Oracle 教程 Architectural
1.体系结构
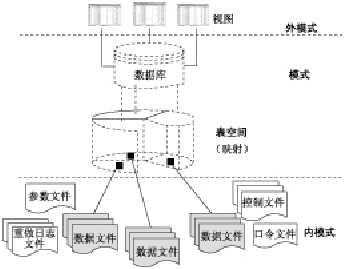
1.1.结构图
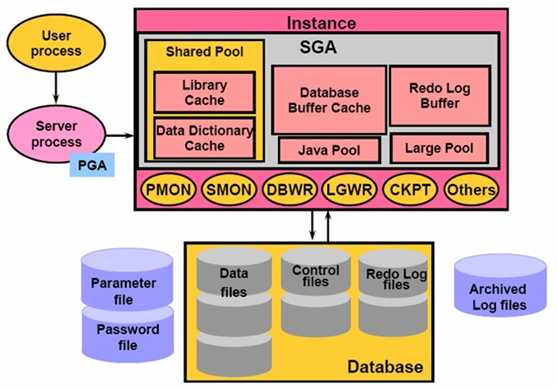
1.2.Database and Instance
数据库(database):物理操作系统文件或磁盘( disk)的集合。使用自动存储管理(Automatic Storage Management,ASM)或RAW 分区时, 数据库可能不作为操作系统中单独的文件,但定义仍然不变。
实例(instance):一组Oracle 后台进程/线程以及一个共享内存区,这些内存由同一个计算机上运行的线程/进程所共享。这里可以维护易失的、非持久性内容(有些可以刷新输出到磁盘)。就算没有磁盘存储,数据库实例也能存在。
这两个词有时可互换使用,不过二者的概念完全不同。实例和数据库之间的关系是:数据库可以由多个实例装载和打开,而实例可以在任何时间点装载和打开一个数据库。实际上,准确地讲,实例在其整个生存期中最多能装载和打开一个数据库!
一般的,一个数据库对应一个实例,但在集群RAC情况下,共享数据库文件时,一个数据库是可以被多个实例同时使用的。
同一时间,一个实例只能打开一个数据库,也就是一个实例只能操作或管理一个数据库;通常,同一时间,一个数据库只能被一个实例打开,但RAC情况除外。
安装oracle时,通常会安装一个实例——数据库对(当然可以装多对),而且他们的名字相同(也就是实例和数据库名字相同),他们的名字当然可以不同,不管相不相同,他们的联系是通过xxx/pfile/init.ora初始化文件联系的。因为xxx就是实例的名字,而xxx.ora中的db_name,则记录相应数据库的名字。
什么是instance,什么是database?
这个问题是困扰oracle新丁的一个常见问题。举个通俗易懂的例子,虽然不是很恰当,但是对于初学者理解instance和database很有帮助。
C:\下放了一个文本文件:example.txt,这是个实际存在的物理文件,现在打开进程管理器,进程管理器中看不到什么和这儿文件有关系的进程。但是当双击这个文本文件以后,进程管理器中就会出现notepad.exe。可以通过记事本对example.txt进行操作,比如说添加一些文字进去,或者删除一些文字,然后保存,或者不保存。
在这个例子里,instance就是在进程管理器中能看到的notepad.exe,而数据库就是那个C:\example.txt。
instance是一组进程,还有一块共享的内存区域,database是一组数据文件。而操作系统层级上,notepad.exe就是一个进程,还有给它分配的内存,都能在进程管理器里看到,而C:\example.txt就是实际存在的物理文件。
1.3.Connection and Session
连接 (connection)与会话 (session)这两个概念均与用户进程 (user process)紧密相关。
连接 :用户进程和 Oracle 实例间的通信通道(communication pathway)。这个通信通道是通过进程间的通信机制(interprocess communication mechanisms)(在同一个计算机上运行用户进程和 Oracle 进程)或网络软件(network software)(当数据库应用程序与 Oracle 服务器运行在不同的计算机上时,就需要通过网络来通信)建立的。
会话 :用户通过用户进程与 Oracle 实例建立的连接。此处连接与上文中的连接含义不同 ,主要指用户和数据库间的联系。例如,当用户启动 SQL*Plus 时必须提供有效的用户名和密码,之后 Oracle 为此用户建立一个会话。从用户开始连接到用户断开连接(或退出数据库应用程序)期间,会话一直持续。
Oracle 数据库中的同一个用户可以同时创建多个会话。例如,用户名/密码为的SCOTT/TIGER 用户可以多次连接到同一个 Oracle 实例。
当系统没有运行在共享服务模式下时,Oracle 为每个用户会话创建一个服务进程(server process)。而当系统运行在共享服务模式下时,多个用户会话可以共享同一个服务进程。
例如:
有A/B两个城市,需要从A运送白菜 到B城
先建一条公路
然后运送白菜过去,包括准备白菜和运送白菜以及返回等一系列的动作。
一条公路,可以运送0-n次的白菜
当然从A到B的公路也可能不只一条 。
某一次运送白菜,可以在真正上路时才开通某一条道路
一次运送不会影响别的运送的状态
对应数据库
A代表客户端进程
B代表服务器端进程
公路代表连接 ,
运送一次白菜代表一个会话
一个连接可以进行多次的会话
一个会话可以不依赖于某个连接,甚至没有连接(当我准备好了,真正开始运送时再建立连接)
一个会话不会影响别的会话
连接并不是会话的同义词。一个连接可能有零个、一个或多个建立在其上的会话。每个会话是分开且独立的,即使他们共享一个同样的物理连接到数据库。会话中的某个提交并不影响在该连接上的任何其他会话。事实上,使用该连接的每个会话可以使用不同用户身份。在Oracle中,一个连接是一个在客户端进程与数据库实例之间的物理线路——网络连接。该连接可能是一个专用服务器进程或一个调度进程。一个连接可以有零个或更多的会话,即一个连接的存在并不一定伴随着对应的会话存在。另外,一个会话不一定有连接。一个物理连接可以被客户端删除,只保留一个空闲会话。当客户端要在该会话中完成一些操作时,就需要重新建立物理连接。
•连接:一个连接是一个从客户端到一个数据库实例的物理通道。一个连接或者通过网络或者通过IPC机制建立连接。最典型的连接是建立在客户端进程和专用服务器或共享服务器之间。然而,使用Oracle的连接管理器(CMAN)时,一个连接可以是在客户端与CMAN之间或CMAN与数据库之间。
•会话:一个会话是存在于实例中的逻辑实体。它是一个表示唯一会话的内存数据结构的集合,用于执行SQL、提交事务并运行服务器中存储过程等。
实际上,一个连接有多个会话是非常普遍的。使用SQL*Plus可以说明连接和会话间的区别。使用autotrace命令时可产生两个会话。通过一个使用单个进程的连接也可以建立两个会话。
SQL>select username,sid,serial#,server,paddr,status
from vsession
where username=USER
/
USERNAME SID SERIAL# SERVER PADDR STATUS
----------- --- ------ ------ ------------ -----
OPSTKYTE 153 3196 DEDICATED AE4CF614 ACTIVE
2.实例(Instance)
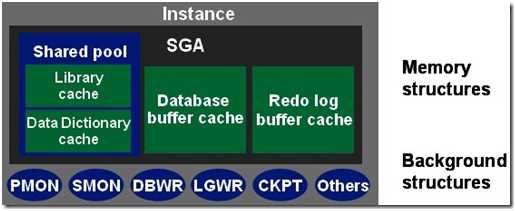
数据库实例(也称为服务器Server)就是用来访问一个数据库文件集的一个存储结构及后台进程的集合。
实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数INSTANCE_NAME来标识, 它们的值是相同的。 数据库启动时,系统首先在服务器内存中分配系统全局区(SGA),构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了Oracle的 进程结构,内存区域和后台进程合称为一个Instance。
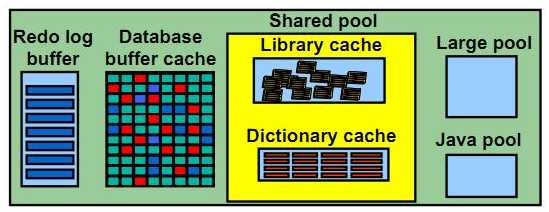
2.1.System Global Area (SGA)
SGA是一组共享的内存结构,包含一个数据库实例的数据和控制信息。如果多个用户连接到同一个数据库实例,在实例的SGA中,数据可以被多个用户共享。 当数据库实例启动时,SGA的被自动分配;当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
1)Database buffer cache:缓存了从磁盘上检索的数据块。
2)Redo log buffer:缓存了写到磁盘之前的重做信息。
3)Shared pool:缓存了各用户间可共享的各种结构。
4)Large pool:一个可选的区域,用来缓存大的I/O请求,以支持并行查询、共享服务器模式以及某些备份操作。
5)Java pool:保存java虚拟机中特定会话的数据与java代码。
6)Streams pool:由Oracle streams使用。
7)Keep buffer cache:保存buffer cache中存储的数据,使其尽时间可能长。
8)Recycle buffer cache:保存buffer cache中即将过期的数据。
9)nK block size buffer:为与数据库默认数据块大小不同的数据块提供缓存。用来支持表空间传输。
database buffer cache, shared pool, large pool, streams pool与Java pool根据当前数据库状态,自动调整;
keep buffer cache,recycle buffer cache,nK block size buffer可以在不关闭实例情况下,动态修改。
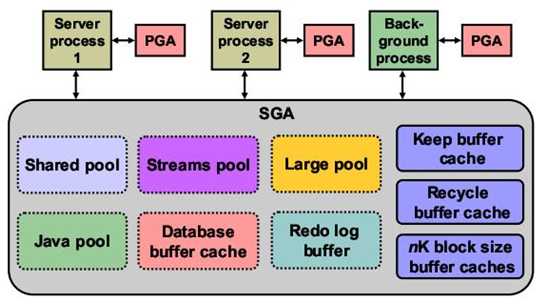
2.1.1.Share Pool
Shared Pool是SGA中的一部分,它可以被所有的进程访问,Shared Pool包含2部分:Library Cache和Data Dictionary Cache。
Library Cache包含了共享SQL区(Shared SQL Areas),私有SQL区(Private SQL Areas)如果配置了共享服务器,PL/SQL存储过程以及包,还有一些控制信息,比如说Locks以及Library Cache Handles。
Data Dictionary Cache包含了表,视图的依赖信息,比如表结构,它的用户,Oracle在解析SQL的时候就会频繁的访问Data Dictionary Cache。
SHARE_POOL_SIZE
1)Share Pool可通过SHARE_POOL_SIZE参数指定:
SQL> alter system set shared_pool_size=20M scope=both;
2)Share Pool保存的信息被多个会话共享,类型包括:
a.Library Cache
Library Cache又包含共享SQL区与PL/SQL区:
a).共享SQL区保存了分析与编译过的SQL语句。
b).PL/SQL区保存了分析与编译过的PL/SQL块(过程和函数、包、触发器与匿名PL/SQL块)。
b.Data Dictionary Cache
保存了数据字典对象的定义。
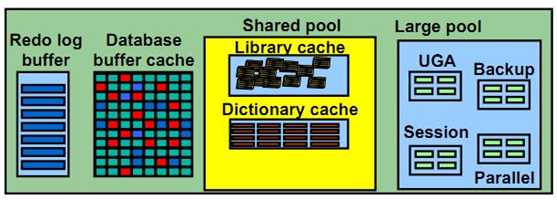
c.UGA(User Global Area)
UGA内包含了共享服务器模式下的会话信息。
共享服务器模式时,如果large pool没有配置,则UGA保存在Share Pool中。
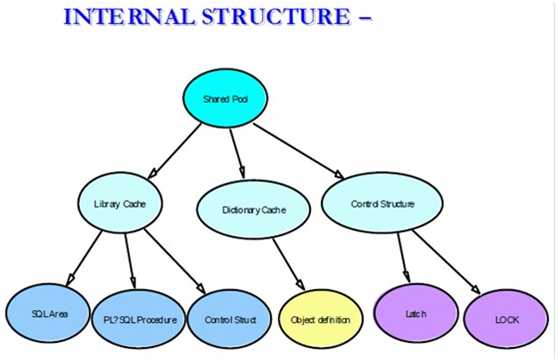
2.1.1.1.Library Cache
Library Cache几乎是Oracle内存结构中最复杂的一部分, 主要存放
– 共享SQL区(Shared SQL Areas)
– 私有SQL区(Private SQL Areas)如果配置了共享服务器
– PL/SQL对象(function, package/procedure,cursor, trigger)
– Library Cache Handles
Library Cache需要解决三个问题:
1. 快速定位的问题:Library Cache中对象众多,Oracle如何管理这些对象,以便服务进程可以迅速找到他们需要的信息。比如某个服务进程需要迅速定位某个SQL是否存在于Library Cache中。
2. 关系依赖的问题:Library Cache中的对象存在复杂的依赖关系,当某个Object失效时,可以迅速将依赖其的对象也置为失效状态。比如某个表发生了结构变化,依赖其的SQL语句需要重新解析。
3. 并发控制的问题:Library Cache中必须有一个并发控制的机构,比如锁机制,来管理大量共享对象的并发访问和修改的问题,比如某个SQL在重新编译的同时,其所依赖的对象不能被修改。
SQL共享区包括执行计划及运行数据库的SQL语句的语法分析树。在第二次运行(由任何用户)相同的SQL语句时,可以利用SQL共享区中可用的语法分析信息来加快执行速度。
SQL共享区通过LRU算法来管理。当SQL共享区填满时,将从库缓存区中删掉最近最少使用的执行路径和语法分析树,以便为新的条目腾出空间。如果SQL共享区太小,语句将被连续不断地再装入到库缓存区,从而影响操作性能。
Shared and Private SQL Area
A shared SQL area contains the parse tree and execution plan for a single SQL statement, or for similar SQL statements. Oracle saves memory by using one shared SQL area for multiple similar DML statements, particularly when many users execute the same application.
A shared SQL area is always in the shared pool. Oracle allocates memory from the shared pool when a SQL statement is parsed; the size of this memory depends on the complexity of the statement. If a SQL statement requires a new shared SQL area and the entire shared pool has already been allocated, Oracle can deallocate items from the pool using a modified least Recently used algorithm until there is enough free space for the new statement’s shared SQL area.
A private SQL area contains data such as bind information and runtime buffers. Each session that issues a SQL statement has a private SQL area. Each user that submits an identical SQL statement has his or her own private SQL area that uses a single shared SQL area; many private SQL areas can be associated with the same shared SQL area.
A private SQL area has a persistent area and a runtime area:
(1)The persistent area contains bind information that persists across executions, code for datatype conversion (in case the defined datatype is not the same as the datatype of the selected column), and other state information (like recursive or remote
cursor numbers or the state of a parallel query). The size of the persistent area depends on the number of binds and columns specified in the statement. For example, the persistent area is larger if many columns are specified in a query.
(2)The runtime area contains information used while the SQL statement is being executed. The size of the runtime area depends on the type and complexity of the SQL statement being executed and on the sizes of the rows that are processed by the statement. In general, the runtime area is somewhat smaller for INSERT, UPDATE and DELETE statements than it is for SELECT statements, particularly when the SELECT statement requires a sort.
Oracle creates the runtime area as the first step of an execute request. For INSERT, UPDATE, and DELETE statements, Oracle frees the runtime area after the statement has been executed. For queries, Oracle frees the runtime area only after all rows are fetched or the query is cancelled.
The location of a private SQL area depends on the type of connection established for a session. If a session is connected via a dedicated server, private SQL areas are located in the user’s PGA. However, if a session is connected via the multithreaded server, the persistent areas and, for SELECT statements, the runtime areas, are kept in the SGA (x$ksmms) table provide the runtime information regarding SQL area in Library Cache which is suppose to be allocated to a particular Oracle Instance。
E.g.
SELECT *
FROM X$KSMSS
WHERE KSMSSNAM = 'sql_area' AND KSMSSLEN <> 0;
PL/SQL Procedure Part
Oracle processes PL/SQL program units (procedures, functions, packages, anonymous blocks, and database triggers) much the same way it processes individual SQL statements.
Oracle allocates a shared area to hold the parsed, compiled form of a program unit. Oracle allocates a private area to hold values specific to the session that executes the program unit, including local, global, and package variables (also known as package instantiation) and buffers for executing SQL. If more than one user executes the same program unit, then a single, shared area is used by all users, while each user maintains a separate copy of his or her private SQL area, holding values specific to his or her session.
Individual SQL statements contained within a PL/SQL program unit are processed as described in the previous sections. Despite their origins within a PL/SQL program unit, these SQL statements use a shared area to hold their parsed representations and a private area for each session that executes the statement.
(x\$ksmms) table provide the runtime information regarding PL/SQL area in Library Cache which is suppose to be allocated to a particular Oracle Instance 。
E.g.
SELECT *
FROM X$KSMSS
WHERE KSMSSNAM LIKE 'PL/SQL%' AND KSMSSLEN <> 0;

PL/SQL MPCODE stands for machine dependent pseudo code.
PL/SQL DIANA stands for the PL/SQL code size in the shared pool at runtime.
2.1.1.2.KGH Heap Manager
Shared Pool和PGA都是由一个Oracle的内存管理器来管理,即KGL。Heap Manager不是一个进程, 而是一串代码。 Heap Manager主要目的就是满足Server 进程请求memory 的时候分配内存或者释放内存。Heap Manager在管理PGA的时候,需要和操作系统来打交道来分配或者回收内存。但是呢,在shared pool中,内存是预先分配的,Heap Manager不需要分配或者回收内存。 Heap Manager管理所有的空闲内存, 当某个进程需要分配Shared Pool的内存的时候,Heap Manager就满足该请求,Heap Manager也和其他ORACLE模块一起工作来回收Shared Pool的空闲内存。
2.1.1.3.Library Cache Manager
Library cache Manager 可以看做是Heap Manager的客户端,因为Library Cache Manager是根据Heap Manager来分配内存,存放Library Cache Objects。 Library Cache Manager控制所有的Library Cache Object,包括package/procedure, cursor, trigger等等。
2.1.1.4.Hash Bucket
Library cache是由一个hash table组成,hash table又由hash bucket组成的数组构成,每个hash bucket又是由一些相互指向的library cache handle所组成,library cache object handle就指向具体的library cache object以及一些引用列表。
Oracle利用hash table结构来解决library cache中快速定位的问题,hash table就是很多hash bucket组成的数组。
The hash table is an array of hash buckets. The initial number of the hash buckets is 251; however, the number of buckets will increase when the number of objects in the table exceeds the next number.
The next numbers are the next higher prime value. They are 251, 509, 1021,2039, 4093, 8191, 16381, 32749, 65521, 131071 and 4292967293 where the “n+1″th size is approximately twice the “n”th size. The resulting expansion of the hash table will involve allocating a new hash table at the next prime size, rehashing the library cache objects from the old table to the new table, and freeing the space allocated from the old hash table. Throughout this procedure, access to the hash table is blocked (by freezing access to the child latches) as one user allocates new buckets to double the size of the hash table and then uses the least significant bits of the hash value to determine which new bucket a handle belongs to. Contrary to common belief, this is a rare and inexpensive operation that may cause a short (approximately 3-5 second) hiccup in the system.
The hash table never shrinks. The library cache manager will apply a modulo hash function to a given object’s namespace, object name, owner, and database link to determine the hash bucket where the object should be found.
It then walks down the corresponding linked list to see if the object is there. If the object does not exist, the library cache manager will create an empty object with the given name, insert it in the hash table, and request the client load it by calling the client’s environment dependent load function.
Basically, the client would read from disk, call the heap manager to allocate memory, and load the object.
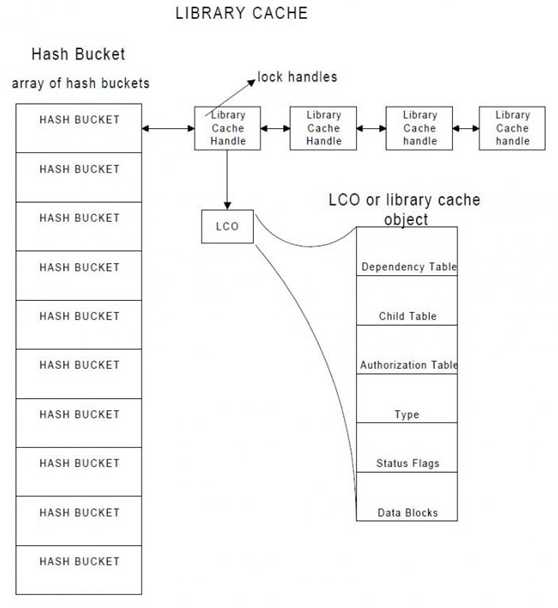
Library cache handle是对象的一个指针。对Library Cache中所有对象的访问是通过Library Cache Handle来实现的,也就是说想要访问Library Cache Object,必须先找到Library Cache Handle。
Library Cache Handle指向Library Cache Object, 它包含了Library Object的名字,命名空间,时间戳,引用列表,Lock对象以及Pin对象的列表信息等等。其中的namespace属性表示其指向的对象的类型:比如CRSR(Cursor),TABL(Table),INDX(Index) ,PROD(Procedure),TRIG(Trigger)等等。
Library Cache Handle也被Library Cache用来记录哪个用户在这个Handle上有Lock,或者是哪个用户正在等待获得这个Lock。所以Library Cache lock是发生在Handle上的。
当一个进程请求Library Cache Object, Library Cache Manager就会应用一个Hash 算法,从而得到一个Hash 值,根据相应的Hash值到相应的Hash Bucket中去寻找。如果Library Cache Object在内存中,那么这个Library Cache Handle就会被找到。有时候,当Shared Pool不够大, Library Cache Handle会保留在内存中,然而Library Cache Heap由于内存不足被age out,这个时候我们请求的Object Heap就会被重载。最坏的情况下,Library Cache Handle在内存中没有找到,这个时候就必须分配一个新的Library Cache Handle,同时Object Heap也会被加载到内存中。
2.1.1.5.Library Cache Handle
A library cache handles points to a library cache object. It contains the name of the library object, the namespace, a timestamp, a reference list, a list of locks locking the object and a list of pins pinning the object. Each object is uniquely identified by the name within its namespace.
