FROM V$LOG;
BLOCKSIZE
---------
512
4.5.Choosing the Number of Redo Log Files
The best way to determine the appropriate number of redo log files for a database instance is to test different configurations. The optimum configuration has the fewest groups possible without hampering LGWR from writing redo log information.
In some cases, a database instance may require only two groups. In other situations, a database instance may require additional groups to guarantee that a recycled group is always available to LGWR. During testing, the easiest way to determine whether the current redo log configuration is satisfactory is to examine the contents of the LGWR trace file and the database alert log. If messages indicate that LGWR frequently has to wait for a group because a checkpoint has not completed or a group has not been archived, add groups.
Consider the parameters that can limit the number of redo log files before setting up or altering the configuration of an instance redo log. The following parameters limit the number of redo log files that you can add to a database:
- The MAXLOGFILES parameter used in the CREATE DATABASE statement determines the maximum number of groups of redo log files for each database. Group values can range from 1 to MAXLOGFILES. You can exceed the MAXLOGFILES limit, and the control files expand as needed. If MAXLOGFILES is not specified for the CREATE DATABASE statement, then the database uses an operating system specific default value.
- The MAXLOGMEMBERS parameter used in the CREATE DATABASE statement determines the maximum number of members for each group. As with MAXLOGFILES, the only way to override this upper limit is to re-create the database or control file. Therefore, it is important to consider this limit before creating a database. If no MAXLOGMEMBERS parameter is specified for the CREATE DATABASE statement, then the database uses an operating system default value.
SQL> alter database backup controlfile to trace;
SQL> select d.value||b.bias||lower(rtrim(i.instance, chr(0)))||'_ora_'||p.spid||'.trc' trace_file_name from
( select p.spid from sys.v£mystat m, sys.v£session s, sys.v£process p
where m.statistic# = 1 and s.sid = m.sid and p.addr = s.paddr) p,
( select t.instance from sys.v£thread t,sys.v£parameter v
where v.name = 'thread' and (v.value = 0 or t.thread# = to_number(v.value))) i,
( select value from sys.v£parameter where name = 'user_dump_dest') d,
( select DECODE(count(BANNER),0,'/','\') bias
from v$version where upper(banner) like '%WINDOWS%') b;
TRACE_FILE_NAME
--------------------------------------------------------------------------------
/oracle/app/oracle/12.2.0.1/rdbms/log/hamster_ora_71043.trc
这条语句会在\$ORACLE_BASE/12.2.0.1/rdbms/log/路径下生成当前时间的一个*.trc文件,也就是数据库的控制文件,用文本编辑器,即可看到数据库创建时用的一些参数, 包括Redo Log File的最大数(MAXLOGFILES), 每组最大的成员个数(MAXLOGMEMBERS)。
4.6.Controlling Archive Lag
You can force all enabled redo log threads to switch their current logs at regular time intervals.
In a primary/standby database configuration, changes are made available to the standby database by archiving redo logs at the primary site and then shipping them to the standby database. The changes that are being applied by the standby database can lag behind the changes that are occurring on the primary database, because the standby database must wait for the changes in the primary database redo log to be archived (into the archived redo log) and then shipped to it. To limit this lag, you can set the ARCHIVE_LAG_TARGET initialization parameter. Setting this parameter lets you specify in seconds how long that lag can be.
4.6.1Setting the ARCHIVE_LAG_TARGET Initialization Parameter
When you set the ARCHIVE_LAG_TARGET initialization parameter, you cause the database to examine the current redo log for the instance periodically and determine when to switch the log.
If the following conditions are met, then the instance will switch the log:
- The current log was created before n seconds ago, and the estimated archival time for the current log is m seconds (proportional to the number of redo blocks used in the current log), where n + m exceeds the value of the ARCHIVE_LAG_TARGET initialization parameter.
- The current log contains redo records.
In an Oracle Real Application Clusters environment, the instance also causes other threads to switch and archive their logs if they are falling behind. This can be particularly useful when one instance in the cluster is more idle than the other instances (as when you are running a 2-node primary/secondary configuration of Oracle Real Application Clusters).
The ARCHIVE_LAG_TARGET initialization parameter provides an upper limit for how long (in seconds) the current log of the database can span. Because the estimated archival time is also considered, this is not the exact log switch time.
– Set the ARCHIVE_LAG_TARGET initialization parameter.