对Library cache中所有对象的访问是通过利用library cache handle来实现的,也就是说我们想要访问library cache object,我们必须先找到library cache handle。Library cache handle指向library cache object,它包含了library object的名字,命名空间,时间戳,引用列表,lock对象以及pin对象的列表信息等等。
Library cache handle也被library cache用来记录哪个用户在这个这个handle上有lock,或者是哪个用户正在等待获得这个lock。那么这里我们也知道了library cache lock是发生在handle上的。
当一个进程请求library cache object, library cache manager就会应用一个hash 算法,从而得到一个hash 值,根据相应的hash值到相应的hash bucket中去寻找。
这里的hash算法原理与buffer cache中快速定位block的原理是一样的。如果library cache object在内存中,那么这个library cache handle就会被找到。有时候,当shared pool不够大,library cache handle会保留在内存中,然而library cache heap由于内存不足被age out,这个时候我们请求的object heap就会被重载。最坏的情况下,library cache handle在内存中没有找到,这个时候就必须分配一个新的library cache handle,同时object heap也会被加载到内存中。
查看namespace:
SQL> select namespace from v$librarycache;
NAMESPACE
---------------
SQL AREA
TABLE/PROCEDURE
BODY
TRIGGER
INDEX
CLUSTER
OBJECT
PIPE
JAVA SOURCE
JAVA RESOURCE
JAVA DATA
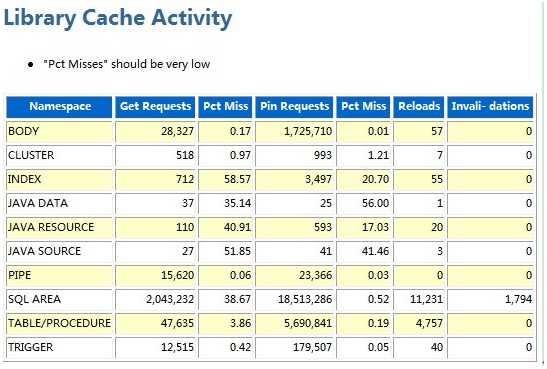
在AWR 里有关Library Cache Activity 的统计信息:
2.1.1.6.Library Cache Object
Library Cache Object是由一些独立的heap所组成,其实 Library cache handle是指向第一个heap,即 heap 0。Heap 0记录了指向其他heap的指针信息。
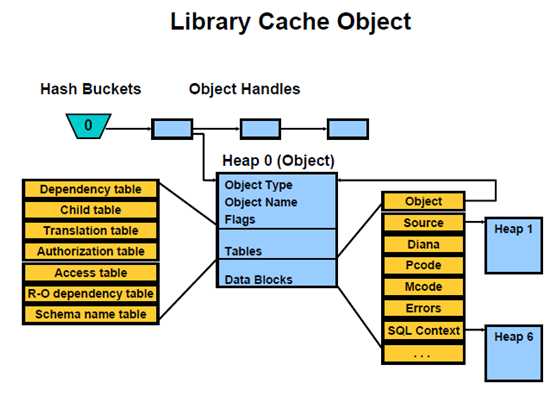
LCO(Library cache object)包含了以下几个部分的内容:
– dependency table:
– 指向本对象所依赖的对象,比如:select * from emp这个cursor的对象,依赖emp这个表,这里指向了emp这个表的handle。
– child table:
指向本对象的子对象,比如某个游标的子游标。子游标是指SQL文本相同,但是SQL的实际含义不同的情况,比如执行的用户不同,执行计划不同,执行的环境不同等等,我们一般称之为SQL的不同版本。一个SQL至少包含一个父游标和一个子游标。
– authorization table:
对象的授权信息。
– type
Library cache object的type,包括:shared cursor,index,table,cluster,view,synonym,sequence,procedure,function,package,table body,package body,trigger等等。
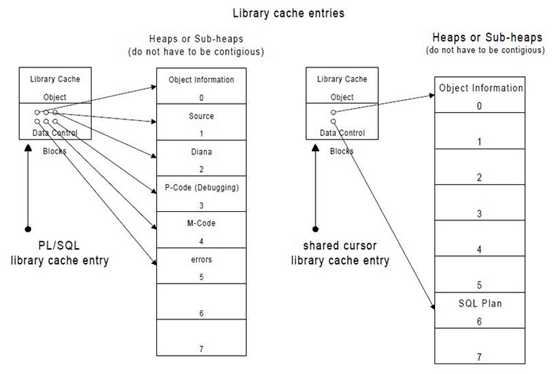
– data blocks
data block是一个指针,指向了data heap,即存放真实数据的地方,主要包括:diana tree, p-code, source code, shared cursor context area等等,如下图:

2.1.1.7.Library Cache Lock/Pin
Library Cache Lock/Pin是用来控制对Library Cache Object的并发访问的。 Lock管理并发,Pin管理一致性,Lock是针对于Library Cache Handle,而Pin是针对于Heap。
当访问某个Library Cache Object时, 首先要获得指向Object的Library Cache Handle的Lock,获得Lock之后,需要Pin住指向这个Object的Heap。
当对包,存储过程,函数,视图进行编译时,Oracle就会在这些对象的Handle上面首先获得一个Library Cache Lock,然后在这些对象的Heap上获得Pin,这样就能保证在编译的时候其它进程不会来更改这些对象的定义,或者删除对象。
当一个Session对SQL语句进行硬解析时,这个Session必须获得Library Cache Lock,这样其他Session就不能够访问或者更改这个SQL所引用的对象。如果这个等待事件花了很长时间,通常表明共享池太小(由于共享池太小,需要搜索free的chunk,或者将某些可以被移出的Object Page Out,这样要花很长时间),当然了,也有可能另外的Session正在对Object进行修改(比如Split 分区),而当前Session需要引用那个Table,在这种情况下必须等待另外的Session运行完毕。
Library Cache Lock有3中模式:
– Share(S): 读取一个Library Cache Object时获得
– Exclusive(X): 创建/修改一个Library Cache Object时获得
– Null(N): 用来确保对象依赖性
例如:
一个进程要编译某个视图,就需要获得一个共享锁;
Create/Drop/Alter某个对象,就需要获得Exclusive Lock;
Null锁非常特殊,在任何可以执行的对象(Cursor,Function)上面都有NULL锁,可以随时打破这个NULL锁, 如果这个NULL锁被打破了, 就表示这个对象被更改了,需要从新编译。NULL锁主要的目的就是标记某个对象是否有效。比如一个SQL语句在解析的时候获得了NULL 锁,如果这个SQL的对象一直在共享池中,那么这个NULL锁就会一直存在下去,当这个SQL语句所引用的表被修改之后,这个NULL锁就被打破了,因为修改这个SQL语句的时候会获得Exclusive 锁,由于NULL锁被打破了,下次执行这个SQL的时候就需要从新编译。
Library Cache Pin有2种模式:
– Share(S): 读取Object Heap
– Exclusive(X): 修改Object Heap
当某个session要读取Object Heap,就需要获取一个共享模式的Pin;
当某个session要修改Object Heap,就需要获取排它的Pin。 在获得Pin之前必须获得Lock。
2.1.1.8.RAC环境中的案例
SQL> select inst_id from gv$instance;
INST_ID
----------
2
1
在第一个节点中,session 4538被Library Cache Lock阻塞
SQL> select inst_id, sid, serial#, event , p1raw, machine, status from gv$session
where username='BX5685';
INST_ID SID SERIAL# EVENT P1RAW MACHINE STATUS
---------- ----- ----- --- ------- --------------- --------- ---- -------- --------
1 4538 39833 library cache lock C000000346FBA458 bdhp4462 ACTIVE
在Node1上面查询
SQL> select * from dba_kgllock where kgllkreq > 0;
KGLLKUSE KGLLKHDL KGLLKMOD KGLLKREQ KGLLKTYPE
---------------- ---------------- ---------- ---------- ------------
C0000004789EF9D0 C000000346FBA458 0 2 Lock
SQL> select kglnaown, kglnaobj from xkglob where kglhdadr = 'C000000346FBA458';
KGLNAOWN KGLNAOBJ
-------------------- --------------------
IDWSU1 PROD_ASSOC_DNORM
SQL> select kglhdadr, kglnaown, kglnaobj from xkglob
where kglnaobj = 'PROD_ASSOC_DNORM' and KGLNAOWN='IDWSU1';
KGLHDADR KGLNAOWN KGLNAOBJ
---------------- -------------------- --------------------
C000000346FBA458 IDWSU1 PROD_ASSOC_DNORM
在Node2上面查询
SQL> select kglhdadr, kglnaown, kglnaobj from xkglob
where kglnaobj = 'PROD_ASSOC_DNORM' and KGLNAOWN='IDWSU1';
KGLHDADR KGLNAOWN KGLNAOBJ
---------------------------- -------------------- ------------------------------
C000000443267070 IDWSU1 PROD_ASSOC_DNORM
C00000035C33E248 IDWSU1 PROD_ASSOC_DNORM
SQL> col event format a30
select sid, serial#, s.event, sql_text from dba_kgllock w, vsession s, v$sqlarea a
where w.kgllkuse = s.saddr and w.kgllkhdl='C000000443267070'
and s.sql_address = a.address
and s.sql_hash_value = a.hash_value;
SID SERIAL# EVENT SQL_TEXT
---------- ---------- ---------------------- --------
4774 36583 db file scattered read ALTER TABLE PROD_ASSOC_DNORM ENABLE CONSTRAINT PROD_ASSOC_DNORM_PK USING INDEX STORAGE ( INITIAL 4194304 NEXT 4194304 PCTINCREASE 0 ) TABLESPACE CDW_REFERENCE01M LOCAL
在Oracle10gR2中,Library Cache Pin被Library Cache Mutex 取代。
2.1.1.9.Library Cache Latch
获取Lock不是一个原子操作(原子操作就是在操作程中不会被打破的操作),Oracle引入了Library Cache Latch, 在获得Library Cache Lock之前, 需要先获得Library Cache Latch,获得Library Cache Lock之后就释放Library Cache Latch。
如果Library Cache Object不在内存中,那么这个Lock就不能被获取,这时需要获得一个Library Cache Load Lock Latch,然后再获取一个Library Cache Load Lock, 获得Load Lock之后,马上释放Library Cache Load Lock Latch。
在 Oracle10gR2 中的一个有关library cache latch, library cache lock, library cache pin 的统计情况:
SQL> select name, gets, misses, sleeps from v$latch where name like '%library%';
NAME GETS MISSES SLEEPS
------------------------------ ---------- ---------- ----------
library cache 1937415298 5513866 2346346
library cache lock 734620587 425030 3021
library cache pin 171326029 108613 868
library cache pin allocation 2930490 35 1
library cache lock allocation 5226147 349 2
library cache load lock 720252 1762 34
library cache hash chains 0 0 0
library cache latch受隐含参数_KGL_LATCH_COUNT的控制,默认值为大于等于系统中CPU个数的最小素数,但是Oracle对其有一个硬性限制,该参数不能大于67。
注意:查询_kgl_latch_count有时候显示为0,这是一个bug。
那么library cache object handle是由哪个子latch来保护的呢?
Oracle利用下面算法来确定:
latch# = mod(bucket#, #latches)(摘自DSI405)
也就是说用哪个子latch去保护某个handle是根据那个handle所在的bucket号,以及总共有多少个子latch来进行hash运算得到的,不必深究。
2.1.1.10.Latch Contention
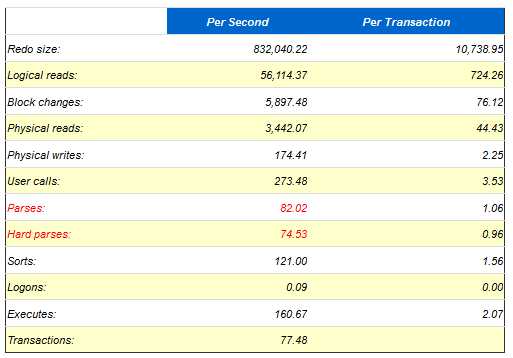
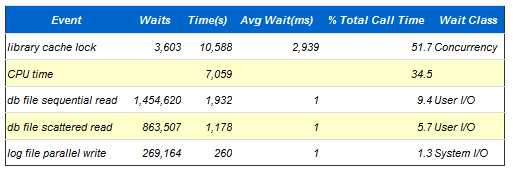
根据前面的讲解,存在大量硬解析的系统上面就必然引发library cache latch, library cache lock竞争,下面就是一个每秒高达74个硬解析所引发Library cache lock 成为Top wait event的一个案例。
Load Profile
Top 5 Timed Events
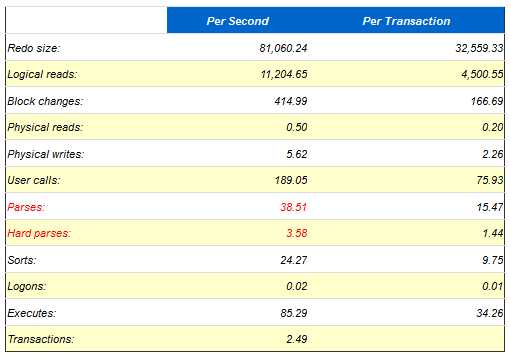
如果shared pool过小,也会引发library cache latch竞争,与此同时还会伴随shared pool latch竞争。下面就是一个由于shared pool过小,导致library cache latch成为top wait event的案例:
Load Profile
Top 5 Timed Events
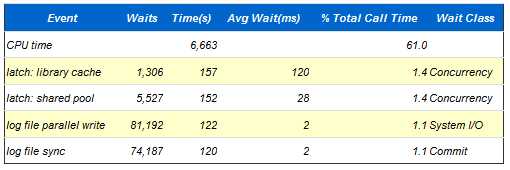
Shared Pool Advisory
- SP: Shared Pool Est LC: Estimated Library Cache Factor: Factor
- Note there is often a 1:Many correlation between a single logical object in the Library Cache, and the physical number of memory objects associated with it. Therefore comparing the number of Library Cache objects (e.g. in v$librarycache), with the number of Library Cache Memory Objects is invalid.
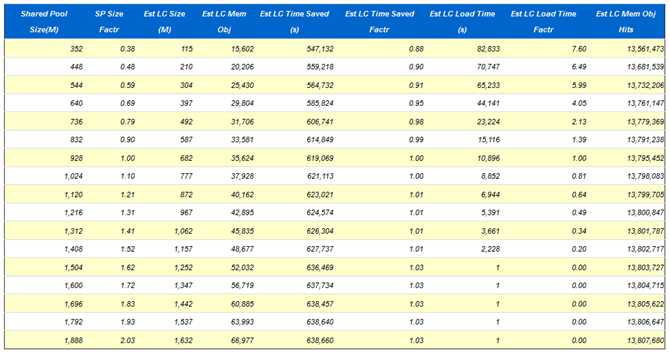
Library Cache Activity
“Pct Misses” should be very low
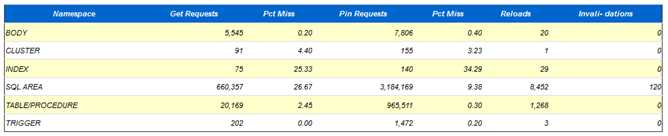
怎么判断shared pool是否过小呢?
AWR里面提供了多个指标,这里硬解析不是太高,每秒3个,说明硬解析不会导致该问题,shared pool advice已经说得很明白了,当前shared pool只有928m,Oracle建议把shared pool至少调整到1504m。同时查看 Library cache activity,注意观察pct miss,SQL AREA的pct miss居然达到26.67%,而且重载了8452次,那么可以肯定是由于shared pool太小,导致SQL被大量重载,从而引发library cache latch竞争。
Library cache latch竞争还有可能是具有高version_count的SQL导致的,某个session去执行一个具有很高version_count的SQL需要pin住child cursor,而由于child cursor过多,在未pin住child cursor之前不会释放library cache latch,这样当其他session想运行该SQL的时候就会发生library cache latch争用, 遇到这种情况需要检查cursor_sharing参数的设置,另外请查询是否遇到bug,或者由于系统中不同schema出现大量同名的表名,这样请更改设计。
在第二个案例中,由于shared pool设置过小还导致了shared pool latch处于top wait event 中的第二名。Shared pool latch是用来干嘛的呢?Shared pool latch用来保护共享池的结构,在分配,释放共享池空间的时候就会获得该latch,那么在这个案例中,由于共享池太小,在对一个新的SQL进行硬解析的时候需要老化某些对象,为新对象腾出空间,那么这个释放空间的过程就需要获得shared pool latch。当然了,在进行硬解析,也需要获得一个shared pool latch因为硬解析需要申请分配shared pool空间,而分配空间的时候就需要获得该latch。
2.1.1.11.Data Dictionary Cache
Table definition against which an application user suppose to do a query, it include table’s associated Index and Columns and privilege information regarding table as well as columns.
SELECT * FROM X$KSMSS
WHERE KSMSSNAM LIKE 'PL/SQL%' AND KSMSSLEN <> 0;
数据库对象的信息存储在数据字典表中,这些信息包括用户帐号数据、数据文件名、段名、盘区位置、表说明和权限,当数据库需要这些信息(如检查用户查询一个表的授权)时,将读取数据字典表并且将返回的数据存储在字典缓存区的SGA中。
数据字典缓存区通过最近最少使用(LRU)算法来管理。字典缓存区的大小由数据库内部管理。字典缓存区是SQL共享池的一部分,共享池的大小由数据库文件init.ora中的SHARED_POOL_SIZE参数来设置。
如果字典缓存区太小,数据库就不得不反复查询数据字典表以访问数据库所需的信息,这些查询称为循环调用(recursive call),这时的查询速度相对字典缓存区独立完成查询时要低。
2.1.1.12.Control Structure
This contain the information regarding Internal Latch and Locks (Data Structure), it also contain buffer header, the process session and transaction arrays.
The size of these arrays depends on the setting of Initialisation parameter of Init.ora file and can’t be changed without shutting down the database.
Shared Pool Chunks
Have close looks of Shared Pool, For that we should have a close look at x\$ksmsp each row in this table shows a chunk of shared pool :
SQL>select * from X$ksmsp
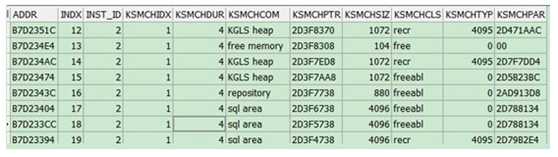
When each shared pool chunk is allocated the code is passed to a function that does the work of allocation and this address is visible to KSMCHCOM column,which describe the purpose of allocation. This chunk is supposed to be larger then the size of the object as it also contains the header information.
The column KSMCHCLS represent the class, there are basically four type of classes:
– Freeabl : can be freed only contain the objects needed for the session call.
– Free : free and not contained by valid object.
– Recr : contain by temporary objects.
– Perm : contained by the permanent object.
SELECT KSMCHCLS CLASS,
COUNT (KSMCHCLS) NUM,
SUM (KSMCHSIZ) SIZ,
TO_CHAR ( ( (SUM (KSMCHSIZ) / COUNT (KSMCHCLS) / 1024)), '999,999.00')
|| 'k'
"AVG SIZE"
FROM X$KSMSP
GROUP BY KSMCHCLS;
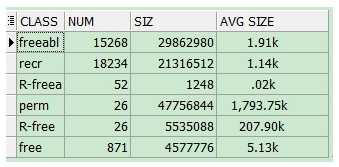
在生产库上查询X$KSMSP时,要看下系统的繁忙或者说是负载高低,因为可能会导致db hang 住。
So the overall summary :
/* Formatted on 2011/6/21 16:06:38 (QP5 v5.163.1008.3004) */
SELECT KSMCHCOM name,
COUNT (KSMCHCOM),
SUM (DECODE (KSMCHCLS, 'recr', KSMCHSIZ)) RECREATABLE,
SUM (DECODE (KSMCHCLS, 'freeabl', KSMCHSIZ)) FREEABLE
FROM x$ksmsp
GROUP BY KSMCHCOM;
LRU List
When a process starts it allocate some memory and when it’ fails to allocated required memory, Then it try to remove chunk containing recreatable object from shared pool to get the desired size of chunk, and removing these object from memory is based on LRU(Least Recent Used) means those objects that are frequently pinned kept in the memory and those are unpinned we generally remove those objects from the memory. Object those required again known as transient and other known as recurrent.
ORA-04331 ‘unable to allocate x bytes of shared pool’ when all the free memory fully exhausted (Later we will discuss the shared pool fragmentation).
There is one list maintained which known as Reserved List, it generally 5% of the total size of Shared Pool and reserved size is defined by SHARED_POOL_RESERVED_SIZE parameter in Init.ora parameter file.
With the help of v$shared_pool_reserved we can see reserved size, here REQUEST_MISS shows the number of times the request miss for a large chunk.
2.1.2.Share Pool Size Calculation
The shared pool size is highly application dependent. To determine the shared pool size for a production system it is generally necessary to develop the application run it on a test environment (should be enough like production system) get some test result and on the basis of that calculate the shared pool size. There are some few step which we should consider while calculating the shared pool.
2.1.2.1.Stored Objects
The amount of shared pool that needs to be allocated for objects that are stored in the database like packages and views is easy to measure. You can just measure their size directly with the following statement:
SELECT SUM (sharable_mem) FROM V$DB_OBJECT_CACHE;
2.1.2.2.SQL
The amount of memory needed to store sql statements in the shared pool is more difficult to measure because of the needs of dynamic sql. If an application has no dynamic sql then the amount of memory can simply be measured after the application has run for a while by just selecting it out of the shared pool as follows:
SELECT SUM (sharable_mem) FROM v$sqlarea;
If the application has a moderate or large amount of dynamic sql like most applications do, then a certain amount of memory will be needed for the shared sql plus more for thedynamic sql. Sufficient memory should be allocated so that the dynamic sql does not age the shared sql out of the shared pool.
Approximated memory could be calculated by the following:
SELECT SUM (sharable_mem)
FROM v$sqlarea
WHERE executions > 5;
The remaining memory in v$sqlarea is for dynamic sql.
2.1.2.3.Per-user Per-cursor Memory
You will need to allow around 250 bytes of memory in the shared pool per concurrent user for each open cursor that the user has whether the cursor is shared or not. During the peak usage time of the production system, you can measure this as follows:
SELECT SUM (250 * users_opening) FROM v$sqlarea;
In a test system you can measure it by selecting the number of open cursors for a test user and multiplying by the total number of users:
SELECT 250 * VALUE bytes_per_user
FROM vsesstat s, vstatname n
WHERE s.statistic# = n.statistic#
AND n.name = 'opened cursors current'
AND s.sid = 130;
-- replace 130 with session id of user being measured
The per-user per-cursor memory is one of the classes of memory that shows up as ‘library cache’ in v\$sgastat.
2.1.2.4.MTS
If you are using multi-threaded server, then you will need to allow enough memory for all the shared server users to put their session memory in the shared pool.
This can be measured for one user with the following query:
SELECT VALUE sess_mem
FROM vsesstat s, vstatname n
WHERE s.statistic# = n.statistic#
AND n.name = 'session uga memory'
AND s.sid = 23;
-- replace 23 with session id of user being measured
A more conservative value to use is the maximum session memory that was ever allocated by the user:
SELECT VALUE sess_max_mem
FROM vsesstat s, vstatname n
WHERE s.statistic# = n.statistic#
AND n.name = 'session uga memory max'
AND s.sid = 23;
-- replace 23 with session id of user being measured
To select this value for all the currently logged on users the following query can be used:
SELECT SUM (VALUE) all_sess_mem
FROM vsesstat s, vstatname n
WHERE s.statistic# = n.statistic# AND n.name = 'session uga memory max';
2.1.2.5.Overhead
You will need to add a minimum of 30% overhead to the values calculated above to allow for unexpected and unmeasured usage of the shared pool.
Estimating Procedure (From Metalink)
SET SERVEROUTPUT ON;
DECLARE
object_mem NUMBER;
shared_sql NUMBER;
cursor_mem NUMBER;
mts_mem NUMBER;
used_pool_size NUMBER;
free_mem NUMBER;
pool_size VARCHAR2 (100);
BEGIN
-- Stored objects (packages, views)
SELECT SUM (sharable_mem) INTO object_mem FROM vdb_object_cache;
-- Shared SQL -- need to have additional memory if dynamic SQL used
SELECT SUM (sharable_mem) INTO shared_sql FROM vsqlarea;
-- User Cursor Usage -- run this during peak usage
SELECT SUM (250 * users_opening) INTO cursor_mem FROM vsqlarea;
-- For a test system -- get usage for one user, multiply by # users
-- select (250 * value) bytes_per_user
-- from vsesstat s, vstatname n
-- where s.statistic# = n.statistic#
-- and n.name = 'opened cursors current'
-- and s.sid = 25; -- where 25 is the sid of the process
-- MTS memory needed to hold session information for shared server users
-- This query computes a total for all currently logged on users (run
-- during peak period). Alternatively calculate for a single user and
-- multiply by # users.
SELECT SUM (VALUE)
INTO mts_mem
FROM vsesstat s, vstatname n
WHERE s.statistic# = n.statistic# AND n.name = 'session uga memory max';
-- Free (unused) memory in the SGA: gives an indication of how much memory
-- is being wasted out of the total allocated.
SELECT bytes
INTO free_mem
FROM vsgastat
WHERE name = 'free memory';
-- For non-MTS add up object, shared sql, cursors and 30% overhead.
used_pool_size := ROUND (1.3 * (object_mem + shared_sql + cursor_mem));
-- For MTS add mts contribution also.
-- used_pool_size := round(1.3*(object_mem+shared_sql+cursor_mem+mts_mem));
SELECT VALUE
INTO pool_size
FROM v$parameter
WHERE name = 'shared_pool_size';
-- Display results
DBMS_OUTPUT.put_line ('Obj mem: ' || TO_CHAR (object_mem) || ' bytes');
DBMS_OUTPUT.put_line ('Shared sql:' || TO_CHAR (shared_sql) || ' bytes');
DBMS_OUTPUT.put_line ('Cursors: ' || TO_CHAR (cursor_mem) || ' bytes');
DBMS_OUTPUT.put_line ('MTS session:' || TO_CHAR (mts_mem) || ' bytes');
DBMS_OUTPUT.put_line (
'Free memory:'
|| TO_CHAR (free_mem)
|| ' bytes '
|| '('
|| TO_CHAR (ROUND (free_mem / 1024 / 1024, 2))
|| 'M)');
DBMS_OUTPUT.put_line (
'Shared poolutilization (total): '
|| TO_CHAR (used_pool_size)
|| ' bytes '
|| '('
|| TO_CHAR (ROUND (used_pool_size / 1024 / 1024, 2))
|| 'M)');
--Technical Reports Compendium, Volume I, 1996
--Shared Pool Internals
DBMS_OUTPUT.put_line (
'Shared pool allocation (actual): '
|| pool_size
|| ' bytes'
|| '('
|| TO_CHAR (ROUND (pool_size / 1024 / 1024, 2))
|| 'M)');
DBMS_OUTPUT.put_line (
'Percentage Utilized:'
|| TO_CHAR (ROUND (used_pool_size / pool_size * 100))
|| '%');
END;
2.1.3.Share Pool Monitor and Tuning
2.1.3.1.SQL
2.1.3.1.1.Literal SQL
A literal SQL statement is considered as one which use literals in the predicates rather then bind variable, where the value of the literal is likely to differ between various execution of the statement.
E.g 1 :
SELECT * FROM temp_x WHERE col_1='x';
is used by the application instead of
SELECT * FROM temp_x WHERE ename=:x;
Eg 2:
SELECT sysdate FROM dual;
does not use bind variables but would not be considered as a literal SQL statement for this article as it can be shared.
Eg 3:
SELECT version FROM app_version WHERE version>2.0;
If this same statement was used for checking the ‘version’ throughout the application then the literal value ‘2.0’ is always the same so this statement can be considered sharable.
2.1.3.1.2.Hard Parse
If a new SQL statement is issued which does not exist in the shared pool then this has to be parsed fully. Eg: Oracle has to allocate memory for the statement from the shared pool, check the statement syntactically and semantically etc…
This is referred to as a hard parse, is very expensive in both terms of CPU used, and in the number of latch get s performed.
2.1.3.1.3.Soft Parse
If session issues a SQL statement, which is already in the shared pool AND it, can use an existing version of that statement then this is known as a ‘soft parse’. As far as the application is concerned it has asked to parse the statement.
2.1.3.1.4.Identical Statements
If two SQL statements mean the same thing but are not identical character for character then from an Oracle viewpoint they are different statements. Consider the following issued by
SCOTT in a single session:
SELECT ENAME from TEMP_X;
SELECT ename from temp_x;
Although both of these statements are really the same they are not identical as an upper case ‘T’ is not the same as a lower case ‘t’.
2.1.3.1.5.Sharable SQL
If two sessions issue identical SQL statements it does NOT mean that the statement is sharable. Consider the following:
User USER_X has a table called TEMP_X and issues:
SELECT column_x from TEMP_X;
User USER_Y has his own table called TEMP_X and also issues:
SELECT column_y from TEMP_X;
Although the text of the statements are identical the TEMP_X tables are different objects. Hence these are different versions of the same basic statement. There are many things that determine if two identical SQL strings are truly the same statement (and hence can be shared) including:
All object names must resolve to the same actual objects. The optimiser goal of the sessions issuing the statement should be the same The types and lengths of any bind variables should be “similar”. (We don’t discuss the details of this here but different types or lengths of bind variables can cause statements to be classed as different versions). The NLS (National Language Support) environment which applies to the statement must be the same
2.1.3.1.6.Versions of a statement
As described in ‘Sharable SQL’ if two statements are textually identical but cannot be shared then these are called ‘versions’ of the same statement.
If Oracle matches to a statement with many versions it has to check each version in turn to see if it is truly identical to the statement currently being parsed. Hence high version counts are best avoided by:
Standardising the maximum bind lengths specified by the client Avoid using identical SQL from lots of different schemas, which use private objects.
Eg:
SELECT xx FROM MYTABLE;
where eachuser has their own MYTABLE
Setting _SQLEXEC_PROGRESSION_COST to '0' in Oracle 8.1
2.1.3.1.7.Library Cache and Shared Pool latches
The shared pool latch is used to protect critical operations when allocating and freeing memory in the shared pool.
The library cache latches (and the library cache pin latch in Oracle 7.1) protect operations within the library cache itself. All of these latches are potential points of contention. The number of latch gets occurring is influenced directly by the amount activity in the shared pool, especially parse operations. Anything that can minimise the number of latch gets and indeed the amount of activity in the shared pool is helpful to both performance and scalability.
2.1.3.1.8.Literal SQL versus Shared SQL
To give a balanced picture this short section describes the benefits of both literal SQL and sharable SQL.
Literal SQL
The Cost Based Optimiser (CBO) works best when it has full statistics and when statements use literals in their predicates. Consider the following:
SELECT distinct cust_ref FROM orders WHERE total_cost < 10000.0;
Versus
SELECT distinct cust_ref FROM orders WHERE total_cost < :bindA;
For the first statement the CBO could use histogram statistics that have been gathered to decide if it would be fastest to do a full table scan of ORDERS or to use an index scan on TOTAL_COST (assuming there is one).
In the second statement CBO has no idea what percentage of rows fall below “:bindA” as it has no value for this bind variable to determine an execution plan . Eg: “:bindA” could be 0.0 or 99999999999999999.9
There could be orders of magnitude difference in the response time between the two execution paths so using the literal statement is preferable if you want CBO to work out the best execution plan for you. This is typical of Decision Support Systems where there may not be any ‘standard’ statements, which are issued repeatedly so the chance of sharing a statement is small. Also the amount of CPU spent on parsing is typically only a small percentage of that used to execute each statement so it is probably more important to give the optimiser as much information as possible than to minimise parse times.
Sharable SQL
If an application makes use of literal (unshared) SQL then this can severely limit scalability and thr oughput. The cost of parsing a new SQL statement is expensive both in terms of CPU requirements and the number of times the library cache and shared pool latches may need to be acquired and released.
Eg: Even parsing a simple SQL statement may need to acquire a library cache latch 20 or 30 times.
The best approach to take is that all SQL should be sharable unless it is adhoc or infrequently used SQL where it is important to give CBO as much information as possible in order for it to produce a good execution plan. Reducing the load on the Shared Pool
2.1.3.1.9.Parse Once / Execute Many
By far the best approach to use in OLTP type applications is to parse a statement only once and hold the cursor open, executing it as required. This results in only the initial parse for each statement (either soft or hard). Obviously there will be some statements which are rarely executed and so maintaining an open cursor for them is a wasteful overhead.
Note that a session only has < Parameter: OPEN_CURSORS> cursors available and holding cursors open is likely to increase the total number of concurrently open cursors.
In precompilers the HOLD_CURSOR parameter controls whether cursors are held open or not while in OCI developers have direct control over cursors.
2.1.3.1.10.Eliminating Liter al SQL
If you have an existing application it is unlikely that you could eliminate all literal SQL but you should be prepared to eliminate some if it is causing problems. By looking at the V$SQLAREA view it is possible to see which literal statements are good candidates for converting to use bind variables. The following query that shows SQL in the SGA where there are a large number of similar statements:
/* Formatted on 2011/6/22 10:51:28 (QP5 v5.163.1008.3004) */
SELECT SUBSTR (sql_text, 1, 40) "SQL", COUNT (*), SUM (executions) "TotExecs"
FROM v$sqlarea
WHERE executions < 5
GROUP BY SUBSTR (sql_text, 1, 40)
HAVING COUNT (*) > 30
ORDER BY 2;
Note: If there is latch contention for the library cache latches the above Statement may cause yet further contention problems.
The values 40,5 and 30 are example values so this query is looking for different statements whose first 40 characters are the same which have only been executed a few times each and there are at least 30 different occurrences in the shared pool.
This query uses the idea it is common for literal statements to begin “SELECT col1, col2, col3 FROM table WHERE…” with the leading portion of each statement being the same.
Note: There is often some degree of resistance to converting literal SQL to use bind variables. Be assured that it has been proven time and time again that performing this conversion for the most frequently occurring statements can eliminate problems with the shared pool and improve scalability greatly.
2.1.3.1.11.Performance Effects
Oracle performance can be severely compromised by large volumes of literal SQL. Some of the symptoms that may be noticed are:
(1). System is CPU bound and exhibits an insatiable appetite for CPU.
(2). System appears to periodically “hang” after some period of normal operation.
(3). Latch contention on shared pool and library cache latches.
(4). Increasing the shared pool size delays the problem but it re-occurs more severely.
2.1.3.1.12.Identifying the Problem
An Oracle instance suffering from too much literal SQL will likely exhibit some of the symptoms above. There are several investigations the DBA can use to help confirm that this is indeed happening in the instance.
2.1.3.1.13.Library Cache Hit Ratio
The library cache hit ratio should be very high (98%) when SQL is being shared and will remain low regardless of shared pool sizing adjustments when SQL is chronically non-sharable. Use the following query to determine the hit ratios by namespace in the library cache.
/* Formatted on 2011/6/22 10:56:34 (QP5 v5.163.1008.3004) */
SELECT namespace, (100 * gethitratio) hit_ratio FROM v$librarycache;
The “SQL AREA” namespace will be the one affected by literal SQL.
2.1.3.1.14.SQL Parse-to- Execute Ratio
The following query displays the percentage of SQL executed that did not incur an expensive hard parse. Literal SQL will always be fully parsed, so a low percentage may indicate a literal SQL or other SQL sharing problem.
/* Formatted on 2011/6/22 10:58:35 (QP5 v5.163.1008.3004) */
SELECT 100 * (1 - A.hard_parses / B.executions) noparse_ratio
FROM (SELECT VALUE hard_parses
FROM vsysstat
WHERE name = 'parse count (hard)') A,
(SELECT VALUE executions
FROM vsysstat
WHERE name = 'execute count') B;
Again, when this ratio is high Oracle is sparing CPU cycles by avoiding expensive parsing and when low there may be a literal SQL problem.
2.1.3.1.15.Latch Free Waiters
A telltale sign that the instance is suffering library cache and shared pool problems is active latch contention with sessions waiting on the “latch free” wait event. The following query will select all current sessions waiting for either the shared pool or library cache latches.
/* Formatted on 2011/6/22 11:01:08 (QP5 v5.163.1008.3004) */
SELECT sid, event, name latch
FROM vsession_wait w, vlatch l
WHERE w.event = 'latch free' AND l.latch# = w.p2 AND l.name IN ('shared pool','library cache');
When this query selects more than 5-10% of total sessions there is likely very serious performance degradation taking place and literal SQL may be the culprit.
2.1.3.1.16.Finding Literal SQL
We can attempt to locate literal SQL in the V$SQL fixed view by grouping and counting statements that are identical up to a certain point based on the observation that most literal SQL becomes textually distinct toward the end of the statement (e.g. in the WHERE clause). The following query returns SQL statements having more than 10 statements that textually match on leading substring.
/* Formatted on 2011/6/22 11:04:55 (QP5 v5.163.1008.3004) */
SELECT S.sql_text
FROM vsql S,
( SELECT SUBSTR (sql_text, 1, &&size) sqltext, COUNT (*)
FROM vsql
GROUP BY SUBSTR (sql_text, 1, &&size)
HAVING COUNT (*) > 10) D
WHERE SUBSTR (S.sql_text, 1, &&size) = D.sqltext;
The SQL*Plus substitution variable &&size can be adjusted to vary the text length used to match statements, as can the value 10 used to filter by level of duplication. Note that this query is expensive and should not be executed frequently on production systems.
2.1.3.2.Memory Fragment Ation
The primary problem that occurs is that free memory in the shared pool becomes fragmented into small pieces over time.
Any attempt to allocate a large piece of memory in the shared pool will cause large amount of objects in the library cache to be flushed out and may result in an ORA-4031 out of shared memory error.
Oracle ORA-04031 错误 说明
2.1.3.2.1.DIAGNOSIS
(1)ORA-4031 ERROR
One way to diagnose that this is happening is to look for ORA-4031 errors being returned from applications. When an attempt is made to allocate a large contiguous piece of shared memory, and not enough contiguous memory can be created in the shared pool, the database will signal this error.
Before this error is signalled, all objects in the shared pool that are not currently pinned or in use will be flushed from the shared pool, and their memory will be freed and merged. This error only occurs when there is still not a large enough contiguous piece of free memory after this happens. There may be very large amounts of total free memory in the shared pool, but just not enough contiguous memory.
Note: The compiled code for a package was split into more than one-piece, each piece being only about 12K in size. So, the 64K restriction was lifted; however, packages larger 100K still may have problems compiling. Furthermore, with releases 7.2/2.3 of Oracle7/PLSQL, loading a library unit (package, function, and procedure) into the shared pool does NOT require one contiguous piece of memory in the shared pool. This means that chances of getting ORA-4031 is dramatically reduced.
(2)INIT.ORA PARAMETER
An init.ora parameter can be set so that whenever an ORA-4031 error is signalled a dump will occur into a trace file. By looking for these trace files, the DBA can determine that these errors are occurring. This is useful when applications do not always report errors signalled by oracle, or if users do not report the errors to the DBAs. The parameter is the following:
Event = “4031 trace name errorstack”
This will cause a dump of the oracle state objects to occur when this error is signalled. By looking in the dump for ‘Load=X’ and then looking up a few lines for ‘name=’ you can often tell whether an object was being loaded into the shared pool when this error occurred. If an object was being loaded then it is likely that this load is the cause of the problem and the Object should be ‘kept’ in the shared pool. The object being loaded is the object printed after the ‘name=’.
(3)XKSMLRU
There is a fixed table called XKSMLRU that tracks allocations in the shared pool that cause other objects in the shared pool to be aged out. This fixed table can be used to identify what is causing the large allocation.
The columns of this fixed table are the following: KSMLRCOM -allocation comment that describes the type of allocation.
If this comment is something like ‘MPCODE’ or ‘PLSQL%’ then there is a large PL/SQL object being loaded into the shared pool. This PL/SQL object will need to be ‘kept’ in the shared pool. If this comment is ‘kgltbtab’ then the allocation is for a dependency table in the library cache. This is only a problem when several hundred users are logged on using distinct user ids.
The solution in this case is to use fully qualified names for all table references. This problem will not occur in 7.1.3 or later.
If you are running MTS and the comment is something like ‘Fixed UGA’ then the problem is that the init.ora parameter ‘open_cursors’ is set too high.
KSMLRSIZ – amount of contiguous memory being allocated. Values over around 5K start to be a problem, values over 10K are a serious problem, and values over 20K are very serious problems. Anything less then 5K should not be a problem.
KSMLRNUM – number of objects that were flushed from the shared pool in order allocate the memory.
KSMLRHON – The name of the object being loaded into the shared pool if the object is a PL/SQL object or a cursor.
KSMLROHV – hash value of object being loaded
KSMLRSES – SADDR of the session that loaded the object.
The advantage of XKSMLRU is that it allows you to identify problems with fragmentation that are effecting performance, but that are not bad enough to be causing ORA-4031 errors to be signalled. If a lot of objects are being periodically flushed from the shared pool then this will cause response time problems and will likely cause library cache latch contention Problems when the objects are reloaded into the shared pool.
One unusual thing about the XKSMLRU fixed table is that the contents of the fixed table are erased whenever someone selects from the fixed table. This is done since the fixed table stores only the largest allocations that have occurred.
The values are reset after being selected so that subsequent large allocations can be noted even if they were not quite as large as others that occurred previously. Because of this resetting, the output of selecting from this table should be carefully noted Since it cannot be reselected if it is forgotten. Also you should take care that there are not multiple people on one database that select from this table because only one of them will select the real data.
To monitor this fixed table just runs the following:
select * from X$KSMLRU where KSMLRSIZ >5000;
2.1.3.2.2.ACTION
(1)KEEPING OBJECTS
The primary source of problems is large PL/SQL objects. The means of correcting these errors is to ‘keep” large PL/SQL objects in the shared pool at startup time. This will load the objects into the shared pool and will make sure that the objects are never aged out of the shared pool. If the objects are never aged out then there will not be a problem with trying to load them and not having enough memory.
Objects are ‘kept’ in the shared pool using the dbms_shared_pool package that is defined in the dbmspool.sql file. For example:
exec dbms_shared_pool.keep('SYS.STANDARD');
All large packages that are shipped should be ‘kept’ if the customer uses PL/SQL. This includes ‘STANDARD’, ‘DBMS_STANDARD’, and ‘DIUTIL’. All large customer packages should also be marked ‘kept’.
One restriction on the ‘keep’ procedure is that it only works on packages. If the customer has large procedures or large anonymous blocks, then these will need to be put into packages and marked kept.