The following initialization parameter setting sets the log switch interval to 30 minutes (a typical value).
ARCHIVE_LAG_TARGET = 1800
A value of 0 disables this time-based log switching functionality. This is the default setting.
You can set the ARCHIVE_LAG_TARGET initialization parameter even if there is no standby database. For example, the ARCHIVE_LAG_TARGET parameter can be set specifically to force logs to be switched and archived.
ARCHIVE_LAG_TARGET is a dynamic parameter and can be set with the ALTER SYSTEM SET statement.
Note: The ARCHIVE_LAG_TARGET parameter must be set to the same value in all instances of an Oracle Real Application Clusters environment. Failing to do so results in unpredictable behavior.
4.6.2.Factors Affecting the Setting of ARCHIVE_LAG_TARGET
There are several factors to consider when you are setting the ARCHIVE_LAG_TARGET initialization parameter.
Consider the following factors when determining if you want to set the ARCHIVE_LAG_TARGET initialization parameter and in determining the value for this parameter.
- Overhead of switching (as well as archiving) logs
- How frequently normal log switches occur as a result of log full conditions
- How much redo loss is tolerated in the standby database
Setting ARCHIVE_LAG_TARGET may not be very useful if natural log switches already occur more frequently than the interval specified. However, in the case of irregularities of redo generation speed, the interval does provide an upper limit for the time range each current log covers.
If the ARCHIVE_LAG_TARGET initialization parameter is set to a very low value, there can be a negative impact on performance. This can force frequent log switches. Set the parameter to a reasonable value so as not to degrade the performance of the primary database.
5.Redo Log Group and Member
Online Redo Log Group是一系列完全相同的ORL文件的集合。在一个数据库中,至少要有两个Redo Log Group交替进行写入操作。建议使用至少三个日志组。
下图 显示了 group 和 member 的概念 以及显示了 在不同的 磁盘 disk上。
5.1 Redo Log的六种状态
- CURRENT
The online redo log is active, that is, needed for instance recovery, and it is the log to which the database is currently writing. The redo log can be open orclosed.
- ACTIVE
The online redo log is active and required for instance recovery, but is not the log to which the database is currently writing. It may be in use for blockrecovery, and may or may not be archived. Once perform “alter system checkpoint”,the log will be change inactive.
- INACTIVE
The log is no longer needed for instance recovery. It may be in use for media recovery,and may or may not be archived.
- UNUSED
The online redo log has never been written to.
- CLEARING
The log is being re-created as an empty log after an ALTER DATABASECLEAR LOGFILE statement. After the log is cleared, then the status changes to UNUSED.
- CLEARING_CURRENT
Current log is being cleared of a closed thread. The log can stay in this status if there is some failure in the switch such as an I/O error writing thenew log header. . .
The ALTER DATABASE CLEAR LOGFILE statement can fail with an I/O error due to media failure when it is not possible to:
Relocate the redo log file onto alternative media by re-creating it under the currently configured redo log filename
Reuse the currently configured log filename to re-create the redo log file because the name itself is invalid or unusable (for example, due to media failure)
5.2 View Online Redo Log Groups and Members
- A set of identical copies of online redo log files is called an online redo log file group
- The LGWR backgroundprocess concurrently writes the same information to all online redo log files in a group
- The Oracle server needs a minimum of two online redo log file groups for the nomal operation of a database
v$log视图
SQL> select group#, sequence#, bytes, members, status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 1 209715200 1 ACTIVE
2 2 209715200 1 CURRENT
3 0 209715200 1 UNUSED
status:当前日志的状态。
- Current:当前正在进行写入的日志组,也是最新的日志组;
- Active:当一个事务完成commit之后,redo entry写入到了日志文件。并且这个日志已经不是当前current,但是对应的脏数据块data block还没有从database buffer cache中写入到文件中。此时,日志组状态为active。处在active状态的日志组,是不能够被覆盖和删除的;
- Inactive:日志并不是当前正在读写的日志,并且对应的事务数据块都已经写回到数据文件中;
- Unused:表示新创建的online日志组,还没有使用过;
v$logfile视图
set linesize 500
col member for a50
select group#,type,member from v$logfile order by 1;
GROUP# TYPE MEMBER
---------- ------- --------------------------------------------------
1 ONLINE /oradata/data/HAMSTER/redo01.log
2 ONLINE /oradata/data/HAMSTER/redo02.log
3 ONLINE /oradata/data/HAMSTER/redo03.log
5.3.Creating Redo Log Groups
To create a new group of redo log files, use the SQL statement ALTER DATABASE with the ADD LOGFILE clause.