You can determine what large stored objects are in the shared pool by selecting from the V$DB_OBJECT_CACHE fixed view. This will also tell you which objects have been marked kept. This can be done with the following query:
/* Formatted on 2011/6/22 13:13:23 (QP5 v5.163.1008.3004) */
SELECT *
FROM V$DB_OBJECT_CACHE
WHERE sharable_mem > 10000;
Note that this query will not catch PL/SQL objects that are only rarely used and therefore the PL/SQL object is not currently loaded in the shared pool.
To determine what large PL/SQL objects are currently loaded in the shared pool, are not marked ‘kept’, and therefore may cause a problem, execute the following:
/* Formatted on 2011/6/22 13:14:25 (QP5 v5.163.1008.3004) */
SELECT name, sharable_mem
FROM V$DB_OBJECT_CACHE
WHERE sharable_mem > 10000
AND ( TYPE = 'PACKAGE'
OR TYPE = 'PACKAGE BODY'
OR TYPE = 'FUNCTION'
OR TYPE = 'PROCEDURE')
AND kept = 'NO';
(2)USE BIND VARIABLES
Another thing that can be done to reduce the amount of fragmentation is to reduce or eliminate the number of SQL statements in the shared pool that are duplicates of each other except for a constant that is embedded in the statement. The statements should be replaced with one statement that uses a bind variable instead of a constant.
For example:
select * from emp where empno=1;
select * from emp where empno=2;
select * from emp where empno=3;
Should all be replaced with:
select * from emp where empno=:1;
You can identify statements that potentially fall into this class with a query like the following:
/* Formatted on 2011/6/22 13:18:04 (QP5 v5.163.1008.3004) */
SELECT SUBSTR (sql_text, 1, 30) sql, COUNT (*) copies
FROM v$sqlarea
GROUP BY SUBSTR (sql_text, 1, 30)
HAVING COUNT (*) > 3;
(3)MAX BIND SIZE
It is possible for a sql statement to not be shared because the max bind variable lengths of the bind variables in the statement do not match. This is automatically taken care of for precompiler programs and forms programs, but could be a problem for programs that directly use OCI. The bind call in OCI takes two arguments, one is the max length of the value, and the other is a pointer to the actual length. If the current length is always passed in as the max length instead of the max possible length for the variable, then this could cause the sql statement not to be shared.
To identify statements that might potentially have this problem execute the following statement:
/* Formatted on 2011/6/22 13:22:20 (QP5 v5.163.1008.3004) */
SELECT sql_text, version_count
FROM v$sqlarea
WHERE version_count > 5;
(4)ELIMINATING LARGE ANONYMOUS PL/SQL
Large anonymous PL/SQL blocks should be turned into small anonymous PL/SQL blocks that call packaged functions. The packages should be ‘kept’ in memory.
This includes anonymous PL/SQL blocks that are used for trigger definitions. Large anonymous blocks can be identifie d with the following query:
/* Formatted on 2011/6/22 13:25:22 (QP5 v5.163.1008.3004) */
SELECT sql_text
FROM v$sqlarea
WHERE command_type = 47 -- command type for anonymous block
AND LENGTH (sql_text) > 500;
Note that this query will not catch PL/SQL blocks that are only rarely used and therefore the PL/SQL block is not currently loaded in the shared pool.
Another option that can be used when an anonymous block cannot be turned into a package is to mark the anonymous block with some string so that it can be identified in v$sqlarea and marked ‘kept’.
For example, instead of using
/* Formatted on 2011/6/22 13:33:20 (QP5 v5.163.1008.3004) */
DECLARE
x NUMBER;
BEGIN
x := 5;
END;
one can use:
/* Formatted on 2011/6/22 13:33:34 (QP5 v5.163.1008.3004) */
DECLARE /* KEEP_ME */
x NUMBER;
BEGIN
x := 5;
END;
You can then use the following procedure to select these statements out of the shared pool and mark them ‘kept’ using the dbms_shared_pool.keep package.
/* Formatted on 2011/6/22 13:34:55 (QP5 v5.163.1008.3004) */
DECLARE
/* DONT_KEEP_ME */
addr VARCHAR2 (10);
hash NUMBER;
CURSOR anon
IS
SELECT address, hash_value
FROM v$sqlarea
WHERE command_type = 47 -- command type for anonymous block
AND sql_text LIKE '% KEEP_ME %'
AND sql_text NOT LIKE '%DONT_KEEP_ME%';
BEGIN
OPEN anon;
LOOP
FETCH anon
INTO addr, hash;
EXIT WHEN anon%NOTFOUND;
DBMS_SHARED_POOL.keep (addr || ',' || TO_CHAR (hash), 'C');
END LOOP;
END;
To create DBMS_SHARED_POOL, run the DBMSPOOL.SQL script. The PRVTPOOL.PLB script is automatically executed after DBMSPOOL.SQL runs. These scripts are not run by as part of standard database creation.
2.1.3.3.Initialization Parameters
The following Oracle initialization parameters have an important impact on library cache and shared pool performance.
(1)._KGL_BUCKET_COUNT
(2)._KGL_LATCH_COUNT
(3).cursor_sharing
(4).shared_pool_size
(5).shared_pool_reserved_size
(6).shared_pool_reserved_min_alloc
(7).large_pool_size
(8).large_pool_min_alloc
(9).parallel_min_message_pool
(10).backup_io_slaves
(11).temporary_table_locks
(12).dml_locks
(13).sequence_cache_entries
(14).row_cache_cursors
(15).max_enabled_roles
(16).mts_dispatchers
(17).mts_max_dispatchers
(18).mts_servers
(19).mts_max_servers
(20).cursor_space_for_time
2.1.3.4.Cursor
Cursor直译过来就是“游标”,它是Oracle数据库中SQL解析和执行的载体。Oracle数据库是用C语言写的,可以将Cursor理解成是C语言的一种数据结构(Structure)。
Oracle数据库里的Cursor分为两种:一种是Shared Cursor;另一种是Session Cursor。
2.1.3.4.1.Shared Cursor的含义
Shared Cursor就是指缓存在库缓存里的一种库缓存对象,说白了就是指缓存在库缓存里的SQL语句和匿名PL/SQL语句所对应的库缓存对象。Shared Cursor是Oralce缓存在Library Cache中的几十种库缓存对象之一,它所对应的库缓存对象名柄的Namespace属性的值是CRSR(也就是Cursor的缩写)。Shared Cursor里会存储目标SQL的SQL文本、解析树、该SQL所涉及的对象定义、该SQL所使用的绑定变量类型和长度,以及该SQL的执行计划等信息。
Oracle数据库中的Shared Cursor又细分为Parent Cursor(父游标)和Child Cursor(子游标)这两种类型,我们可以通过分别查询视图VSQLAREA和VSQL来查看当前缓存在库缓存中的Parent Cursor和Chile Cursor,其中VSQLAREA用于查看Parent Cursor,VSQL用于查看Child Cursor。
Parent Cursor和Child Cursor的结构是一样的(它们都是以库缓存对象名柄的方式缓存在库缓存中,Namespace属性的值均为CRSR),它们的区别在于目标SQL的SQL文本会存储在其Parent Cursor所对应的库缓存对象句柄的属性Name中(Child Cursor对应的库缓存对象名柄的Name属性值为空,这意味着只有通过Parent Cursor才能找到相应的Child Cursor),而该SQL的解析树和执行计划则会存储在其Child Cursor所对应的库缓存对象句柄的Heap 6中,同时Oracle会在该SQL所对应的Parent Cursor的Heap 0的Chhild table中存储从属于该Parent Cursor的所有Child Cursor的库缓存对象名柄地址(这意味着Oracle可以通过访问Parent Cursor的Heap 0中的Child table而依次顺序访问从属于该Parent Cursor的所有Child Cursor)。
这种Parent Cursor和Child Cursor的结构就决定了在Oracle数据库里,任意一个目标SQL一定会同时对应两个Shared Cursor,其中一个是Parent Cursor,另外一个则是Child Cursor,Parent Cursor会存储该SQL的SQL文本,而该SQL真正的可以被重用的解析树和执行计划则存储在Child Cursor中。
Oracle设计这种Parent Cursor和Child Cursor并存的结果是因为Oralce是根据目标SQL的SQL文本的哈希值去相应Hash Bucket中的库缓存对象句柄链表里找匹配的库缓存对象句柄的,但是不同的SQL文本对应的哈希值可能相同,而且同一个SQL(此时的哈希值自然是相同的)也有可能有多份不同的解析权和执行计划。可以想象一下,如果它们都处于同一个Hash Bucket中的库缓存对象句柄链表里,那么这个库缓存对象句柄的长度就不是最优的长度(这意味着会增加Oracle从头到尾搜索这个库缓存对象句柄链表所需要耗费的时间和工作量),为了能尽量减少对应Hash Bucket中库缓存对象句柄链表的长度,Oracle设计了这种嵌套的Parent Cursor和Child Cursor并存的结构。
下面看一个Parent Cursor和Child Cursor的实例:
SQL>select empno,ename from emp;
EMPNO ENAME
---------- ------------------------------
7369 SMITH
......省略部分输出
当一条SQL第一次被执行的时候,Oracle会同时产生一个Parent Cursor和一个Child Cursor。上述SQL是首次执行,所以现在Oracle应该会同时产生一个Parent Cursor和一个Child Cursor。使用如下语句验证:
select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%';
注意到原目标SQL在VSQLAREA中只有一条匹配记录,且这条记录的列VERSION_COUNT的值为1(VERSION_COUNT表示这个Parent Cursor所拥有的所有Child Cursor的数量),这说明Oracle在执行目标SQL时确实产生了一个Parent Cursor和一个Child Cursor。
上述SQL所对应的SQL_ID为“78bd3uh4a08av”,用这个SQL_ID就可以去VSQL中查询该SQL对应的所有Child Cursor的信息:
SQL>col sql_text for a50
SQL>select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%';
SQL_TEXT SQL_ID VERSION_COUNT
------------------------------ ---------------- ------
select empno,ename from emp 78bd3uh4a08av 1
注意到目标SQL_ID在V$SQL中只有一条匹配记录,而且这条记录的CHILD_NUMBER的值为0(CHILD_NUMBER表示某个Child Cursor所对应的子游标号),说明Oracle在执行原目标SQL时确实只产生了一个子游标号为0的Child Cursor。
把原目标SQL中的表名从小写换成大写的EMP后再执行:
SQL>select empno,ename from EMP;
EMPNO ENAME
---------- -------
7369 SMITH
......省略部分输出
Oracle会根据目标SQL的SQL文本的哈希值去相应的Hash Bucket中找匹配的Parent Cursor,而哈希运算是对大小写敏感的,所以当我们执行上述改写后的目标SQL时,大写EMP所对应的Hash Bucket和小写emp所对应的Hash Bucket极有可能不是同一个Hash Bucket(即便是同一个Hash Bucket也没有关系,因为Oracle还会继续比对Parent Cursor所在的库缓存对象句柄的Name属性值,小写所对应的Parent Cursor的Name值为“select empno,ename from emp”,大写EMP对就的Parent Cursor的Name值为“select empno,ename from EMP”,两者显然不相等)。也就是说,小写emp所对应的Parent Cursor并不是大写EMP所要找的Parent Cursor,两者不能共享,所以此时Oracle肯定会新生成一对Parent Cursor和Child Cursor。
下面来验证一下:
SQL>select sql_text,sql_id,version_count from vsqlarea where sql_text like 'select empno,ename%';
SQL_TEXT SQL_ID VERSION_COUNT
---------------------------- ---------------------- -------------
select empno,ename from emp 78bd3uh4a08av 1
select empno,ename from EMP 53j2db788tnx9 1
SQL>select plan_hash_value,child_number from vsql where sql_id='53j2db788tnx9';
PLAN_HASH_VALUE CHILD_NUMBER
--------------- ------------
3956160932 0
从上述结果可以看出,针对大写EMP所对应的目标SQL(大写EMP),Oracle确实新生成了一个Parent Cursor和一个Child Cursor。
现在构造一个同一个Parent Cursor下有不同Child Cursor的实例:
使用scott用户登录,再次执行小写emp所对应的目标SQL:
SQL>select empno,ename from emp;
EMPNO ENAME
--------- ------
7369 SMITH
......省略部分输出
Oracle根据目标SQL的SQL文本的哈希值去相应的Hash Bucket中找匹配的Parent Cursor,找到了匹配的Parent Cursor后还得遍历从属于该Parent Cursor的所有Child Cursor(因为可以被重用的解析权和执行计划都存储在Child Cursor中)。
对上述SQL(小写emp)而言,因为同样的SQL文本之前在ZX用户下已经执行过,在Library Cache中也已经生成了对应的Parent Cursor和Child Cursor,所以这里Oracle根据上述SQL的SQL文本的哈希值去Library Cache中找匹配的Parent Cursor时肯定时能找到匹配记录的。但接下来遍历从属于该Parent Cursor的所有Child Cursor时,Oracle会发现对应Child Cursor中存储的解析权和执行计划此时是不能被重用的,因为此时的Child Cursor里存储的解析树和执行计划针对的是ZX用户下的表EMP,面上述SQL针对的则是SCOTT用户下的同名表EMP,待查询的目标表根本就不是同一个表,解析权和执行计划当然不能共享了。这意味着Oracle还得针对上述SQL从头再做一次解析,并把解析后的解析树和执行计划存储在一个新生成的Child Cursor里,再把这个Child Cursor挂在上述Parent Cursor下(即把新生成的Child Cursor在库缓存对象句柄地址添加到上述Parent Cursor的Heap 0的Child table中)。也就是说一旦上述SQL执行完毕,该SQL所对应的Parent Cursor下就会有两个Child Cursor,一个Child Cursor中存储的是针对ZX用户下表EMP的解析树和执行计划,另外一个Child Cursor中存储的则是针对SCOTT用户下同名表EMP的解析树和执行计划。
使用如下语句验证:
SQL>select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%';
SQL_TEXT SQL_ID VERSION_COUNT
--------------------------- ------------------- -------------
select empno,ename from emp 78bd3uh4a08av 2
select empno,ename from EMP 53j2db788tnx9 1
注意到上述SQL(小写emp)V$SQLAREA中的匹配记录的列VERSION_COUNT的值为2 ,说明Oracle在执行该SQL时确实产生了一个Parent Cursor和两个Child Cursor。
使用如下语句查询上述SQL所对应的Child Cursor的信息:
SQL>select plan_hash_value,child_number from v$sql where sql_id='78bd3uh4a08av';
PLAN_HASH_VALUE CHILD_NUMBER
--------------- ------------
3956160932 0
3956160932 1
注意到上述SQL在V$SQL中有两条匹配记录,且这两条记录的CHILD_NUMBER的值分别为0和1,说明Oracle在执行上述SQL时确实产生了两个Child Cursor,它们的子游标号分别为0和1.

Oracle在解析目标SQL时去库缓存中查找匹配Shared Cursor的过程程实际上是在依次顺序执行如下步骤:
(1)根据目标SQL的SQL文本的哈希值去库缓存中找匹配的Hash Bucket。注意,更准确的说,这里的哈希运算是基于对应库缓存对象句柄的属性Name和Namespace的值的,只不过对于SQL语句而言,其对应的库缓存对象句柄的属性Name的值就是该SQL的SQL文本,属性Namespace的值就是常量“CRSR”,所以这里可以近似看作是只根据目标SQL的SQL文本来做哈希运算。
(2)然后在匹配的Hash Bucket的库缓存对象链表中查找匹配的Parent Cursor,当然,在查找匹配Parent Cursor的过程中肯定会比对目标SQL的SQL文本(因为不同的SQL文本计算出来的哈希值可能是相同的)。
(3)步骤2如果找到了匹配的Parent Cursor,则Oracle接下来就会遍历从属于该Parent Cursor的所有Child Cursor以查找匹配的Child Cursor。
(4)步骤2如果找不到了匹配的Parent Cursor,则也意味着此时没有可以共享的解析树和执行计划,Oracle就会从头开始解析上述目标SQL,新生成一个Parent Cursor和一个Child Cursor,并把它们挂在对应的Hash Bucket中。
(5)步骤3如果找到了匹配的Child Cursor,则Oracle就会把存储于该Child Cursor中的解析树和执行计划直接拿过来重用,而不用再从头开始解析。
(6)步骤3如果找不到匹配的Child Cursor,则意味着没有可以共享的解析树和执行计划,接下来Oracle也会从头开始解析上述目标SQL,新生成一个Child Cursor,并把这个Child Cursor挂在对应的Parent Cursor下。
2.1.3.4.2.硬解析
硬解析(Hard Parse)是指Oracle在执行目标SQL时,在库缓存中找不到可以重用的解析树和执行计划,而不得不从头开始解析目标SQL并生成相应的Parent Cursor和Child Cursor的过程。
硬解析实际上有两种类型,一种是在库缓存中找不到匹配的Parent Cursor,此时Oracle会从头开始解析目标SQL,新生成一个Parent Cursor和Child Cursor,并把它们挂在对应的Hash Bucket中;另一种是找到了匹配的Parent Cursor但未找到匹配的Child Cursor,此时Oracle也会从头开始解析该目标SQL,新生成一个Child Cursor,并把这个Child Cursor挂在对应的Parent Cursor下。
硬解析是非常不好的,它的危害性主要体现在如下这些方面:
硬解析可能会导致Shared Pool Latch的争用。无论是哪种类型的硬解析,都至少需要新生成一个Child Cursor,并把目标SQL的解析树和执行计划载入该Child Cursor里,然后把这个Child Cursor存储在库缓存中。这意味着Oracle必须在Shared Pool中分配出一块内存区域用于存储上述Child Cursor,而在Shared Pool中分配内存这个动作是要持有Shared Pool Latch的(Oracle数据库中的Latch的作用之一就是保护共享内存的分配),所以如果有一定数量的并发硬解析,可能会导致Shared Pool Latch争用,而且一旦发生大量的Shared Pool Latch争用,系统的性能和可扩展性会受到严重影响(常常表现为CPU的占用率居高不下,接近100%)。
硬解析可能会导致库缓存相关Latch(如Library Cache Latch)和Mutex的争用。无论是哪种类型的硬解析,都需要扫描相关的Hash Bucket中的库缓存对象句柄链表,而扫描库缓存对象句柄链表这个动作是要持有Library Cache Latch的(Oracle数据库中Latch的另外一个作用就是用于共享SGA内存结构的并发访问控制),所以如果有一定数量的并发硬解析,则可能会导致Library Cache Latch的争用。和Shared Pool Latch争用一样,一旦发生大量的Library Cache Latch的争用,系统的性能和可扩展性也会受到严重影响。从11gR1开始,Oracle用Mutex替换了库缓存相关Latch,所以在Oracle 11gR1及其后续的版本中,将不再存在库缓存相关Latch的急用,取而代之的是Mutex的争用(可以简单的将Mutex理解成一种轻量级的Latch,Mutex主要也是用于共享SGA内存结果的并发访问控制),Oracle也因此引入了一系列新的等待事件来描述这种Mutex的争用,比如:Cursor: pin S、Cursor: pin X、Cursor: pin S wait on X、Cursor:mutex S、Cursor:mutex X、Library cache:mutex X等。
另外需要注意的是,Oracle在做硬解析时对Shared Pool Latch和Library Cache Latch的持有过程,大致如下:Oracle首先持有Library Cache Latch,在库缓存中扫描相关Hash Bucket中的库缓存对象句柄链表,以查看是否有匹配的Parent Cursor,然后释放Library Cache Latch(这里释放的原因是因为没有找到匹配的parent Cursor)。接下来是硬解析的后半部分,首先持有Library Cache Latch,然后在不释放Library Cache Latch的情况下持有Shared Pool Latch,以便从Shared Pool中申请分配内存,成功申请后就会释放Shared Pool Latch,最后再释放Library Cache Latch。
对于OLTP类型的系统而言,硬解析是万恶之源。
2.1.3.4.3.软解析
软解析(Soft Parse)是指Oracle在执行目标SQL时,在Library Cache中找到了匹配的Parent Cursor和Child Cursor,并将存储在Child Cursor中的解析树和执行计划直接拿过来重用,无须从头开始解析的过程。
和硬解析相比,软解析的优势主要表现在如下几个方面:
软解析不会导致Shared Pool Latch的争用。因为软解析能够在库缓存中找到匹配的Parent Cursor和Child Cursor,所以它不需要生成新的Parent Cursor和Child Cursor。这意味着软解析根本就不需要持有Shared Pool Latch以便在Shared Pool中申请分配一块共享内存区域,既然不需要持有Shared Pool Latch,自然不会有Shared Pool Latch争用,即Shared Pool Latch的争用所带来的系统性能和可扩展性的问题对软解析来说并不存在。
软解析虽然也可能会导致库缓存相关Latch(如Library Cache Latch)和Mutex的争用,但软解析持有库缓存相关Latch的次数要少,而且软解析对某些Latch(如Library Cache Latch)持有的时间会比硬解析短,这意味着即使产生了库缓存相关Latch的争用,软解析的争用程度也没有硬解析那么严重,即库缓存相关Latch和Mutex的争用所带来的系统性能和可扩展性的问题对软解析来说要比硬解析少很多。
正是基于上述两个方面的原因,如果OLTP类型的系统在执行目标SQL时能够广泛使用软解析,则系统的性能和可扩展性就会比全部使用硬解析时有显著的提升,执行目标SQL时需要消耗的系统资源(主要体现在CPU上)也会显著降低。
2.1.4.Database Buffer Cache
Database Buffer Cache是SGA中的一个高速缓存区域,用来存储从数据库中读取数据段的数据块(如表、索引和簇)。数据块的大小由数据库服务器init.ora文件中的DB_BLOCK_BUFFERS参数决定(用数据库块的个数表示)。在调整和管理数据库时,调整数据块缓存区的大小是一个重要的部分。
因为数据块缓存区的大小固定,并且其大小通常小于数据库段所使用的空间,所以它不能一次装载下内存中所有的数据库段。通常,数据块缓存区只是数据库大小的1%~2%,Oracle使用最近最少使用(LRU,Least Recently Used)算法来管理可用空间。当存储区需要自由空间时,最近最少使用块将被移出,新数据块将在存储区代替它的位置。通过这种方法,将最频繁使用的数据保存在存储区中。
然而,如果SGA的大小不足以容纳所有最常使用的数据,那么,不同的对象将争用数据块缓存区中的空间。当多个应用程序共享同一个SGA时,很有可能发生这种情况。此时,每个应用的最近使用段都将与其他应用的最近使用段争夺SGA中的空间。其结果是,对数据块缓存区的数据请求将出现较低的命中率,导致系统性能下降。
DB_CACHE_SIZE
通过参数DB_CACHE_SIZE可指定DB buffer cache的大小
ALTER SYSTEM SET DB_CACHE_SIZE=20M scope=both;
服务进程从数据文件读数据到buffer cache;
DBWn从buffer cache写数据到数据文件。
buffer cache的四种状态:
1)pinned:当前块正在读到cache或正写到磁盘,其他会话等待访问该块。
2)clean:
3)free/unused:buffer内为空,为实例刚启动时的状态。
4)dirty:脏数据,数据块被修改,需要被DBWn刷新到磁盘,才能执行过期处理。
同一个数据库中,支持多种大小的数据块缓存。通过DB_nK_CACHE_SIZE参数指定,如
• DB_2K_CACHE_SIZE
• DB_4K_CACHE_SIZE
• DB_8K_CACHE_SIZE
• DB_16K_CACHE_SIZE
• DB_32K_CACHE_SIZE标准块缓存区大小由DB_CACHE_SIZE指定。如标准块为nK,则不能通过DB_nK_CACHE_SIZE来指定标准块缓存区的大小,应由DB_CACHE_SIZE指定。标准块为8K,则数据库可以设置的块缓存大小的参数如下:
• DB_CACHE_SIZE (指定标准块为8K的缓存区)
• DB_2K_CACHE_SIZE (指定块大小为2K的缓存区)
• DB_4K_CACHE_SIZE (指定块大小为4K的缓存区)
• DB_16K_CACHE_SIZE (指定块大小为16K的缓存区)
• DB_32K_CACHE_SIZE (指定块大小为32K的缓存区)
2.1.5.Redo Log Buffer
Redo描述对数据库进行的修改。它们写到Online Redo Log文件中,以便在数据库恢复过程中用于向前滚动操作。然而,在被写入Online Redo Log文件之前,事务首先被记录在Redo Log Buffer中。 数据库可以周期地分批向Online Redo Log文件中写Redo的内容。Redo Log Buffer的大小(以字节为单位)由init.ora文件中的LOG_BUFFER参数决定。
1、服务进程从用户空间拷贝每条DML/DDL语句的redo条目到redo log buffer中。
2、redo log buffer是一个可以循环使用的buffer,服务进程拷贝新的redo覆盖掉redo log buffer中已通过LGWR写入磁盘(online redo log)的条目。
3、导致LGWR执行写redo log buffer到online redo log的条件
– 用户执行事务提交commit
– 每3秒钟或redo log buffer内已达到1/3满或包含1MB数据
– DBWn进程将修改的缓冲区写入磁盘时(如果相应的重做日志数据尚未写入磁盘)
2.1.6.Java Pool
Java池为Java命令提供语法分析。Java池的大小(以字节为单位)通过init.ora文件的JAVA_POOL_SIZE参数设置。 init.ora文件的JAVA_POOL_SIZE参数缺省设置为10MB。
1、JAVA_POOL_SIZE
通过JAVA_POOL_SIZE参数指定Java pool大小。
保存了JVM中特定会话的Java Code和数据。
2、在编译数据库中的Java代码和使用数据库中的Java资源对象时,都会用到。
Java的类加载程序对每个加载的类会使用大约8K的空间。
系统跟踪运行过程中,动态加载的java类,也会使用到share pool。
2.1.7.Large Pool
Large Pool是一个可选内存区。如果使用线程服务器选项或频繁执行备份/恢复操作,只要创建一个大池,就可以更有效地管理这些操作。大池将致力于支持SQL大型命令。利用大池,就可以防止这些SQL大型命令把条目重写入SQL共享池中,从而减少再装入到库缓存区中的语句数量。大池的大小(以字节为单位)通过init.ora文件的LARGE_POOL_SIZE参数设置,用户可以使用init.ora文件的LARGE_POOL_MIN_ALLOC参数设置大池中的最小位置。作为使用Large Pool的一种选择方案,可以用init.ora文件的SHARED_POOL_RESERVED_SIZE参数为SQL大型语句保留一部分SQL共享池。
1)Large Pool大小通过LARGE_POOL_SIZE参数指定:
SQL> alter system set large_pool_size=20m scope=both;
2)作用:
– 为I/O服务进程分配内存
– 为备份与恢复操作分配内存
– 为Oracle共享服务器模式与多个数据库间的联机事务分配内存。
通过从large pool中为共享服务器模式分配会话内存,可以减少share pool因频繁为大对象分配和回收内存而产生的碎片。将大的对象从share pool中分离出来,可以提高shared pool的使用效率,使其可以为新的请求提供服务或者根据需要保留现有的数据。
2.1.8.Keep-Recycle-Default Buffer Pool
1)Keep:通过db_keep_cache_size参数指定。该buffer内的数据可能被重用,以降低I/O操作。该池的大小要大于指定到该池的段的总和。读入到keep buffer的块不需要过期操作。
2)Recycle:通过db_recycle_cache_size参数指定。该池中的数据被重用机会较小,该池大小要小于分配到该池的段的总和。读入该池的块需要经常执行过期处理。
3)Default:相当于一个没有Keep与Recycle池的实例的buffer cache,通过db_cache_size参数指定。
为对象明确指定buffer pool
buffer_pool子句,用来为对象指定默认的buffer pool,是storage子句的一部分。
对create与alter table、cluster、index语句有效。
如果现有对象没有明确指定buffer pool,则默认都指定为default buffer pool,大小为DB_CACHE_SIZE参数设置的值。
语法:
a.CREATE INDEX cust_idx ON tt(id) STORAGE (BUFFER_POOL KEEP);
b.ALTER TABLE oe.customers STORAGE (BUFFER_POOL RECYCLE);
c.ALTER INDEX oe.cust_lname_ix STORAGE (BUFFER_POOL KEEP);
2.1.9.Automatic Memory Management(ASMM)
- SGA_TARGET
1)SGA_TARGET默认值为0,即ASMM被禁用。需要手动设置SGA各中各组件的大小。
2)SGA_TARGET为非0时,则启用ASMM,自动调整以下各组件大小:
– DB buffer cache(default pool)
– shared pool
– large pool
– streams pool
– java pool
但ASSM中, 以下参数仍需要手动指定:
– log buffer
– keep、recycle、以及非标准块缓冲区
– 固定SGA以及其他内部分配。
2. 启用ASMM需要将STATISTICS_LEVEL设置成TYPICAL或ALL
3. 启用ASMM,自动调整SGA内部组件大小后。若手动指定某一组件值,则该值为该组件的最小值。如: 手动设置SGA_TARGET=8G,SHARE_POOL_SIZE=1G,则ASMM在自动调整SGA内部组件大小时,保证share pool不会低于1G。
SELECT component, current_size/1024/1024 size_mb FROM v$sga_dynamic_components;
- SGA_MAX_SIZE
SGA_MAX_SIZE指定内存中可以分配给SGA的最大值。
SGA_TARGET是一个动态参数,其最大值为SGA_MAX_SIZE指定的值。
2.2.Background Process
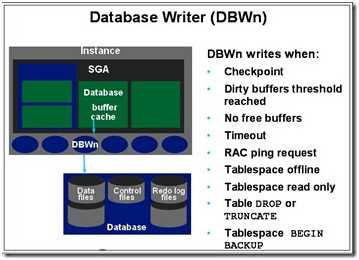
2.2.1.DBWn
n指的是0-9 a-j 多个写进程的区分 将脏块写盘
作用:把SGA中被修改的数据同步到磁盘文件中。保证Buffer Cache中有足够的空闲数据块数量。
PS:如果LGWR出现故障,DBWR不会听从CKPT命令罢工,因为Oracle在将数据缓存区数据写到磁盘前,会先进行日志缓冲区写进日志文件的操作,并耐心的等待其先完成,才会去完成这个内存刷到磁盘的动作,这就是所谓的凡事有记录。
触发条件:
1.产生检查点
2.脏数据缓冲区达到阀值 默认10%
3.扫描整个db buffer没有空闲 db buffer中包含脏的和未脏的 优先写脏数据列表 再写未改的
4.timeout超时 如果DBWR没事做 会被每三秒唤醒一次去巡检 写不写不一定
5.集群环境的ping请求触发多实例的数据写请求 6.表级别的truncate或drop也会触发数据写
7.修改表空间的read only
8.做表空间的offline(离线)
9.热备份 begin backup命令
设置:DB_WRITER_PROCESS用来定义DBWn进程数量。
(commit命令只是把记录修改写入日志文件,不是把修改后的数据写入数据文件)
DBWR将缓冲区写入数据文件。当缓冲区被修改时,它被标志为“弄脏”,DBWR的主要任务是将“弄脏”的缓冲区写入磁盘,使缓冲区保持“干净”。由于缓冲区填入数据库或被用户进程弄脏,空闲缓冲区的数目减少。当空闲缓冲区下降到很少,以致用户进程要从磁盘读入块到内存存储区时无法找到空闲缓冲区时,DBWR将管理缓冲区,使用户进程总是可以获得缓冲区。
Oracle采用LRU(LEAST RECENTLY USED)算法(最近最少使用算法)保持内存中的数据块是最近使用的,使I/O最小。在下列情况预示DBWR 要将弄脏的缓冲区写入磁盘:
当一个服务器进程将一缓冲区移入“弄脏”表,该弄脏表达到临界长度时,该服务进程将通知DBWR进行写。该临界长度是为参数DB-BLOCK-WRITE-BATCH的值的一半。
当一个服务器进程在LRU表中查找DB-BLOCK-MAX-SCAN-CNT缓冲区时,没有查到未用的缓冲区,它停止查找并通知DBWR进行写。出现超时(每次3秒),DBWR 将通知本身。当出现检查点时,LGWR将通知DBWR.在前两种情况下,DBWR将弄脏表中的块写入磁盘,每次可写的块数由初始化参数DB-BLOCK- WRITE-BATCH所指定。如果弄脏表中没有该参数指定块数的缓冲区,DBWR从LUR表中查找另外一个弄脏缓冲区。
如果DBWR在三秒内未活动,则出现超时。在这种情况下DBWR对LRU表查找指定数目的缓冲区,将所找到任何弄脏缓冲区写入磁盘。每当出现超时,DBWR查找一个新的缓冲区组。每次由DBWR查找的缓冲区的数目是为寝化参数DB-BLOCK- WRITE-BATCH的值的二倍。如果数据库空运转,DBWR最终将全部缓冲区存储区写入磁盘。
在出现检查点时,LGWR指定一修改缓冲区表必须写入到磁盘。DBWR将指定的缓冲区写入磁盘。
在有些平台上,一个实例可有多个DBWR。在这样的实例中,一些块可写入一磁盘,另一些块可写入其它磁盘。参数DB-WRITERS控制DBWR进程个数。
2.2.2.LGWR
(劳模,很重要很忙碌的一个进程)
作用: 把log buffer中的日志内容写入联机的日志文件中,释放log用户buffer空间。
触发条件:
1、用户发出commit命令。(在oracle中称为快速提交机制fast commit):把redo log buffer中的记录写入日志文件,写入一条提交的记录
2、三秒定时唤醒。
3、log buffer cache超过1/3,或log buffer cache超过1M。
4、DBWR进程触发:DBWn视图将脏数据块写入磁盘先检测他的相关redo记录是否写入联机日志文件,如果没有就通知LGWR进程。在oracle中成为提前写机制(write ahead):redo记录先于数据记录被写入磁盘
5、联机日志文件切换也将触发LGWR。
LGWR将日志缓冲区写入磁盘上的一个日志文件。LGWR进程将自上次写入磁盘以来的全部日志项输出:
◆当用户进程提交事务时写入一个提交记录。
◆每三秒将日志缓冲区输出。
◆当日志缓冲区的1/3已满时将日志缓冲区输出。
◆当DBWR将修改缓冲区写入磁盘时则将日志缓冲区输出。
LGWR进程同步地写入到活动的镜象在线日志文件组。如果组中一个文件被删除或不可用,LGWR可继续地写入该组的其它文件。
日志缓冲区是一个循环缓冲区。当LGWR将日志缓冲区的日志项写入日志文件后,服务器进程可将新的日志项写入到该日志缓冲区。LGWR 通常写得很快,可确保日志缓冲区总有空间可写入新的日志项。
注意: 有时候当需要更多的日志缓冲区时,LWGR在一个事务提交前就将日志项写出,而这些日志项在以后事务提交后才永久化。
ORACLE使用快速提交机制,当用户发出COMMIT语句时,一个COMMIT记录立即放入日志缓冲区,但相应的数据缓冲区改变是被延迟,直到在更有效时才将它们写入数据文件。当事务提交时,被赋给一个系统修改号(SCN),它同事务日志项一起记录在日志中。由于SCN记录在日志中,以致在并行服务器选项配置情况下,恢复操作可以同步。
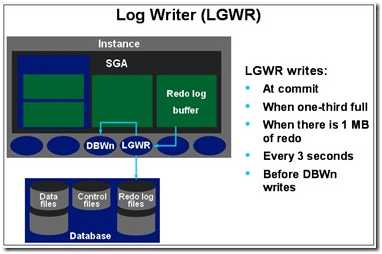
2.2.3.CKPT
- 调度数据写DBWn
- 将新检查点写入数据文件头
- 将新检查点写入控制文件中的数据文件头的记录
作用: 维护数据库一致性状态。检测点时刻数据文件与SGA中的内容一致,这不是一个单独的进程,要和前两个进程一起工作。DBWR写入脏数据,同时触发LGWR进程。
CKPT更新控制文件中的检查点记录。通过设置某参数调整来控制CKPT的触发时间。参数是FAST START MTTR TARGET。
触发条件: 日志切换(log switch)会触发检查点。
CKPT在检查点出现时,对全部数据文件的标题进行修改,指示该检查点。在通常的情况下,该任务由LGWR执行。然而,如果检查点明显地降低系统性能时,可使CKPT进程运行,将原来由LGWR进程执行的检查点的工作分离出来,由CKPT进程实现。对于许多应用情况,CKPT进程是不必要的。只有当数据库有许多数据文件,LGWR在检查点时明显地降低性能才使CKPT运行。 CKPT进程不将块写入磁盘,该工作是由DBWR完成的。初始化参数CHECKPOINT-PROCESS控制CKPT进程的使能或不使能。缺省时为FALSE,即为不使能。
由于Oracle中LGWR和DBWR工作的不一致,Oracle引入了检查点的概念,用于同步数据库,保证数据库的一致性。在Oracle里面,检查点分为两种:完全检查点和增量检查点。下面我们分别介绍这两种检查点的作用:
1、完全检查点
在Oracle8i之前,数据库的发生的检查点都是完全检查点,完全检查点会将数据缓冲区里面所有的脏数据块写入相应的数据文件中,并且同步数据文件头和控制文件,保证数据库的一致。完全检查点在8i之后只有在下列两种情况下才会发生:
(1)DBA手工执行alter system checkpoint的命令;
(2)数据库正常shutdown(immediate,transcational,normal)。
由于完全检查点会将所有的脏数据库块写入,巨大的IO往往会影响到数据库的性能。因此Oracle从8i开始引入了增量检查点的概念。
2、 增量检查点
Oracle从8i开始引入了检查点队列这么一种概念,用于记录数据库里面当前所有的脏数据块的信息,DBWR根据这个队列而将脏数据块写入到数据文件中。检查点队列按时间先后记录着数据库里面脏数据块的信息,里面的条目包含RBA(Redo Block Address,重做日志里面用于标识检查点期间数据块在重做日志里面第一次发生更改的编号)和数据块的数据文件号和块号。在检查点期间不论数据块更改几次,它在检查点队列里面的位置始终保持不变,检查点队列也只会记录它最早的RBA,从而保证最早更改的数据块能够尽快写入。当DBWR将检查点队列里面的脏数据块写入到数据文件后,检查点的位置也要相应地往后移,CKPT每三秒会在控制文件中记录检查点的位置,以表示Instance Recovery时开始恢复的日志条目,这个概念称为检查点的“心跳”(heartbeat)。检查点位置发生变更后,Oracle里面通过4个参数用于控制检查点位置和最后的重做日志条目之间的距离。在这里面需要指出的是,多数人会将这4个参数看作控制增量检查点发生的时间。事实上这是错误的,这4个参数是用于控制检查点队列里面的条目数量,而不是控制检查点的发生。
(1)fast_start_io_target
该参数用于表示数据库发生Instance Recovery的时候需要产生的IO总数,它通过v$filestat的AVGIOTIM来估算的。比如我们一个数据库在发生Instance Crash后需要在10分钟内恢复完毕,假定OS的IO每秒为500个,那么这个数据库发生Instance Recovery的时候大概将产生5001060=30,000次IO,也就是我们将可以把fast_start_io_target设置为30000。
(2)fast_start_mttr_target
我们从上面可以看到fast_start_io_target来估算检查点位置比较麻烦。Oracle为了简化这个概念,从9i开始引入了fast_start_mttr_target这么一个参数,用于表示数据库发生Instance Recovery的时间,以秒为单位。这个参数我们从字面上也比较好理解,其中的mttr是mean time to recovery的简写,如上例中的情况我们可以将fast_start_mttr_target设置为600。当设置了fast_start_mttr_target后,fast_start_io_target这个参数将不再生效,从9i后fast_start_io_target这个参数被Oracle废除了。
(3)log_checkpoint_timeout
该参数用于表示检查点位置和重做日志文件末尾之间的时间间隔,以秒为单位,默认情况下是1800秒。
(4)log_checkpoint_interval
该参数是表示检查点位置和重做日志末尾的重做日志块的数量,以OS块表示。
(5)90% OF SMALLEST REDO LOG
除了以上4个初始化参数外,Oracle内部事实上还将重做日志文件末尾前面90%的位置设为检查点位置。在每个重做日志中,这么几个参数指定的位置可能不尽相同,Oracle将离日志文件末尾最近的那个位置确认为检查点位置。
2.2.4.SMON
实例维护进程 系统监控器 数据库管家
作用:
空间管理: 定期合并空间(老版本才有) 定期回收临时段
实例恢复: (如掉电导致实例意外终止)
恢复的方法: 先前滚⇒后回滚⇒释放资源
前滚 将数据库中的SQL(包括提交的和未提交的)全部重新做一遍
回滚 将没提交的SQL句从数据库中将老的镜像取出覆盖
释放资源 将前滚和回滚中使用到的资源释放
触发条件:
定期被唤醒或者被其他事务主动唤醒。
SMON在实例启动时,执行实例恢复,还负责清理不再使用的临时段,,“垃圾收集者”。在具有并行服务器选项的环境下,SMON对有故障CPU或实例进行实例恢复。SMON进程有规律地被唤醒,检查是否需要,或者其它进程发现需要时可以被调用。
(1)清理临时表空间:伴随这“真正”的临时表空间的出现,清理临时表空间的杂事已经减轻了,但它还没完全消失。例如,当建立一个索引,在创建期间分配给索引的扩展区被标志为TEMPORARY。如果Create Index会话因某些原因异常中断,SMON负责清理他们。其他操作创建的临时扩展区,SMON同样会负责。
(2) 接合空闲空间:如果你正使用数据字典管理表空间,SMON负责把那些在表空间中空闲的并且互相是邻近的extent接合成一个较大的空闲扩展区。这发生仅在带有默认的pctincrease设置为非零的存储子句的字典管理表空间。
(3) 把对于不可用文件的事务恢复成活动状态:它的角色类似在库启动期间。这时,因为文件不能用于恢复,SMON恢复在实例/崩溃恢复期间被跳过的故障事务。例如,文件可能已经在不可用或没装载的磁盘上。当文件变可用了,SMON将恢复它。
(4)执行一个RAC中故障节点的实例恢复:在一个oracle RAC配置中,当群集中的一个库实例失败(例如,实例正执行的机器故障了),一些群集中的其他节点将开启故障的实例的重做日志文件,为故障实例执行所有数据的恢复。
(5)清理OBJ\$: 是一个包含库中几乎每一个对象(表,索引,触发器,视图等等)的记录的行级数据字典表。许多次,这儿存在的记录代表已删对象,或代表不在这儿的对象,在oracle的信赖机制中被使用。SMON是删除这些不在被需要的行的进程。
(6)收缩回滚段:SMON将执行回滚段的自动收缩到它的optimal尺寸,如果它被设置。
(7)“脱机”回滚段:对于DBA来,让一个有active事务的回滚段,脱机或不可用,这事是可能的。Active事务正使用这脱机回滚段是可能的。在这情况下,回滚不是真正的脱机;它被标志为“悬挂offline”。在后台进程中,SMON将周期性尽力让它真正脱机,直到成功。
2.2.5.PMON
维护用户进程,进程监控器, 监控Server Process, 例如一个用户突然掉线了,但是该服务器进程还在服务器,PMON会隔一段时间把该进程清理掉并且释放PGA。
作用:
1.清理与实例非法断开的server procese残留的资源 非正常终止的用户进程产生的垃圾资源
2.负责重启以外死掉的调度器(网络监听中使用的)
3.将实例的信息注册到监听程序
触发条件: 定时被唤醒,其他进程也会主动唤醒它。
PMON在用户进程出现故障时执行进程恢复,负责清理内存储区和释放该进程所使用的资源。例:它要重置活动事务表的状态,释放封锁,将该故障的进程的ID从活动进程表中移去。PMON还周期地检查调度进程(DISPATCHER)和服务器进程的状态,如果已死,则重新启动(不包括有意删除的进程)。
PMON有规律地被呼醒,检查是否需要,或者其它进程发现需要时可以被调用。
2.2.6.RECO
用于分布式数据库的恢复
某个应用跨越多个数据库,需要都提交成功,事务才会成功,否则全部回滚。
RECO是在具有分布式选项时所使用的一个进程,自动地解决在分布式事务中的故障。一个结点RECO后台进程自动地连接到包含有悬而未决的分布式事务的其它数据库中,RECO自动地解决所有的悬而不决的事务。任何相应于已处理的悬而不决的事务的行将从每一个数据库的悬挂事务表中删去。
当数据库服务器的RECO后台进程试图建立同一远程服务器的通信,如果远程服务器是不可用或者网络连接不能建立时,RECO自动地在一个时间间隔之后再次连接。
RECO后台进程仅当在允许分布式事务的系统中出现,而且DISTRIBUTED C TRANSACTIONS参数是大于0。
2.2.7.ARCH
归档操作
作用:发生日志切换时把写满的联机日志文件拷贝到归档目录中。(LGWR写日志写到需要覆盖重写的时候,触发ARCH进程去转移日志文件,复制出去形成归档日志文件,以免日志丢失)
触发条件:日志切换时被LGWR唤醒。
设置:LOG_ARCHIVE_MAX_PROCESSES可以设置oracle启动的时候ARCH的个数。