For example, the following statement adds a new group of redo logs to the database:
ALTER DATABASE
ADD LOGFILE ('/oracle/dbs/log1c.rdo', '/oracle/dbs/log2c.rdo') SIZE 100M;
Note: Provide full path names of new log members to specify their location. Otherwise, the files are created in either the default or current directory of the database server, depending upon your operating system.
You can also specify the number that identifies the group using the GROUP clause:
ALTER DATABASE
ADD LOGFILE GROUP 10 ('/oracle/dbs/log1c.rdo', '/oracle/dbs/log2c.rdo')
SIZE 100M BLOCKSIZE 512;
Using group numbers can make administering redo log groups easier. However, the group number must be between 1 and MAXLOGFILES. Do not skip redo log file group numbers (that is, do not number your groups 10, 20, 30, and so on), or you will consume unnecessary space in the control files of the database.
In the preceding statement, the BLOCKSIZE clause is optional.
5.4.Creating Redo Log Members
Member:
- Each online redo log file in a group is called a member
- Each member in a group has identical log sequence numbers and are of the same size.
- The LSN(log sequence number ) is assigned each time that the Oracle server writes to a log group to uniquely identify each online redo log file
In some cases, it might not be necessary to create a complete group of redo log files. A group could already exist, but not be complete because one or more members of the group were dropped (for example, because of a disk failure). In this case, you can add new members to an existing group.
To create new redo log members for an existing group:
- Run the SQL statement ALTER DATABASE with the ADD LOGFILE MEMBER clause.
For example, the following statement adds a new redo log member to redo log group number 2:
ALTER DATABASE ADD LOGFILE MEMBER '/oracle/dbs/log2b.rdo' TO GROUP 2;
Notice that file names must be specified, but sizes need not be. The size of the new members is determined from the size of the existing members of the group.
When using the ALTER DATABASE statement, you can alternatively identify the target group by specifying all of the other members of the group in the TO clause, as shown in the following example:
ALTER DATABASE ADD LOGFILE MEMBER '/oracle/dbs/log2c.rdo'
TO ('/oracle/dbs/log2a.rdo', '/oracle/dbs/log2b.rdo');
Note: Fully specify the file names of new log members to indicate where the operating system files should be created. Otherwise, the files will be created in either the default or current directory of the database server, depending upon your operating system. You may also note that the status of the new log member is shown as INVALID. This is normal and it will change to active (blank) when it is first used.
5.5.Relocating and Renaming Redo Log Members
You can use operating system commands to relocate redo logs, then use the ALTER DATABASE statement to make their new names (locations) known to the database.
This procedure is necessary, for example, if the disk currently used for some redo log files is going to be removed, or if data files and several redo log files are stored on the same disk and should be separated to reduce contention.
To rename redo log members, you must have the ALTER DATABASE system privilege. Additionally, you might also need operating system privileges to copy files to the desired location and privileges to open and back up the database.
Before relocating your redo logs, or making any other structural changes to the database, completely back up the database in case you experience problems while performing the operation. As a precaution, after renaming or relocating a set of redo log files, immediately back up the database control file.
Use the following steps for relocating redo logs. The example used to illustrate these steps assumes:
- The log files are located on two disks: diska and diskb.
- The redo log is duplexed: one group consists of the members /diska/logs/log1a.rdo and /diskb/logs/log1b.rdo, and the second group consists of the members /diska/logs/log2a.rdo and /diskb/logs/log2b.rdo.
- The redo log files located on diska must be relocated to diskc. The new file names will reflect the new location: /diskc/logs/log1c.rdo and /diskc/logs/log2c.rdo.
To rename redo log members:
1. Shut down the database.
2. Copy the redo log files to the new location.
Operating system files, such as redo log members, must be copied using the appropriate operating system commands. See your operating system specific documentation for more information about copying files.
Note: You can execute an operating system command to copy a file (or perform other operating system commands) without exiting SQL*Plus by using the HOST command. Some operating systems allow you to use a character in place of the word HOST. For example, you can use an exclamation point (!) in UNIX.