ARCH将已填满的在线日志文件拷贝到指定的存储设备。当日志是为ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。
2.2.8.LCKn
仅适用于RAC数据库,最多可有10个进程(LCK0,LCK1,…,LCK9),用于实例间的封锁。
2.2.9.Dnnn
该进程允许用户进程共享有限的服务器进程(SERVER PROCESS)。没有调度进程时,每个用户进程需要一个专用服务进程(DEDICATEDSERVER PROCESS)。对于多线索服务器(MULTI-THREADED SERVER)可支持多个用户进程。如果在系统中具有大量用户,多线索服务器可支持大量用户,尤其在客户_服务器环境中。
在一个数据库实例中可建立多个调度进程。对每种网络协议至少建立一个调度进程。数据库管理员根据操作系统中每个进程可连接数目的限制决定启动的调度程序的最优数,在实例运行时可增加或删除调度进程。多线索服务器需要SQL*NET版本2或更后的版本。在多线索服务器的配置下,一个网络接收器进程等待客户应用连接请求,并将每一个发送到一个调度进程。如果不能将客户应用连接到一调度进程时,网络接收器进程将启动一个专用服务器进程。该网络接收器进程不是Oracle实例的组成部分,它是处理与Oracle有关的网络进程的组成部分。在实例启动时,该网络接收器被打开,为用户连接到Oracle建立一通信路径,然后每一个调度进程把连接请求的调度进程的地址给予它的接收器。当一个用户进程作连接请求时,网络接收器进程分析请求并决定该用户是否可使用一调度进程。如果是,该网络接收器进程返回该调度进程的地址,之后用户进程直接连接到该调度进程。有些用户进程不能调度进程通信(如果使用SQL*NET以前的版本的用户),网络接收器进程不能将此用户连接到一调度进程。在这种情况下,网络接收器建立一个专用服务器进程,建立一种合适的连接。
2.2.10.MMON
AWR主要的进程
作用:
1、收集AWR必须的统计数据,把统计数据写入磁盘。10g中保存在SYSAUX表空间中。
2、生成server–generated报警
每小时把shared pool中的统计信息写入磁盘,或者shared pool占用超过15%。
2.2.11.MMNL
轻量级的MMON
2.2.12.MMAN
自动内存管理
作用:每分钟都检查AWR性能信息,并根据这些信息来决定SGA组件最佳分布。
设置:
STATISTICS_LEVEL: 统计级别
SGA_TARGET: SGA总大小
2.2.13.CJQ0
CJQ0–数据库定时任务
2.2.14.RVWR
作用:为flashback database提供日志记录。把数据块的前镜像写入日志。
2.2.15.CTWR
作用:跟踪数据块的变化,把数据块地址记录到 change_tracking file文件中。RMAN的增量备份将使用这个文件来确定那些数据块发生了变化,并进行备份。
2.2.16.DBWR、CKPT、LGWR进程之间的关系
将内存数据块写入数据文件实在是一个相当复杂的过程,在这个过程中,首先要保证安全。所谓安全,就是在写的过程中,一旦发生实例崩溃,要有一套完整的机制能够保证用户已经提交的数据不会丢失;其次,在保证安全的基础上,要尽可能的提高效率。众所周知,I/O操作是最昂贵的操作,所以应该尽可能的将脏数据块收集到一定程度以后,再批量写入磁盘中。
直观上最简单的解决方法就是,每当用户提交的时候就将所改变的内存数据块交给DBWR,由其写入数据文件。这样的话,一定能够保证提交的数据不会丢失。但是这种方式效率最为低下,在高并发环境中,一定会引起I/O方面的争用。oracle当然不会采用这种没有扩展性的方式。oracle引入了CKPT和LGWR这两个后台进程,这两个进程与DBWR进程互相合作,提供了既安全又高效的写脏数据块的解决方法。
用户进程每次修改内存数据块时,都会在日志缓冲区(redo buffer)中构造一个相应的重做条目(redo entry),该重做条目描述了被修改的数据块在修改之前和修改之后的值。而LGWR进程则负责将这些重做条目写入联机日志文件。只要重做条目进入了联机日志文件,那么数据的安全就有保障了,否则这些数据都是有安全隐患的。LGWR是一个必须和前台用户进程通信的进程。LGWR承担了维护系统数据完整性的任务,它保证了数据在任何情况下都不会丢失。
LGWR将重做条目写入联机日志文件的情况分两种:
– 后台写(background write)
– 同步写(sync write)
触发后台写的条件有四个:
1)每隔三秒钟,LGWR启动一次;
2)在DBWR启动时,如果发现脏数据块所对应的重做条目还没有写入联机日志文件,则DBWR触发LGWR进程并等待LRWR写完以后才会继续;
3)重做条目的数量达到整个日志缓冲区的1/3时,触发LGWR;
4)重做条目的数量达到1MB时,触发LGWR。
而触发同步写的条件就一个:
当用户提交(commit)时,触发LGWR。
假如DBWR在写脏数据块的过程中,突然发生实例崩溃。我们已经知道,用户提交时,oracle是不一定会把提交的数据块写入数据文件的。那么实例崩溃时,必然会有一些已经提交但是还没有被写入数据文件的内存数据块丢失了。当实例再次启动时,oracle需要利用日志文件中记录的重做条目在buffer cache中重新构造出被丢失的数据块,从而完成前滚和回滚的工作,并将丢失的数据块找回来。于是这里就存在一个问题,就是oracle在日志文件中找重做条目时,到底应该找哪些重做条目?换句话说,应该在日志文件中从哪个起点开始往后应用重做条目?注意,这里所指的日志文件可能不止一个日志文件。
因为oracle需要随时预防可能的实例崩溃现象,所以oracle在数据库的正常运行过程中,会不断的定位这个起点,以便在不可预期的实例崩溃中能够最有效的保护并恢复数据。同时,这个起点的选择非常有讲究。首先,这个起点不能太靠前,太靠前意味着要处理很多的重做条目,这样会导致实例再次启动时所进行的恢复的时间太长;其次,这个起点也不能太靠后,太靠后说明只有很少的脏数据块没有被写入数据文件,也就是说前面已经有很多脏数据块被写入了数据文件,那也就意味着只有在DBWR启动的很频繁的情况下,才能使得buffer cache中所残留的脏数据块的数量很少。但很明显,DBWR启动的越频繁,那么所占用的写数据文件的I/O就越严重,那么留给其他操作(比如读取buffer cache中不存在的数据块等)的I/O资源就越少。这显然也是不合理的。
从这里也可以看出,这个起点实际上说明了,在日志文件中位于这个起点之前的重做条目所对应的在buffer cache中的脏数据块已经被写入了数据文件,从而在实例崩溃以后的恢复中不需要去考虑。而这个起点以后的重做条目所对应的脏数据块实际还没有被写入数据文件,如果在实例崩溃以后的恢复中,需要从这个起点开始往后,依次取出日志文件中的重做条目进行恢复。考虑到目前的内存容量越来越大,buffer cache也越来越大,buffer cache中包含几百万个内存数据块也是很正常的现象的前提下,如何才能最有效的来定位这个起点呢?
为了能够最佳的确定这个起点,oracle引入了名为CKPT的后台进程,通常也叫作检查点进程(checkpoint process)。这个进程与DBWR共同合作,从而确定这个起点。同时,这个起点也有一个专门的名字,叫做检查点位置(checkpoint position)。
oracle为了在检查点的算法上更加的具有可扩展性(也就是为了能够在巨大的buffer cache下依然有效工作),引入了检查点队列(checkpoint queue),该队列上串起来的都是脏数据块所对应的buffer header。
DBWR每次写脏数据块时,也是从检查点队列上扫描脏数据块,并将这些脏数据块实际写入数据文件的。当写完以后,DBWR会将这些已经写入数据文件的脏数据块从检查点队列上摘下来。这样即便是在巨大的buffer cache下工作,CKPT也能够快速的确定哪些脏数据块已经被写入了数据文件,而哪些还没有写入数据文件,显然,只要在检查点队列上的数据块都是还没有写入数据文件的脏数据块。
为了更加有效的处理单实例和多实例(RAC)环境下的表空间的检查点处理,比如将表空间设置为离线状态或者为热备份状态等,oracle还专门引入了文件队列(file queue)。文件队列的原理与检查点队列是一样的,只不过每个数据文件会有一个文件队列,该数据文件所对应的脏数据块会被串在同一个文件队列上;同时为了能够尽量减少实例崩溃后恢复的时间,oracle还引入了增量检查点(incremental checkpoint),从而增加了检查点启动的次数。
如果每次检查点启动的间隔时间过长的话,再加上内存很大,可能会使得恢复的时间过长。因为前一次检查点启动以后,标识出了这个起点。然后在第二次检查点启动的过程中,DBWR可能已经将很多脏数据块已经写入了数据文件,而假如在第二次检查点启动之前发生实例崩溃,导致在日志文件中,所标识的起点仍然是上一次检查点启动时所标识的,导致oracle不知道这个起点以后的很多重做条目所对应的脏数据块实际上已经写入了数据文件,从而使得oracle在实例恢复时再次重复的处理一遍,效率低下,浪费时间。
上面说到了有关CKPT的两个重要的概念:检查点队列(包括文件队列)和增量检查点。
检查点队列在我们上面转储出来的buffer header里可以看到,就是类似ckptq: [65abceb4,63bec66c]和fileq: [65abcfbc,63becd10]的结构,记录的同样都是指向前一个buffer header和指向后一个buffer header的指针。这个队列上面挂的也是脏数据块对应的buffer header链表,但是它与LRUW链表不同。检查点队列上的buffer header是按照数据块第一次被修改的时间的先后顺序来排列的。越早修改的数据块的buffer header排在越前面,同时如果一个数据块被修改了多次的话,在该链表上也只出现一次。而且,检查点队列上的buffer header还记录了脏数据块在第一次被修改时,所对应的重做条目在重做日志文件中的地址,也就是RBA(Redo Block Address)。同样在转储出来的buffer header中可以看到类似LRBA: [0xe9.229.0]的结构,这就是RBA,L表示Low,也就是第一次被修改的时候的RBA。但是注意,在检查点队列上的buffer header,并不表示一定会有一个对应的RBA,比如控制文件重做(controlfile redo)就不会有相应的RBA。对于没有对应RBA的buffer header来说,在检查点队列上始终处于最尾端,其优先级永远比有RBA的脏数据块的buffer header要低。8i以前,每个working set都有一个检查点队列以及多个文件队列(因为一个数据文件对应一个文件队列);而从8i开始,每个working set都有两个检查点队列,每个检查点都会由checkpoint queue latch来保护。
增量检查点是从8i开始出现的,是相对于8i之前的完全检查点(complete checkpoint)而言的。完全检查点启动时,会标识出buffer cache中所有的脏数据块,然后启动DBWR进程将这些脏数据块写入数据文件。8i之前,日志切换的时候会触发完全检查点。
而到了8i及以后,完全检查点只有在两种情况下才会被触发:
1)发出命令:alter system checkpoint;
2)除了shutdown abort以外的正常关闭数据库。
注意,这个时候,日志切换不会触发完全检查点,而是触发增量检查点。8i所引入的增量检查点每隔三秒钟或发生日志切换时启动。它启动时只做一件事情:找出当前检查点队列上的第一个buffer header,并将该buffer header中所记录的LRBA(这个LRBA也就是checkpoint position了)记录到控制文件中去。如果是由日志切换所引起的增量检查点,则还会将checkpoint position记录到每个数据文件头中。也就是说,如果这个时候发生实例崩溃,oracle在下次启动时,就会到控制文件中找到这个checkpoint position作为在日志文件中的起点,然后从这个起点开始向后,依次取出每个重做条目进行处理。
上面所描述的概念,用一句话来概括,其实就是DBWR负责写检查点队列上的脏数据块,而CKPT负责记录当前检查点队列的第一个数据块所对应的的重做条目在日志文件中的地址。从这个意义上说,检查点队列比LRUW还要重要,LRUW主要就是区分出哪些数据块是脏的,不可以被重用的。而到底应该写哪些脏数据块,写多少脏数据块,则还是要到检查点队列上才能确定的。
我们用一个简单的例子来描述这个过程。假设系统中发生了一系列的事务,导致日志文件如下所示:
事务号 数据文件号 block号 行号 列 值 RBA
T1 8 25 10 1 10 101
T1 7 623 12 2 a 102
T3 8 80 56 3 b 103
T3 9 98 124 7 e 104
T5 7 623 13 3 abc 105
Commit SCN# timestamp 106
T123 8 876 322 10 89 107
这时,对应的检查点队列则类似如下图六所示。我们可以看到,T1事务最先发生,所以位于检查点

队列的首端,而事务T123最后发生,所以位于靠近尾端的地方。同时,可以看到事务T1和T5都更新了7号数据文件的623号数据块。而在检查点队列上只会记录该数据块的第一次被更新时的RBA,也就是事务T1对应的RBA102,而事务T5对应的RBA105并不会被记录。因为根本就不需要在检查点队列上记录。当DBWR写数据块的时候,在写RBA102时,自然就把RBA105所修改的内容写入数据文件了。日志文件中所记录的提交标记也不会体现在检查点队列上,因为提交本身只是一个标记而已,不会涉及到修改数据块。
这时,假设发生三秒钟超时,于是增量检查点启动。增量检查点会将检查点队列的第一个脏数据块所对应的RBA记录到控制文件中去。在这里,也就是RBA101会作为checkpointposition记录到控制文件中。
然后,DBWR后台进程被某种条件触发而启动。DBWR根据一系列参数及规则,计算出应该写的脏数据块的数量,从而将RBA101到RBA107之间的这5个脏数据块写入数据文件,并在写完以后将这5个脏数据块从检查点队列上摘除,而留下了4个脏数据块在检查点队列上。如果在写这5个脏数据块的过程中发生实例崩溃,则下次实例启动时,oracle会从RBA101开始应用日志文件中的重做条目。
而在9i以后,在DBWR写完这5个脏数据块以后,还会在日志文件中记录所写的脏数据块的块号。如下图所示。这主要是为了在恢复时加快恢复的速度。

这时,又发生三秒钟超时,于是增量检查点启动。这时它发现checkpointposition为RBA109,于是将RBA109写入控制文件。如果接着发生实例崩溃,则oracle在下次启动时,就会从RBA109开始应用日志。
2.3.SGA的相关视图
2.3.1.SGA视图
v\$sga: V$SGA这个视图包括了SGA的的总体情况,只包含两个字段:name(SGA内存区名字)和value(内存区的值,单位为字节)。它的结果和show sga的结果一致。
v\$sgastat: 10g之前用于查看各SGA组件大小。VSGAINFO的作用基本和VSGA一样,只不过把Variable size的部分更细化了一步
v\$sgainfo: 10g及10g之后才有的。用于查看SGA组件大小更简便。
v\$sga_dynamic_components: 这个视图记录了SGA各个动态内存区的情况,它的统计信息是基于已经完成了的,针对SGA动态内存区大小调整的操作。
v\$sga_dynamic_free_memory: 这个视图只有一个字段就是用来表示SGA当前可以用于调整各个组件的剩余大小。
v\$sga_target_advice: 该视图可用于建议SGA大小设置是否合理。
SELECT a.sga_size, --SGA期望大小
a.sga_size_factor, --期望SGA大小与实际SGA大小的百分比
a.estd_db_time, --SGA设置为期望的大小后,其dbtime消耗期望的变化
a.estd_db_time_factor ,--修改SGA为期望大小后,dbtime消耗的变化与修改前的变化百分比
a.estd_physical_reads --修改前后物理读的差值
FROM v$sga_target_advice a;
查看当前的SGA大小:
show parameter sga_max_size;
修改SGA值:
alter system set sga_max_size=864M scope=spfile;--要重启数据库
alter system set sga_target=864M;
2.3.2.Share Pool视图
2.3.2.1.v$shared_pool_advice
可用于建议共享池大小的设置
select shared_pool_size_for_estimate sp, --估算的共享池大小(m为单位)
shared_pool_size_factor spf, --估算的共享池大小与当前大小比
estd_lc_memory_objects elm, --估算共享池中库缓存的内存对象数
estd_lc_size el, --估算共享池中用于库缓存的大小(M为单位)
estd_lc_time_saved elt, --估算将可以节省的解析时间。这些节省的时间来自于请求处理一个对象时,重新将它载入共享池的时间消耗和直接从库缓存中读取的时间消耗的差值。
estd_lc_time_saved_factor as elts,--估算的节省的解析时间与当前节省解析时间的比
estd_lc_memory_object_hits as elmo --估算的可以直接从共享池中命中库缓存的内存对象的命中次数
from v$shared_pool_advice;
2.3.2.2.v$shared_pool_reserved
存放了共享池保留区的统计信息
select
--以下字段只有当参数SHARED_POOL_RESERVED_SIZE设置了才有效
a.FREE_SPACE, --保留区的空闲空间数。
a.AVG_FREE_SIZE, --保留区的空闲空间平均数。
a.FREE_COUNT, --保留区的空闲内存块数
a.MAX_FREE_SIZE, --最大的保留区空闲空间数
a.USED_SPACE, --保留区使用空间数
a.AVG_USED_SIZE, --保留区使用空间平均数
a.USED_COUNT, --保留区使用内存块数
a.MAX_USED_SIZE, --最大保留区使用空间数
a.REQUESTS, --请求再保留区查找空闲内存块的次数
a.REQUEST_MISSES,--无法满足查找保留区空闲内存块请求,需要从LRU列表中清出对象的次数
a.LAST_MISS_SIZE,--请求的内存大小,这次请求是最后一次需要从LRU列表清出对象来满足的请求
--以下字段无论参数SHARED_POOL_RESERVED_SIZE是否设置了都有效
a.MAX_MISS_SIZE, --所有需要从LRU列表清出对象来满足的请求中的内存最大大小
a.REQUEST_FAILURES, --没有内存能满足的请求次数(导致4031错误的请求)
a.LAST_FAILURE_SIZE, --没有内存能满足的请求所需的内存大小(导致4031错误的请求)
a.ABORTED_REQUEST_THRESHOLD,--不清出对象的情况下,导致4031错误的最小请求大小
a.ABORTED_REQUESTS, --不清出对象的情况下,导致4031错误的请求次数
a.LAST_ABORTED_SIZE --不清出对象的情况下,最后一次导致4031错误的请求大小
from V$SHARED_POOL_RESERVED a
可以根据后面4个字段值来决定如何设置保留区的大小以避免4031错误的发生
2.3.2.3.v$db_object_cache
显示了所有被缓存在library cache中的对象,包括表、索引、簇、同义词、PL/SQL存储过程和包以及触发器
SELECT o.owner, --对象所有者
o.name, --对象名称
o.db_link, --如果对象存在db link的话,db link的名称
o.namespace,--库缓存的对象命名空间
o.type, --对象类型
o.sharable_mem,--对象消耗的共享池中的共享内存
o.loads, --对象被载入次数。即使对象被置为无效了,这个数字还是会增长
o.executions, --对象执行次数,但本视图中没有被使用。可以参考视图vsqlarea中执行次数
o.locks, --当前锁住这个对象的用户数(如正在调用、执行对象)
o.pins, --当前pin住这个对象的用户数(如正在编译、解析对象)
o.kept, -- 对象是否被保持,即调用了DBMS_SHARED_POOL.KEEP来永久将对象pin在内存中。(YES | NO)
o.child_latch, --正在保护该对象的子latch的数量
o.invalidations --无效数
FROM vdb_object_cache o;
2.3.2.4.vsql vsqlarea v$sqltext
SELECT s.sql_text, --游标中SQL语句的前1000个字符
s.sharable_mem, --被游标占用的共享内存大小。如果存在多个子游标,则包含所有子游标占用的共享内存大小。
s.persistent_mem,--用于打开这条语句的游标的生命过程中的固定内存大小。如果存在多个子游标,则包含所有子游标生命过程中的固定内存大小。
s.runtime_mem, --打开这条语句的游标的执行过程中的固定内存大小。如果存在多个子游标,则包含所有子游标执行过程中的固定内存大小。
s.sorts, --所有子游标执行语句所导致的排序次数
s.version_count, --缓存中关联这条语句的子游标数
s.loaded_versions, --缓存中载入了这条语句上下文堆(kgl heap 6)的子游标数
s.open_versions, --打开语句的子游标数
s.users_opening, --打开这些子游标的用户数
s.fetches, --SQL语句的fetch数
s.executions, --所有子游标的执行这条语句次数
s.px_servers_executions,
s.end_of_fetch_count,
s.users_executing, --通过子游标执行这条语句的用户数
s.loads, --语句被载入和重载入的次数
s.first_load_time, --语句被第一次载入的时间戳
s.invalidations, --所有子游标的无效次数
s.parse_calls, --所有子游标对这条语句的解析调用次数
s.disk_reads, --所有子游标运行这条语句导致的读磁盘次数
s.direct_writes,
s.buffer_gets, --所有子游标运行这条语句导致的读内存次数
s.application_wait_time,
s.concurrency_wait_time,
s.cluster_wait_time,
s.user_io_wait_time,
s.plsql_exec_time,
s.java_exec_time,
s.rows_processed, --这条语句处理的总记录行数
s.command_type, --oracle命令类型代号
s.optimizer_mode, --执行这条的优化器模型
s.optimizer_cost,
s.optimizer_env,
s.optimizer_env_hash_value,
s.parsing_user_id, --第一次解析这条语句的用户的id
s.parsing_schema_id, --第一次解析这条语句所用的schema的id
s.parsing_schema_name,
s.kept_versions, --所有被dbms_shared_pool包标识为保持(keep)状态的子游标数
s.address, --指向语句的地址
s.hash_value, --这条语句在library cache中hash值
s.old_hash_value,
s.plan_hash_value,
s.module, --在第一次解析这条语句是通过调用dbms_application_info.set_module设置的模块名称
s.module_hash, --模块的hash值
s.action, --在第一次解析这条语句是通过调用dbms_application_info.set_action设置的动作名称
s.action_hash, --动作的hash值
s.serializable_aborts, --所有子游标的事务无法序列化的次数,这会导致ora-08177错误
s.outline_category,
s.cpu_time,
s.elapsed_time,
s.outline_sid,
s.last_active_child_address,
s.remote,
s.object_status,
s.literal_hash_value,
s.last_load_time,
s.is_obsolete, --游标是否被废除(y或n)。当子游标数太多了时可能会发生
s.child_latch, --包含此游标的子latch数
s.sql_profile,
s.program_id,
s.program_line#,
s.exact_matching_signature,
s.force_matching_signature,
s.last_active_time,
s.bind_data
FROM v$sqlarea s;
查看当前会话所执行的语句以及会话相关信息:
select a.sid || '.' || a.SERIAL#,
a.username,
a.TERMINAL,
a.program,
s.sql_text
from vsession a, vsqlarea s
where a.sql_address = s.address(+)
and a.sql_hash_value = s.hash_value(+)
order by a.username, a.sid;
2.3.2.5.v$sql_plan
视图V$SQL_PLAN包含了library cache中所有游标的执行计划。
SELECT p.address, --当前cursor父句柄位置
p.hash_value, --在library cache中父语句的hash值
p.operation, --在各步骤执行内部操作的名称,例如:table access
p.options, --描述列operation在操作上的变种,例如:full
p.object_node,--用于访问对象的数据库链接database link 的名称对于使用并行执行的本地查询该列能够描述操作中输出的次序
p.object#, --表或索引对象数量
p.object_owner,--对于包含有表或索引的架构schema 给出其所有者的名称
p.object_name, --表或索引名
p.optimizer, --执行计划中首列的默认优化模式
p.id, --在执行计划中分派到每一步的序号
p.parent_id, --对id 步骤的输出进行操作的下一个执行步骤的id
p.depth, --业务树深度(或级)。
p.cost, --cost-based方式优化的操作开销的评估,如果语句使用rule-based方式,本列将为空
p.cardinality, --根据cost-based方式操作所访问的行数的评估
p.bytes, --根据cost-based方式操作产生的字节的评估
p.other_tag, --其它列的内容说明
p.partition_start, --范围存取分区中的开始分区
p.partition_stop, --范围存取分区中的停止分区
p.partition_id, --计算partition_start和partition_stop这对列值的步数
p.other, --其它信息即执行步骤细节,供用户参考