The following example uses operating system commands (UNIX) to move the redo log members to a new location:
mv /diska/logs/log1a.rdo /diskc/logs/log1c.rdo
mv /diska/logs/log2a.rdo /diskc/logs/log2c.rdo
- Startup the database, mount, but do not open it.
STARTUP MOUNT
- Rename the redo log members.
Use the ALTER DATABASE statement with the RENAME FILE clause to rename the database redo log files.
ALTER DATABASE
RENAME FILE '/diska/logs/log1a.rdo', '/diska/logs/log2a.rdo'
TO '/diskc/logs/log1c.rdo', '/diskc/logs/log2c.rdo';
- Open the database for normal operation.
The redo log alterations take effect when the database is opened.
ALTER DATABASE OPEN;
5.6.Dropping Log Groups
You can drop a redo log group.
To drop a redo log group, you must have the ALTER DATABASE system privilege. Before dropping a redo log group, consider the following restrictions and precautions:
- An instance requires at least two groups of redo log files, regardless of the number of members in the groups. (A group comprises one or more members.)
- You can drop a redo log group only if it is inactive. If you must drop the current group, then first force a log switch to occur.
- Make sure a redo log group is archived (if archiving is enabled) before dropping it. To see whether this has happened, use the V$LOG view.
SELECT GROUP#, ARCHIVED, STATUS FROM V$LOG;
GROUP# ARC STATUS
--------- --- ----------------
1 YES ACTIVE
2 NO CURRENT
3 YES INACTIVE
4 YES INACTIVE
To drop a redo log group:
- Run the SQL statement ALTER DATABASE with the DROP LOGFILE clause.
For example, the following statement drops redo log group number 3:
ALTER DATABASE DROP LOGFILE GROUP 3;
When a redo log group is dropped from the database, and you are not using the Oracle Managed Files feature, the operating system files are not deleted from disk. Rather, the control files of the associated database are updated to drop the members of the group from the database structure. After dropping a redo log group, ensure that the drop completed successfully, and then use the appropriate operating system command to delete the dropped redo log files.
When using Oracle Managed Files, the cleanup of operating systems files is done automatically for you.
5.7.Dropping Redo Log Members
You can drop redo log members.
To drop a redo log member, you must have the ALTER DATABASE system privilege. Consider the following restrictions and precautions before dropping individual redo log members:
- It is permissible to drop redo log files so that a multiplexed redo log becomes temporarily asymmetric. For example, if you use duplexed groups of redo log files, you can drop one member of one group, even though all other groups have two members each. However, you should rectify this situation immediately so that all groups have at least two members, and thereby eliminate the single point of failure possible for the redo log.
- An instance always requires at least two valid groups of redo log files, regardless of the number of members in the groups. (A group comprises one or more members.) If the member you want to drop is the last valid member of the group, you cannot drop the member until the other members become valid. To see a redo log file status, use the V$LOGFILE view. A redo log file becomes INVALID if the database cannot access it. It becomes STALE if the database suspects that it is not complete or correct. A stale log file becomes valid again the next time its group is made the active group.
- You can drop a redo log member only if it is not part of an active or current group. To drop a member of an active group, first force a log switch to occur.
- Make sure the group to which a redo log member belongs is archived (if archiving is enabled) before dropping the member. To see whether this has happened, use the V$LOG view.
To drop specific inactive redo log members:
- Run the ALTER DATABASE statement with the DROP LOGFILE MEMBER clause.
The following statement drops the redo log /oracle/dbs/log3c.rdo:
ALTER DATABASE DROP LOGFILE MEMBER '/oracle/dbs/log3c.rdo';
When a redo log member is dropped from the database, the operating system file is not deleted from disk. Rather, the control files of the associated database are updated to drop the member from the database structure. After dropping a redo log file, ensure that the drop completed successfully, and then use the appropriate operating system command to delete the dropped redo log file.
To drop a member of an active group, you must first force a log switch.
5.8.Forcing Log Switches
A log switch occurs when LGWR stops writing to one redo log group and starts writing to another. By default, a log switch occurs automatically when the current redo log file group fills.
You can force a log switch to make the currently active group inactive and available for redo log maintenance operations. For example, you want to drop the currently active group, but are not able to do so until the group is inactive. You may also want to force a log switch if the currently active group must be archived at a specific time before the members of the group are completely filled. This option is useful in configurations with large redo log files that take a long time to fill.