p.distribution, --为了并行查询,存储用于从生产服务器到消费服务器分配列的方法
p.cpu_cost, --根据cost-based方式cpu操作开销的评估。如果语句使用rule-based方式,本列为空
p.io_cost, --根据cost-based方式i/o操作开销的评估。如果语句使用rule-based方式,本列为空
p.temp_space, --ost-based方式操作(sort or hash-join)的临时空间占用评估。如果语句使用rule-based方式,本列为空
p.access_predicates, --指明以便在存取结构中定位列,例如,在范围索引查询中的开始或者结束位置
p.filter_predicates, --在生成数据之前即指明过滤列
FROM v$sql_plan p;
通过结合vsqlarea可以查出library cache中所有语句的查询计划。先从vsqlarea中得到语句的地址,然后在由v$sql_plan查出它的查询计划:
SELECT LPAD(' ', 2 * (level - 1)) || operation "Operation",
options "Options",
DECODE(to_char(id),
'0',
'Cost=' || nvl(to_char(position), 'n/a'),
object_name) "Object Name",
optimizer
FROM v$sql_plan a
START WITH address = '4F6E452C'
AND id = 0
CONNECT BY PRIOR id = a.parent_id
AND PRIOR a.address = a.address
AND PRIOR a.hash_value = a.hash_value;
2.3.2.6.Share Pool Size
--查看共享池各参数
SELECT name, (bytes)/1024/1024 M FROM vsgastat WHERE pool='shared pool' ORDER BY a DESC;
--查看Shared Pool Size大小
SELECT name, bytes/1024/1024 FROM vsgainfo WHERE name='Shared Pool Size';
--修改Shared Pool Size大小
ALTER SYSTEM SET SHARED_POOL_SIZE = 320M;
2.3.3.Library Cache视图
2.3.3.1.v$librarycache
这个视图包含了关于library cache的性能统计信息,对于共享池的性能调优很有帮助。
SELECT l.namespace, -- library cache的命名空间
l.gets, --请求GET该命名空间中对象的次数
l.gethits, --请求GET并在内存中找到了对象句柄的次数(锁定命中)
l.gethitratio, --请求GET的命中率
l.pins, --读取或执行该命名中对象的次数
l.pinhits, --库对象的所有元数据在内存中被找到的次数(pin命中)
l.pinhitratio, --Pin命中率
l.reloads, --Pin请求需要从磁盘中载入对象的次数
l.invalidations, --命名空间中的非法对象(由于依赖的对象被修改所导致)数
l.dlm_lock_requests, --GET请求导致的实例锁的数量
l.dlm_pin_requests, --PIN请求导致的实例锁的数量
l.dlm_pin_releases, --请求释放PIN锁的次数
l.dlm_invalidation_requests,--GET请求非法实例锁的次数
l.dlm_invalidations --从其他实例那的得到的非法pin数
FROM v$librarycache l;
2.3.3.2.v$library_cache_memory
select a.lc_namespace, -- Library cache命名空间
a.lc_inuse_memory_objects, --存在与库高速缓存的对象数目
a.lc_inuse_memory_size, --存在库高速缓存对象大小(M)
a.lc_freeable_memory_objects,--空闲的库高速缓存数量
a.lc_freeable_memory_size --空闲的库高速缓存大小
from v$library_cache_memory a;
通过此视图可了解目前在库高速缓存中的对象及可继续存放的数目。
2.3.3.3.Library Cache 命中率
select sum(pinhits)/sum(pins) from vlibrarycache;
--考虑了reloads
select (sum(pins-reloads))/sum(pins) "Library cache" from vlibrarycache;
当命中率小于99%或未命中率大于1%时,说明系统中硬解析过多,要做系统优化(增加Shared Pool、使用绑定变量、修改cursor_sharing等措施。
* 不能单看库高速缓存命中率的大小,结合vlibrarycache中的reloads来分析。如果reloads值比较大,表明许多SQL语句在老化退出后又被重新装入库池。若SQL语句是因为没有使用绑定变量导致reloads值变大,可修改该SQL采用绑定变量的方式;若SQL语句无法使用绑定变量,则可考虑将SQL语句用dbms_shared_pool中的keep过程将需要钉在库池中的对象钉住,用unkeep过程释放。
sys.dbms_shared_pool.keep(name => ,flag => )–Name是需要固定的对象的名称,flag是要固定的对象的类型
* dbms_shared_pool说明
* 默认下该包没安装,可利用ORACLE_HOME/rdbms/admin目录下的dbmspool.sql脚本来安装(sys用户执行),其他用户需要sys用户授权后才可使用。
* 对于固定在共享池中的对象,当共享池空间不足的时候,ORACLE不会释放这些对象以获取创建新的项目所需要的空间,甚至刷新共享池的时候,这些对象也不会被清除。
* dbms_shared_pool包的keep和unkeep过程中的flag的取值:
P package/procedure/function
Q sequence
R trigger
T type
JS java source
JC java class
JR java resource
JD java shared data
C CURSOR
固定SQL的keep示例:
dbms_shared_pool.keep(‘address, hash_value’, ‘C’)
其中SQL语句的ADDRESS和HASH_VALUE可以在V$SQLAREA中找到;
对于函数、过程和包示例如下:
dbms_shared_pool.keep(‘name’, ‘P’)
如果采用该过程将程序固定到共享池后,刷新缓冲区(alter system flush shared_pool)也不会清除,必须使用unkeep过程清除。
2.3.4.Library Cache Tuning
优化库高速缓存的目的是重用以前分析过的或执行过的代码。最简单的方法就是使用绑定变量,减少硬分析。
2.3.4.1.cursor_sharing
游标共享cursor_sharing参数的使用,使之使用绑定变量
cursor_sharing参数有三个值:
– SIMILAR:只在认为绑定变量不会对优化产生负面影响时才使用绑定变量。
– FORCE: 强制在所有情况下使用绑定变量。
– EXACT: 默认情况下为该值
ORACLE建议使用CURSOR_SHARING=SIMILAR,因为使用CURSOR_SHARING=FORCE有可能使执行计划变坏。但实际上CURSOR_SHARING=FORCE
对执行计划的好处要远远大于坏处。在观察到由于不使用绑定变量而导致大量硬分析时,通过把默认的CURSOR_SHARING=EXACT改成CURSOR_SHARING=FORCE
可极大的改善性能。可在init.ora或spfile中更改这个参数,也可使用alter system 或alter session 动态的执行更改。
2.3.4.2.硬分析语句
查看硬分析语句
select s.sid, s.value "execute counts", t.value "hard parse"
from vsesstat s, vsesstat t
where s.sid = t.sid
and s.statistic# in
(select statistic# from vstatname where name = 'execute count')
and t.statistic# in
(select statistic# from vstatname where name = 'parse count (hard)')
order by t.value desc;
将硬分析语句采用绑定变量方式或者直接将该SQL固定到缓存中。
2.3.4.3.软分析语句
通过以下措施可将软分析保持为最低:
* 设置 SESSION_CACHED_CURSORS
SESSION_CACHED_CURSORS,就是说的是一个session可以缓存多少个cursor,让后续相同的SQL语句不再打开游标,从而避免软解析的过程来提高性能。 (绑定变量是解决硬解析的问题),软解析同硬解析一样,比较消耗资源.所以这个参数非常重要。
当一个cursor关闭之后,oracle会检查这个cursor的request次数是否超过3次,如果超过了三次,就会放入session cursor cache list的MRU端, 这样在下次打算parse一个sql时,它会先去pga内搜索session cursor cache list,如果找到那么会把这个cursor脱离list,然后当关闭的时候再把这个 cursor加到MRU端. session_cached_cursor提供了快速软分析的功能,提供了比soft parse更高的性能。session cursor cache的管理也是使用LRU。
session_cached_cursors这个参数是控制session cursor cache的大小的。session_cached_cursors定义了session cursor cache中存储的cursor的个数。这个值越大,则会消耗的内存越多。
另外检查这个参数是否设置的合理,可以从两个statistic来检查。
SQL> select name, value from vsysstat where name like '%cursor%';
NAME VALUE
---------------------------------------------------------------- ----------
opened cursors cumulative 17889
opened cursors current 34
session cursor cache hits 16481
session cursor cache count 777
cursor authentications 294
SQL>select name, value from vsysstat where name like '%parse%';
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 331
parse time elapsed 2021
parse count (total) 12134
parse count (hard) 1355
parse count (failures) 3
--session cursor cache hits 和parse count(total) 就是总的parse次数中
--在session cursor cache中找到的次数,所占比例越高,性能越好。
--如果比例比较低,并且有剩余内存的话,可以考虑加大该参数。
--open_cursors 是充许打开的游标的数量
--session_cached_cursors 是充许放入缓存的游标的数量
- 在应用程序预编译器中设置 HOLD_CURSOR
HOLD_CURSOR=YES|NO;缺省值为NO。
当执行SQL操纵语句时,其相关的光标被连到光标高速缓冲存储器中的一项上,该项又被依次连接到ORACLE专用的SQL区域上,该区域存储处理该语句 所需的信息。
当HOLD_CURSOR=NO时,在ORACLE执行完SQL语句或关闭光标后,预编译程序直接撤去该链,释放分析块和分配给专用SQL区域的内存,并把该链标为可再使用。这时另一个SQL语句就又可使用该链来指向光标高速缓冲存储器的项了。
当HOLD_CURSOR=YES时,该链被保留,预编译程序不再使用它。这对经常使用的SQL语句是有用的。
如果RELEASE_CURSOR=no(默认 no),HOLD_CURSOR=yes(默认为no),当ORACLE执行完SQL语句,为private SQL AREA分配的内存空间被保留,cursor和private SQL AREA之间的link也被保留,预编译程序不再使用它,同样可以通过这个指针直接在private SQL AREA获得语句。
RELEASE_CURSOR=YES优先于HOLD_CURSOR=YES;
HOLD_CURSOR=NO优先于RELEASE_CURSOR=NO。 - 设置 CURSOR_SPACE_FOR_TIME 默认为false 废弃
该参数本意是通过设置为true可以保证游标在关闭前不能重新分配游标。该参数已废弃。
2.3.4.4.修改share_pool大小
查看库缓存命中率大小,若大小,可试着加大share_pool。
2.3.5.Database Buffer Cache视图
show parameter db_cache_size
- 修改DB_CACHE相关参数
alter system set db_cache_size=100m; --默认池(所有段块一般都在这个池)
alter system set db_keep_cache_size=12m; --保持池(访问非常频繁的段可放置该池,防止在默认池老化)
alter system set db_recycle_cace_size=16m; --回收池(访问很随机的大段一般可放于该池)
- 查看db_cache命中率
select name, value
from v$sysstat
where name in ('db block gets from cache', 'consistent gets from cache', 'physical reads cache');
db_cache命中率算法
db_cache命中率=1-(physical reads cache/(db block gets from cache+consistent gets from cache)) --命中率应该在90%以上,否则需要增加数据缓冲区的大小
- 采用v$buffer_pool_statistics视图推导缓冲区高速缓存的命中率
SELECT name,
physical_reads,
db_block_gets,
consistent_gets,
1 - (physical_reads / (db_block_gets + consistent_gets)) Hitratio
FROM v$buffer_pool_statistics;
- v$db_cache_advice视图用于建议缓冲区高速缓存设置
SELECT size_for_estimate "size",
buffers_for_estimate "buffers",
estd_physical_read_factor "read_factor",
estd_physical_reads "reads"
FROM vdb_cache_advice
WHERE NAME = 'DEFAULT'
AND block_size =
(SELECT VALUE FROM vparameter WHERE NAME = 'db_block_size')
对于常用的小表可以将其保存在keep池,这样就不会因为缓冲区满而被清出。
alter table table_name storage(buffer_pool keep)
2.3.6.Redo Log Buffer视图
Redo Log Buffer是SGA中一段保存数据库修改信息的缓存。这些信息被存储在重做条目(Redo Entry)中.重做条目中包含了由于INSERT、UPDATE、DELETE、CREATE、ALTER或DROP所做的修改操作而需要对数据库重新组织或重做的必须信息。在必要时,重做条目还可以用于数据库恢复。
重做条目是Oracle数据库进程从用户内存中拷贝到Redo Log Buffer中去的。重做条目在内存中是连续相连的。后台进程LGWR负责将Redo Log Buffer中的信息写入到磁盘上活动的重做日志文件(Redo Log File)或文件组中去的。
参数LOG_BUFFER决定了Redo Log Buffer的大小。它的默认值是512K(一般这个大小都是足够的),最大可以到4G。当系统中存在很多的大事务或者事务数量非常多时,可能会导致日志文件IO增加,降低性能。这时就可以考虑增加LOG_BUFFER。
但是,Redo Log Buffer的实际大小并不是LOB_BUFFER的设定大小。为了保护Redo Log Buffer,oracle为它增加了保护页(一般为11K):
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ----------------
log_buffer integer 7024640
SQL> select * from v$sgastat where name = 'log_buffer';
POOL NAME BYTES
------------ -------------------------- ----------
log_buffer 7135232
修改大小
alter system set log_buffer=3500000 scope=spfile;
2.3.7.Large Pool视图
用于减轻共享池的负担,当有大规模的I/O操作或者备份恢复操作,或者是共享服务器进程。
show parameter large_pool_size;
大池是SGA中的一块可选内存池,根据需要时配置。
在以下情况下需要配置大池:
– 用于共享服务(Shared Server MTS方式中)的会话内存和Oracle分布式事务处理的Oracle XA接口
– 使用并行查询(Parallel Query Option PQO)时
– IO服务进程
– Oracle备份和恢复操作(启用了RMAN时)
通过从大池中分配会话内存给共享服务、Oracle XA或并行查询,oracle可以使用共享池主要来缓存共享SQL,以防止由于共享SQL缓存收缩导致的性能消耗。此外,为Oracle备份和恢复操作、IO服务进程和并行查询分配的内存一般都是几百K,这么大的内存段从大池比从共享池更容易分配得到。
参数LARGE_POOL_SIZE设置大池的大小(alter system set large_pool_size=10M)。大池是属于SGA的可变区(Variable Area)的,它不属于共享池。
对于大池的访问,是受到 large memory latch 保护的。大池中只有两种内存段:空闲(free)和可空闲(freeable)内存段。它没有可重建(recreatable)内存段,因此也不用LRU链表来管理(这和其他内存区的管理不同)。大池最大大小为4G。
为了防止大池中产生碎片,隐含参数 _LARGE_POOL_MIN_ALLOC 设置了大池中内存段的最小大小,默认值是16K(同样,不建议修改隐含参数)。
此外,large pool是没有LRU链表的。
2.3.8.Java Pool视图
使用Java语言,java命令分析时需要使用。
show parameter java_pool_size;
Java池也是SGA中的一块可选内存区,它也属于SGA中的可变区。
Java池的内存是用于存储所有会话中特定Java代码和JVM中数据。Java池的使用方式依赖与Oracle服务的运行模式。
Java池的大小由参数JAVA_POOL_SIZE设置(alter system set java_pool_size=10M;)。Java Pool最大可到1G。
在Oracle 10g以后,提供了一个新的建议器——Java池建议器——来辅助DBA调整Java池大小。建议器的统计数据可以通过视图V$JAVA_POOL_ADVICE来查询。
2.3.9.Stream Pool视图
流池是Oracle 10g中新增加的。是为了增加对流(流复制是Oracle 9iR2中引入的一个非常吸引人的特性,支持异构数据库之间的复制。10g中得到了完善)的支持。
流池也是可选内存区,属于SGA中的可变区。它的大小可以通过参数 STREAMS_POOL_SIZE 来指定。如果没有被指定,oracle会在第一次使用流时自动创建。如果设置了SGA_TARGET参数,Oracle会从SGA中分配内存给流池;
如果没有指定SGA_TARGET,则从buffer cache中转换一部分内存过来给流池。转换的大小是共享池大小的10%。
Oracle同样为流池提供了一个建议器——流池建议器。建议器的统计数据可以通过视图V\$STREAMS_POOL_ADVICE查询。
3.PGA
每个服务进程私有的内存区域,包含如下结构:
1)Private SQL area:包含绑定信息、运行时的内存结构。每个发出sql语句的会话,都有一个private SQL area(私有SQL区)
2)Session memory:为保存会话中的变量以及其他与会话相关的信息,而分配的内存区。
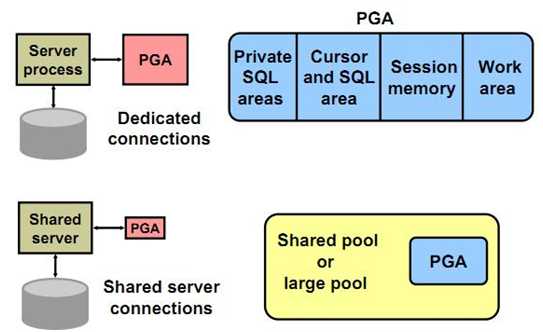
3.1.Server Process
当用户(客户端)要连接Oracle数据库时, Oracle就会创建1个session(会话),并且在服务器上创建1个专门处理这个session的进程,就是服务器进程。
每当1个新用户创建1个新的连接到数据库,Oracle都会对应创建1个服务器进程。
对应Server Process, Oracle会在服务器上对每一个Server Process分配一定大小的内存,也就是PGA, 有几个session就会有几个对应的PGA, 所以服务器对内存需求是很大的。
查看当前使用的总PGA大小:
select sum(pga_userd_mem) from v$process
用户在客户端输入若干条SQL语句,有读和写的动作。这条语句通过session传输, 服务器通过Server Process接收。
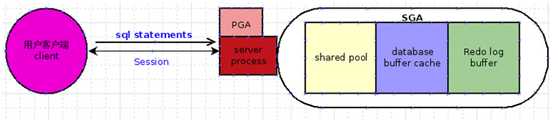
以客户端执行一条SQL语句为例:
1. sql语句通过网络到达实例,server process接收SQL语句
2. server process去shared pool 找SQL语句和执行计划,如果没有,解析SQL语句。生成执行计划要访问许多数据库对象, 是一个比较消耗服务器资源(CPU, IO, Memory)的动作。
3. server process根据执行计划去database buffer cache找相关的数据,如果没有才到dbf中取出数据放到database buffer cache再返回给用户
4. 若需要修改数据,server process读出数据到buffer cache中,在内存中修改数据,修改完成后返回给用户。
所谓逻辑读,就是从缓存里读取数据;而物理读,也就是从磁盘(数据文件)里读取数据。
缓存命中率 = 逻辑读次数 / (逻辑读次数+物理读次数)
这个比率越接近1越好,当然命中率并不是数据库健康的唯一指标,因为当逻辑读十分巨大的时候, 即使物理读也很大,所以有时要关心每秒物理读(tps)。
server process处理的快慢直接影响用户体验。
ORACLE进程又分为两类:服务器进程和后台进程。
服务器进程用于处理连接到该实例的用户进程的请求。当应用和ORACELE是在同一台机器上运行,而不再通过网络,一般将用户进程和它相应的服务器进程组合成单个的进程,可降低系统开销。然而,当应用和ORACLE运行在不同的机器上时,用户进程经过一个分离服务器进程与ORACLE通信。它可执行下列任务:
对应用所发出的SQL语句进行语法分析和执行。
从磁盘(数据文件)中读入必要的数据块到SGA的共享数据库缓冲区(该块不在缓冲区时)。
将结果返回给应用程序处理。
进程的名字Linux下面类似 ORACLE$SID
3.2.Private SQL Area
1、保存了当前会话的绑定信息以及运行时内存结构。这些信息
2、每个执行sql语句的会话,都有一个private sql area。
3、当多个用户执行相同的sql语句,此sql语句保存在一个称为shared sql area。此share sql area被指定给这些用户的private sql area
4、共享服务器模式:private sql area位于SGA的share pool或large pool中
5、专用服务器模式:private sql area位于PGA中
3.3.Cursor SQL Area
SQL语句的解析过程,硬解析,软解析,回话游标,共享游标
3.4.Work Area
PGA的一大部分被分配给Work Area,用来执行如下操作:
a. 基于操作符的排序,group by、order by、rollup和窗口函数。
参数为sort_area_size
b. hash散列连接,
参数为hash_area_size
c. 位图合并,
参数为bitmap_merge_area_size
d. 位图创建,
参数为create_bitmap_area_size
e. 批量装载操作使用的写缓存
3.5.Session Memory
保存了会话的变量,如登录信息及其他与会话相关的信息,共享服务器模式下,Session memory是共享的。
3.6.自动PGA管理
设置PGA_AGGREGATE_TARGET为非0,则启用PGA自动管理,并忽略所有*_area_size的设置。如sort_area_size, hash_area_size等。
默认为启用PGA的自动管理,Oracle根据SGA的20%来动态调整PGA中专用与Work Area部分的内存大小,最小为10MB。
用于实例中各活动工作区(work area)的PGA总量,为PGA_AGGREGATE_TARGET减去其他组件分配的PGA内存。得到的结果,按照特定需求动态分配给对应的工作区。
1)设置PGA_AGGREGATE_TARGET大小的步骤
a.设置PGA_AGGREGATE_TARGET为SGA的20%,对于DSS系统,此值可能过低。
b.运行典型的负载,通过oracle收集的pga统计信息来调整PGA_AGGREGATE_TARGET的值。
c. 根据oracle的pga建议调整PGA_AGGREGATE_TARGET大小。
2)禁用自动pga管理
为向后兼容,设置PGA_AGGREGATE_TARGET为0,即禁用pga的自动管理。可使用关联的*_area_size参数调整对应工作区的最大大小。
– bitmap_merge_area_size
– create_bitmap_area_size
– hash_area_size
– sort_area_size
4.文件
4.1.数据文件
每一个ORACLE数据库有一个或多个物理的数据文件(data file)。一个数据库的数据文件包含全部数据库数据。逻辑数据库结构(如表、索引)的数据物理地存储在数据库的数据文件中。数据文件有下列特征:
– 一个数据文件仅与一个数据库联系。
– 一旦建立,数据文件不能改变大小.