To force a log switch, you must have the ALTER SYSTEM privilege.
To force a log switch,
- Run the ALTER SYSTEM statement with the SWITCH LOGFILE clause.
For example, the following statement forces a log switch:
ALTER SYSTEM SWITCH LOGFILE;
5.9.Verifying Blocks in Redo Log Files
You can configure the database to use checksums to verify blocks in the redo log files.
If you set the initialization parameter DB_BLOCK_CHECKSUM to TYPICAL (the default), then the database computes a checksum for each database block when it is written to disk, including each redo log block as it is being written to the current log. The checksum is stored the header of the block.
Oracle Database uses the checksum to detect corruption in a redo log block. The database verifies the redo log block when the block is read from an archived log during recovery and when it writes the block to an archive log file. An error is raised and written to the alert log if corruption is detected.
If corruption is detected in a redo log block while trying to archive it, the system attempts to read the block from another member in the group. If the block is corrupted in all members of the redo log group, then archiving cannot proceed.
The value of the DB_BLOCK_CHECKSUM parameter can be changed dynamically using the ALTER SYSTEM statement.
Note: There is a slight overhead and decrease in database performance with DB_BLOCK_CHECKSUM enabled. Monitor your database performance to decide if the benefit of using data block checksums to detect corruption outweighs the performance impact.
5.10.Clearing a Redo Log File
A redo log file might become corrupted while the database is open, and ultimately stop database activity because archiving cannot continue.
In this situation, to reinitialize the file without shutting down the database:
- Run the ALTER DATABASE CLEAR LOGFILE SQL statement.
The following statement clears the log files in redo log group number 3:
ALTER DATABASE CLEAR LOGFILE GROUP 3;
This statement overcomes two situations where dropping redo logs is not possible:
- If there are only two log groups
- The corrupt redo log file belongs to the current group
If the corrupt redo log file has not been archived, use the UNARCHIVED keyword in the statement.
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 3;
This statement clears the corrupted redo logs and avoids archiving them. The cleared redo logs are available for use even though they were not archived.
If you clear a log file that is needed for recovery of a backup, then you can no longer recover from that backup. The database writes a message in the alert log describing the backups from which you cannot recover.
Note: If you clear an unarchived redo log file, you should make another backup of the database.
To clear an unarchived redo log that is needed to bring an offline tablespace online, use the UNRECOVERABLE DATAFILE clause in the ALTER DATABASE CLEAR LOGFILE statement.
If you clear a redo log needed to bring an offline tablespace online, you will not be able to bring the tablespace online again. You will have to drop the tablespace or perform an incomplete recovery. Note that tablespaces taken offline normal do not require recovery.
5.11.Precedence of FORCE LOGGING Settings
You can set FORCE LOGGING and NOLOGGING at various levels, such as for a database, pluggable database (PDB), tablespace, or database object. When FORCE LOGGING is set at one or more levels, the precedence of FORCE LOGGING settings determines what is logged in the redo log.
You can put a multitenant container database (CDB) and a non-CDB into FORCE LOGGING mode. In this mode, the database logs all changes in the database except for changes in temporary tablespaces and temporary segments. This setting takes precedence over and is independent of any NOLOGGING or FORCE LOGGING settings you specify for individual tablespaces and any NOLOGGING settings you specify for individual database objects.
You can also put a tablespace into FORCE LOGGING mode. The database logs all changes to all objects in the tablespace except changes to temporary segments, overriding any NOLOGGING setting for individual objects.
In addition, you can specify a logging attribute with the logging_clause for various types of database objects that determines whether certain DML operations will be logged in the redo log file (LOGGING) or not (NOLOGGING). You can specify a logging attribute for the following types of database objects:
- Tables
- Indexes
- Materialized views
The following table summarizes the logging settings at each level and shows the result for a non-CDB.
Table 11-1 Precedence of FORCE LOGGING Settings for a Non-CDB

Table 11-2 Precedence of FORCE LOGGING Settings for a CDB

5.12.Redo Log Data Dictionary Views
You can query a set of data dictionary views for information about the redo log.
The following views provide information on redo logs.

The following query returns the control file information about the redo log for a database.
SELECT GROUP#, THREAD#, SEQUENCE#, BYTES, MEMBERS, ARCHIVED,
STATUS, FIRST_CHANGE#, FIRST_TIME
FROM V$LOG;
GROUP# THREAD# SEQ BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
------ ------- ----- ------- ------- --- --------- ------------- ---------
1 1 10605 1048576 1 YES ACTIVE 11515628 16-APR-00
2 1 10606 1048576 1 NO CURRENT 11517595 16-APR-00
3 1 10603 1048576 1 YES INACTIVE 11511666 16-APR-00
4 1 10604 1048576 1 YES INACTIVE 11513647 16-APR-00
To see the names of all of the member of a group, use a query similar to the following:
SELECT GROUP#, STATUS, MEMBER FROM V$LOGFILE;
GROUP# STATUS MEMBER
------ ------- ----------------------------------
1 D:\ORANT\ORADATA\IDDB2\REDO04.LOG
2 D:\ORANT\ORADATA\IDDB2\REDO03.LOG
3 D:\ORANT\ORADATA\IDDB2\REDO02.LOG
4 D:\ORANT\ORADATA\IDDB2\REDO01.LOG
If STATUS is blank for a member, then the file is in use.
5.13.强制写ORL到数据文件中
SQL> select group#, sequence#, bytes, members, status from vlog;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 1 209715200 1 INACTIVE
2 2 209715200 1 ACTIVE
3 3 209715200 1 CURRENT
SQL> alter system checkpoint;
System altered.
SQL> select group#, sequence#, bytes, members, status from vlog;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 1 209715200 1 INACTIVE
2 2 209715200 1 INACTIVE
3 3 209715200 1 CURRENT
SQL>
5.14.fast_start_mttr_target
指定快速恢复的最大值,最大时间数,规定DBWn进程在多长时间内必须把Redo Log写到数据文件中 ,这个参数会影响I/O性能。
SQL> show parameter fast_start_mttr_target;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_mttr_target integer 0
SQL> alter system set fast_start_mttr_target = 60 scope = both;
System altered.
SQL>
6.Redo Log Size
如果数据库在运行过程中生成的Redo Log Size峰值量很高,并且持续很长时间。在Alert log上可以看到频繁的Log Switch,同时出现“check point not complete”或者“could not allocate log sequence” warning。说明日志切换过于频繁。
AWR报告中,需要关注两个与Redo Log相关的事件:
- log file parallel write
- log file sync
如果两个事件出现在top events中,DBA需要注意了。
对Redo Log的大小设置也是以切换频率而定的,要求调整到15-20分钟进行一次切换。调整的手段主要是增加日志组数量和调大日志成员文件大小。这样,可以给DBWR和ARC进程更多的时间在后台进行数据写入和归档。
6.1.案例
查看AWR,log file sync 平均等待已经超过20ms,说明DML提交很慢,很可能磁盘比较慢。先查看IO Stat by Function Summary,确认一下数据库整体IO的情况。然后分析Segments by Physical Reads、Segments by Direct Physical Writes,是否有消耗占比大的对象。如果有则优化对应的SQL。
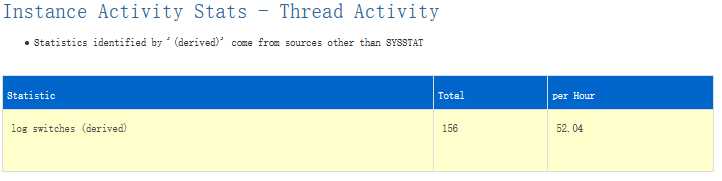
如果以上问题都没有,可能Redo Log切换太频繁。DML Commit需要把Redo Buffer写到Redo Log File才算成功,在Log Switch时,Redo Log File需要传到Archive Log,整个过程中,Commit需要等待的。查看log switches, 一个小时52次太频繁了,正常一个小时切换2到4次。
造成日志频繁切换的原因:
– 产生了大量的Redo Log. 可以通过Report Summary中的Redo size (bytes)计算出Redo Log大小。再比较Redo Log 文件的大小,看切换次数是否正常。假设Redo Log文件设置的大小是1G, 而根据Report Summary计算产生的Redo Log大小是 2G, 那么Redo Log没有被写满就切换了。
– 假设根据Report Summary计算出来的的Redo Log很大,有52G,那就需要查看Segments by DB Blocks Changes、Segments by Physical Writes、Segments by Direct Physical Writes,找到占比大的对象。
– 执行日志切换命令。例如rman增量备份的调用了日志切换。