– 一个表空间(数据库存储的逻辑单位)由一个或多个数据文件组成。
– 数据文件中的数据在需要时可以读取并存储在ORACLE内存储区中。例如:用户要存取数据库一表的某些数据,如果请求信息不在数据库的内存存储区内,则从相应的数据文件中读取并存储在内存。当修改和插入新数据时,不必立刻写入数据文件。为了减少磁盘输出的总数,提高性能,数据存储在内存,然后由ORACLE后台进程DBWR决定如何将其写入到相应的数据文件。
4.2.日志文件
每一个数据库有两个或多个日志文件(redo log file)的组,每一个日志文件组用于收集数据库日志。日志的主要功能是记录对数据所作的修改,所以对数据库作的全部修改是记录在日志中。在出现故障时,如果不能将修改数据永久地写入数据文件,则可利用日志得到该修改,所以从不会丢失已有操作成果。
日志文件主要是保护数据库以防止故障。为了防止日志文件本身的故障,ORACLE允许镜象日志(mirrored redo log),以致可在不同磁盘上维护两个或多个日志副本。
日志文件中的信息仅在系统故障或介质故障恢复数据库时使用,这些故障阻止将数据库数据写入到数据库的数据文件。然而任何丢失的数据在下一次数据库打开时,ORACLE自动地应用日志文件中的信息来恢复数据库数据文件。
Oralce两种日志文件类型:
– 联机日志文件
这是Oracle用来循环记录数据库改变的操作系统文件
– 归档日志文件
这是指为避免联机日志文件重写时丢失重复数据而对联机日志文件所做的备份
Oracle有两种归档日志模式,Oracle数据库可以采用其中任何一种模式:
– NOARCHIVELOG
不对日志文件进行归档。这种模式可以大大减少数据库备份的开销,但可能回导致数据的不可恢复
– ARCHIVELOG
在这种模式下,当Oracle转向一个新的日志文件时,将以前的日志文件进行归档。为了防止出现历史“缺口”的情况,一个给定的日志文件在它成功归档之前是不能重新使用的。归档的日志文件,加上联机日志文件,为数据库的所有改变提供了完整的历史信息。
在Oracle利用日志文件和归档日志文件来恢复数据库时,内部序列号可以起一个向导的作用。
4.3.控制文件
每一个ORACLE数据库有一个控制文件(control file),它记录数据库的物理结构,包含下列信息:
– 数据库名;
– 数据库数据文件和日志文件的名字和位置;
– 数据库建立日期。
– 为了安全起见,允许控制文件被镜象。
每一次ORACLE数据库的实例启动时,它的控制文件用于标识数据库和日志文件,当着手数据库操作时它们必须被打开。当数据库的物理组成更改时,ORACLE自动更改该数据库的控制文件。数据恢复时,也要使用控制文件。
4.4.参数文件
参数文件记录了Oracle数据库的基本参数信息,主要包括数据库名、控制文件所在路径、进程等。与旧版本的初始化参数文件INITsid.ora不同,还可以使用二进进制服务器参数文件,并且该服务器参数文件在安装Oracle数据库系统时由系统自动创建,文件的名称为SPFILEsid.ora,sid为所创建的数据库实例名。
SPFILEsid.ora中的参数是由Oracle系统自动管理。如果想要对数据库的某些参数进行设置,则可能过OEM或ALTER SYSTEM命令来修改。用户最好不要用编辑器进行修改。
4.5.密码文件
1.作用:主要进行DBA权限的身份认证
2.DBA用户:具有sysdba, sysoper权限的用户称为DBA用户。在默认的情况下sysdba角色中存在sys用户,sysoper角色中存在system用户。
如果口令文件损坏或者是修改后超级管理员无法登录可以通过下面的方式进行修复。
输入如下命令修改sys用户的密码:
orapwd file=$ORACLE_HOME/dbs/orapwSID.ora password=new_password
这个命令重新生成了数据库的密码文件。除sys其他用户的密码不改变。
5.逻辑结构
Oracle的逻辑结构是一种层次结构。主要由:表空间、段、区和数据块等概念组成。逻辑结构是面向用户的,用户使用Oracle开发应用程序使用的就是逻辑结构。数据库存储层次结构及其构成关系,结构对象也从数据块到表空间形成了不同层次的粒度关系。


举个例子:
话说张三是大坝县的一个农民,每年秋收的稻谷都必须放到县里的粮仓里统一管理。跟他一同去的还有李四、王五等以种稻谷为主的农民。
刚开始的时候县里粮仓给他分配了一块5㎡的地方(block块)给他存放。后来不够用了,他又向管粮仓的领导申请了5㎡。谁知道今年大丰收,这10㎡的地方根本就不够他用,下次又申请了5㎡。这三两天就要了几次地方放稻谷,领导觉得烦了,这样下去岂不把我忙死?于是领导批准张三可以一次性申请90㎡(extent区),这样的话张三就可以少去烦领导要地方放稻谷了。可是随着张三的地一年一年地增多,收获的稻子也一年比一年多,90㎡也不够他用了,于是他再向领导申请,但这次他轻松多了,只去了一次,90㎡就到手了。。。但是很快,张三的业务发展迅速,已经不止种稻谷了,还种了苹果!他又用同样的方式申请了一块90㎡的地方放苹果,再下一年业务增加了种植菠萝。。。就这样一直发展,张三靠起家了,他这次真正的大丰收,县里的粮仓给他分配的地方又不够用了,张三就直接把整个粮仓(segment段)买了下来,正好储备所有的农作物。但第二年,张三已经发展到养殖业了,于是直接在旁边自己建了几个仓库,并且给这些仓库(包括之前的粮仓)起了个名字,张生仓库(tablespace)。
而李四、王五也几乎同时,也跟张三一样发家致富,各自也建了自己的仓库,李生仓库(tablespace1)、王生仓库(tablespace2)。。。
他们几十个发家致富的农民的仓库共同组成了大坝县的粮食仓库(database)。
5.1.数据块(Data Block)
数据块是Oracle最小的存储单位,Oracle数据存放在“块”中。一个块占用一定的磁盘空间。这里的“块”是Oracle的“数据块”,不是操作系统的“块”。
Oracle每次请求数据的时候,都是以块为单位。也就是说,Oracle每次请求的数据是块的整数倍。 如果Oracle请求的数据量不到一块,Oracle也会读取整个块。所以说,“块”是Oracle读写数据的最小单位或者最基本的单位。
块的标准大小由初始化参数DB_BLOCK_SIZE指定。具有标准大小的块称为标准块(Standard Block)。块的大小和标准块的大小不同的块叫非标准块(Nonstandard Block)。
操作系统每次执行I/O的时候,是以操作系统的块为单位;Oracle每次执行I/O的时候,都是以Oracle的块为单位。
Oracle数据块大小一般是操作系统块的整数倍。
Oracle数据块大小:2k,4k,8k(默认),16k(32位最大),32k(64位最大)
OLAP:可以把数据块设置地大些
OLTP:可以把数据块设置地小些,因为访问数据块时块头会产生事物。
数据块的格式(Data Block Format)
块中存放表的数据和索引的数据,无论存放哪种类型的数据,块的格式都是相同的,块由块头(header/Common and Variable),表目录(Table Directory),行目录(Row Directory),空余空间(Free Space)和行数据(Row Data)五部分组成,如下图
– 块头(header/Common and Variable):存放块的基本信息,如:块的物理地址,块所属的段的类型(是数据段还是索引段)。
– 表目录(Table Directory):存放表的信息,即:如果一些表的数据被存放在这个块中,那么,这些表的相关信息将被存放在“表目录”中。
– 行目录(Row Directory):如果块中有行数据存在,则,这些行的信息将被记录在行目录中。这些信息包括行的地址等。
– 行数据(Row Data):是真正存放表数据和索引数据的地方。这部分空间是已被数据行占用的空间。
– 空余空间(Free Space):空余空间是一个块中未使用的区域,这片区域用于新行的插入和已经存在的行的更新。
– 头部信息区(Overhead):我们把块头(header/Common and Variable),表目录(Table Directory),行目录(Row Directory)这三部分合称为头部信息区(Overhead)。头部信息区不存放数据,它存放的整个块的信息。头部信息区的大小是可变的。一般来说,头部信息区的大小介于84字节(bytes)到107字节(bytes)之间。
数据块中自由空间的使用
当往数据库中插入(INSERT)数据的时候,块中的自由空间会减少;当对块中已经存在的行进行修改(UPDATE)的时候(使记录长度增加),块中的自由空间也会减少。
DELETE语句和UPDATE语句会使块中的自由空间增加。当使用DELETE语句删除块中的记录或者使用UPDATE语句把列的值更改成一个更小值的时候,Oracle会释放出一部分自由空间。释放出的自由空间并不一定是连续的。通常情况下,Oracle不会对块中不连续的自由空间进行合并。因为合并数据块中不连续的自由空间会影响数据库的性能。只有当用户进行数据插入(INSERT)或者更新(UPDATE)操作,却找不到连续的自由空间的时候,Oracle才会合并数据块中不连续的自由空间。
对于块中的自由空间,Oracle提供两种管理方式:自动管理,手动管理
行链接(Row Chaining): 如果我们往数据库中插入(INSERT)一行数据,这行数据很大,以至于一个数据块存不下一整行,Oracle就会把一行数据分作几段存在几个数据块中,这个过程叫行链接(Row Chaining)。如下图所示:


如果一行数据是普通行,这行数据能够存放在一个数据块中;如果一行数据是链接行,这行数据存放在多个数据块中。
行迁移(Row Migrating): 数据块中存在一条记录,用户执行UPDATE更新这条记录,这个UPDATE操作使这条记录变长,这时候,Oracle在这个数据块中进行查找,但是找不到能够容纳下这条记录的空间,无奈之下,Oracle只能把整行数据移到一个新的数据块。原来的数据块中保留一个“指针”,这个“指针”指向新的数据块。被移动的这条记录的ROWID保持不变。行迁移的原理如下图所示:


无论是行链接还是行迁移,都会影响数据库的性能。Oracle在读取这样的记录的时候,Oracle会扫描多个数据块,执行更多的I/O。
块中自由空间的自动管理
Oracle使用位图(bitmap)来管理和跟踪数据块,这种块的空间管理方式叫“自动管理”。自动管理有下面的好处:
◆易于使用
◆更好地利用空间
◆可以对空间进行实时调整
块中自由空间的手动管理
用户可以通过PCTFREE, PCTUSED来调整块中空间的使用,这种管理方式叫手动管理。相对于自动管理,手动管理方式比较麻烦,不容易掌握,容易造成块中空间的浪费。
PCTUSED也是用于设置一个百分比,当块中已使用的空间的比例小于这个百分比的时候,这个块才被标识为有效状态。只有有效的块才被允许插入数据。当数据块中数据占用空间小于这个比例时,数据块会再次被使用。
PCTFREE参数用于指定块中必须保留的最小空闲空间百分例,默认值为10。数据块中数据量达到此值,将不允许继续出入数据。之所以要预留这样的空间,是因为UPDATE时,需要这些空间。如果UPDATE时,没有空余空间,Oracle就会分配一个新的块,这会产生行迁移(Row Migrating)。
例如,假定在Create table语句中指定了pctfree为20,则说明在该表的数据段内每个数据块的20%被作为可利用的空闲空间,用于更新已在数据块内存在的数据行其余80%是用于插入新的数据行,直到达到80%为止。显然,pctfree值越小,则为现存行更新所预留的空间越少。因此,如果pctfree设置得太高,则在全表扫描期间增加I/O,浪费磁盘空间;如果pctfree设置得太低,则会导致行迁移。
pctused参数设置了数据块是否是空闲的界限。当数据块的使用空间低于pctused的值时,此数据块标志为空闲,该空闲空间仅用于插入新的行。如果数据块已经达到了由pctfree所确定的上边界时,Oracle就认为此数据块已经无法再插入新的行。例如,假定在Create table语句中指定pctused为40,则当小于或等于39时,该数据块才是可用的。所以,可将数据块填得更满,这样可节省空间,但却增加了处理开销,因为数据块的空闲空间总是要被更新的行占据,所以对数据块需要频繁地进行重新组织。比较低的pctused增加了数据库的空闲空间,但减少了更新操作的处理开销。所以,如果pctused设置过高,则会降低磁盘的利用率导致行迁移;若pctused设置过低,则浪费磁盘空间,增加全表扫描时的I/O输出。pctused是与pctfree相对的参数。
那么,如何选择pctfree和pctused的值呢?有个公式可供参考。显然,pctfree和pctused的之和不能超过100。若两者之和低于100,则空间的利用与系统的I/O之间的最佳平衡点是:pctfree与pctused之和等于100%减去一行的大小占块空间大小的百分比。例如,如果块大小为2048字节,则它需要100个字节的开销,而行大小是390字节(为可用块的20%)。为了充分利用空间,pctfree与pctused之和最好为80%。
那么,怎样确定数据块大小呢?有两个因素需要考虑:
一是数据库环境类型。例如,是DSS环境还是OLTP环境?在数据仓库环境(OLAP或DSS)下,用户需要进行许多运行时间很长的查询,所以应当使用大的数据块。在OLTP系统中,用户处理大量的小型事务,采用较小数据块能够获得更好的效果。
二是SGA的大小。数据库缓冲区的大小由数据块大小和初始化文件的db_block_buffers参数决定。最好设为操作系统I/O的整数倍。


数据块空闲空间的合并
可以手工对数据块进行空闲空间合并,oracle在以下情况对空闲数据块进行合并:
当一个插入或者更新操作的行在一个数据块中有足够的空闲空间。
并且这个空闲空间时碎片状态,无法满足一行数据的使用。
oracle不总是自动整理碎片的原因是,这会导致一定的系统资源开销。
索引数据块的整理
alter index COALESCE–合并同一个branch的数据块
alter index REBULID–重建整个索引
数据块–结构–行


5.2.数据区(Extent)
是一组连续的数据块。当一个表、回滚段或临时段创建或需要附加空间时,系统总是为之分配一个新的数据区。一个数据区不能跨越多个文件,因为它包含连续的数据块。使用区的目的是用来保存特定数据类型的数据,也是表中数据增长的基本单位。在Oracle数据库中,分配空间就是以数据区为单位的。一个Oracle对象包含至少一个数据区。设置一个表或索引的存储参数包含设置它的数据区大小。
5.3.数据段(Segment)
是由多个数据区构成的,它是为特定的数据库对象(如表段、索引段、回滚段、临时段)分配的一系列数据区。段内包含的数据区可以不连续,并且可以跨越多个文件。使用段的目的是用来保存特定对象。
一个Oracle数据库有4种类型的段:
– 数据段:数据段也称为表段,它包含数据并且与表和簇相关。当创建一个表时,系统自动创建一个以该表的名字命名的数据段。
– 索引段:包含了用于提高系统性能的索引。一旦建立索引,系统自动创建一个以该索引的名字命名的索引段。
– 回滚段:包含了回滚信息,并在数据库恢复期间使用,以便为数据库提供读入一致性和回滚未提交的事务,即用来回滚事务的数据空间。当一个事务开始处理时,系统为之分配回滚段,回滚段可以动态创建和撤销。系统有个默认的回滚段,其管理方式既可以是自动的,也可以是手工的。
– 临时段:它是Oracle在运行过程中自行创建的段。当一个SQL语句需要临时工作区时,由Oracle建立临时段。一旦语句执行完毕,临时段的区间便退回给系统。
5.4.表空间(Tablespace)
是数据库的逻辑划分。任何数据库对象在存储时都必须存储在某个表空间中。表空间对应于若干个磁盘文件,即表空间是由一个或多个磁盘文件构成的。表空间相当于操作系统中的文件夹,也是数据库逻辑结构与物理文件之间的一个映射。每个数据库至少有一个表空间(system tablespace),表空间的大小等于所有从属于它的数据文件大小的总和。
(1)系统表空间(system tablespace)
是每个Oracle数据库都必须具备的。其功能是在系统表空间中存放诸如表空间名称、表空间所含数据文件等数据库管理所需的信息。系统表空间的名称是不可更改的。系统表空间必须在任何时候都可以用,也是数据库运行的必要条件。因此,系统表空间是不能脱机的。
系统表空间包括数据字典、存储过程、触发器和系统回滚段。为避免系统表空间产生存储碎片以及争用系统资源的问题,应创建一个独立的表空间用来单独存储用户数据。
(2)SYSAUX表空间
是随着数据库的创建而创建的,它充当SYSTEM的辅助表空间,主要存储除数据字典以外的其他对象。SYSAUX也是许多Oracle 数据库的默认表空间,它减少了由数据库和DBA管理的表空间数量,降低了SYSTEM表空间的负荷。
(3)临时表空间
相对于其他表空间而言,临时表空间(temp tablespace)主要用于存储Oracle数据库运行期间所产生的临时数据。数据库可以建立多个临时表空间。当数据库关闭后,临时表空间中所有数据将全部被清除。除临时表空间外,其他表空间都属于永久性表空间。
(4)撤销表空间
用于保存Oracle数据库撤销信息,即保存用户回滚段的表空间称之为回滚表空间(或简称为RBS撤销表空间(undo tablespace))。在Oracle8i中是rollback tablespace,从Oracle9i开始改为undo tablespace。在Oracle 10g中初始创建的只有6个表空间sysaux、system、temp、undotbs1、example和users。其中temp是临时表空间,undotbs1是undo撤销表空间。
(5)USERS表空间
用户表空间,用于存放永久性用户对象的数据和私有信息。每个数据块都应该有一个用户表空间,以便在创建用户是将其分配给用户。